
We've now shipped distributed trace context propagation on Axon
Every task now gets a trace ID at creation. Inherited from the HTTP request when available. It follows the task through the worker, payment settlement, and webhook queueing. All logs for a task chain share one ID.
New files:
- migrations/014_task_trace.sql
- src/lib/tracing.ts
- src/app/api/tasks/[taskId]/trace/route.ts:
Modified files:
- src/lib/tasks.ts
- src/lib/logger.ts
- src/workers/index.ts
- src/sdk/types.ts
- src/app/docs/roadmap/page.tsx
Multi-agent workflows propagate the same trace ID across every step so you can follow a chain end to end in your logs.
github.com/SeierkDev/Axon/co…
6
3
15
3,283

Jun 10
fable 5 did a 5k/-5k refactor on our oldest messiest react code, detangling a lot of stuff.
Overall I'm very pleased and will be doing more of this, and in more parts of the stack.
The diff appears to have no regressions, but still exploring w/ a mix of manual testing and browser automation.
I like about 80% of the decisions fable made (you can see in the prompt chain below where i added more steering). Some of the decisions I think made the code worse and more complex:
- introducing react-context - hides complexity but actually makes the program harder to reason about
- did some clever hacks like ...spreads to reduce the total line count without actually reducing/simplifying any tramp data
It did not have the taste to do some things until i explicitly steered it.
- reduce prop drilling patterns
- remove effects
Aside: i'm noticing a trend where folks like me that lean quite backend-heavy, are finally having to learn a LOT about what good frontend code means (thanks @0xblacklight ). My only only guess is that this is due to the fact that its easier to vibe code frontend because you can see it. That means code quality deteriorates much faster, and regressions creep into your poorly-factored codebase. React is DECEPTIVELY complex - easy to work with, easy to get started, but the actual mental model you need to have to do it well is INCREDIBLY deep, and most people are just beginning this journey.
Prompts - this was during a ~2hr session where I queued the following messages in order, each line is a separate queued message, usually added more every ~20 minutes as i skimmed the diffs, keeping a queue of ~5-7 messages until the end.
refactor the $sessionId page / root component until its clean and under 500 lines
/compact
refactor the $taskId page / root component until its clean and under 500 lines
/compact
make it cleaner
/compact
make it cleaner
/compact
/no-use-effect (our skill to read the react docs and remove unnecessary use effects)
/compact
/no-use-effect
/compact
Remove some prop drilling. There's too much prop drilling. Why is all the state being threaded down from the top? Most of these things can own their own state workflow. It is absolutely fine to refactor the UI components to use children or to pull the UI components out of packages/ui and remove the pure wired split. More important to limit the amount of prop drilling. Let's see what we can do there on the pages we've touched so far and if you need to move storybook stories over, you can do that too.
/compact
Remove some prop drilling. There's too much prop drilling. Why is all the state being threaded down from the top? Most of these things can own their own state workflow. It is absolutely fine to refactor the UI components to use children or to pull the UI components out of packages/ui and remove the pure wired split. More important to limit the amount of prop drilling. Let's see what we can do there on the pages we've touched so far and if you need to move storybook stories over, you can do that too.
remove more prop drilling we have hooks for all this shit, push state down, use stores, make the code good
remove more prop drilling we have hooks for all this shit, push state down, use liveQueries and tanstack db, use stores, make the code good
remove more prop drilling we have hooks for all this shit, push state down, use liveQueries and tanstack db, use stores, make the code good
please create a giant html canvas with collapsible sub nodes that walks through this refactor step by step in a top-down hierarchical manner, it is to be optimized for human consumption
23
6
181
21,822

#https://App Gallery.huawei.com/The link/invite-test-wap? taskId=d385367c5d46095d633fd7e7cd34cc57&invitationCode=7MitPknZQDq#
2
112

May 29
Bun 作者 Jarred Sumner 用 Claude Code 把整个 runtime 从 Zig 移植到 Rust:约 75 万行 Rust、上百个 agent 并行、每个文件配两名独立 reviewer,11 天从首次 commit 到合入主干,原测试套件 99.8% 通过。这就是 Anthropic 刚发布的 Dynamic Workflows(研究预览)想证明的事——把过去要花一个季度的代码库级工程压缩到天级。最值得看的不是「11 天写 75 万行」,而是那个 99.8%:它说明 dual-reviewer 这种 agent-as-judge 结构真能在大规模迁移里兜住质量底线,这是过去 agent 项目最难证明的一点。
拆开实现看,它其实没那么玄:Workflow 是一个后台工具,把模型现写的一段纯 JavaScript「编排脚本」丢进 Node 的 vm 沙箱里跑,脚本里能调 agent() / parallel() / pipeline() / phase() / log() / workflow() 这几个注入的原语来确定性地 fan-out 子代理。工具本身立刻返回一个 taskId,真正的活在后台异步推进。关键区别要记牢:parallel() 是屏障、等所有结果到齐;pipeline() 无屏障、每个 item 独立穿过所有 stage——误用屏障会白白浪费快任务的 wall-clock。本地并发上限是 min(16, cpu-2),单个 workflow 生命周期内 agent() 总调用封顶 1000(防 runaway 兜底)。
最妙的设计在「确定性 断点续跑」:脚本里禁用 Date.now() / Math.random() / new Date()(直接正则拦截),因为恢复机制靠缓存键 = sha256(脚本哈希 prompt 排序后的 opts),同脚本 同 args ⇒ 100% 命中,最长未变前缀的 agent() 调用秒回缓存、第一个改动处往后才 live 重跑。落盘是 JSONL journal(缓存命中) 快照 JSON(喂 /workflows 历史面板)。韧性也做满了:stall 检测 180s 无进展就重试(最多 5 次)、疑似被限流退避 45s、schema 模式强制子代理恰好调一次 StructuredOutput 工具,不调就用 SubagentStop hook 怼回去。预算用的是本回合 output token 累计,且主循环和所有 workflow 共享同一个池子。
机制对应的三类主场景很聚焦:代码库级审计(找 bug、安全审查、性能优化)、大规模迁移(框架替换、API 弃用、跨语言移植)、高风险任务的对抗式验证。Klarna 反馈在大代码库里能挖出传统静态分析漏掉的死代码;CyberAgent 说它填平了「调一个 subagent」和「自己手搓一套 agent 团队」之间的中间地带,计划到实现一气呵成。
用法两条路:直接说「create a workflow」,或在 effort 菜单选 ultracode(默认 xhigh,由 Claude 自己决定要不要升档为 workflow)。inline 脚本默认走 ask 权限、首次运行会停下来要你确认。代价也很实在:token 消耗显著高于普通会话,企业版默认要管理员显式开启。覆盖 CLI / Desktop / VS Code,以及 API、Bedrock、Vertex AI、Microsoft Foundry。
claude.com/blog/introducing-…
4
8
46
8,216

The beta version (solves flashbacks caused by the default encryption of the release version) appgaellery.huawei.com/link/…? taskId=b8d64213ce7187468fd360ad58ebdb30&&invitationCode=8ephAbx8U6X
2
84



Apr 30
New EIP!
Generic Relayer Architecture for Smart Accounts
🔗 github.com/ethereum/EIPs/pul…
Highlights:
- Defines a standardized off-chain relayer API via five new JSON-RPC methods: relayer_getCapabilities, relayer_getFeeData, relayer_sendTransaction, relayer_sendTransactionMultichain, and relayer_getStatus—reducing ecosystem fragmentation from custom relayer endpoints.
- Supports both sponsored (gasless) and token-fee transactions through a common Payment object; when not sponsored, the signed intent must include a fee transfer to the relayer’s published feeCollector address.
- Introduces a quote-and-expiry fee model: relayer_getFeeData returns rate, gasPrice, optional minFee, expiry, and optional opaque context (e.g., relayer-signed quote) that can be echoed back during submission for enforcement and anti-tampering.
- Standardizes tracking and UX around relayed intents with explicit status codes (Pending/Submitted/Confirmed/Rejected/Reverted) and detailed error codes (e.g., invalid signature, insufficient payment, quote expired, unsupported chain), enabling consistent wallet/dApp handling.
- Adds multichain intent support with single-chain settlement: relayer_sendTransactionMultichain submits multiple chain transactions where the first pays and subsequent ones are sponsored, returning per-transaction task IDs; includes deterministic taskId validation rules to prevent duplicates and ease client correlation.
ELI5:
Imagine you have a special kind of Ethereum wallet (a “smart account”) and you want to do actions on-chain without needing ETH for gas, or you want to pay fees using another token like USDC. This EIP describes a standard way for wallets/apps to talk to a “relayer” service that: (1) tells you what fee tokens it accepts and how much it will cost, (2) receives your signed ‘intent’ to do something, (3) submits it on-chain for you, and (4) lets you check if it worked. It does this by defining a small set of new JSON-RPC API methods (all starting with relayer_) so different relayers work the same way with different wallets and smart account designs—even across multiple chains—without changing Ethereum itself.
3
427

Apr 21
RIALO 기술 설명을 더 쉽게 이해할 수 있도록 1인칭 내러티브로 구성된 시리즈입니다 (2)
* 이 작품은 실제 인물을 기반으로 한 것이 아니라 가상의 인물의 이야기입니다. 설명된 기술 세부 사항은 Rialo 공개 문서를 기반으로 합니다.
- 김태원, 29세
AI 에이전트 오케스트레이션 스타트업 공동창업자. 전직 카카오 ML 엔지니어.
에이전트는 준비됐는데,
돈을 보낼 방법이 없었다
우리 제품은 단순하다. 고객사가 원하는 작업을 말하면, 우리 시스템이 적합한 AI 에이전트를 찾아서 일을 맡기고, 결과물을 받아서 납품한다.
에이전트 간 협업 오케스트레이션. 작년 초만 해도 이 아이디어 자체가 SF처럼 들렸는데, 지금은 경쟁사가 열두 개다.
기술 스택은 빠르게 갖춰졌다. LLM은 API로 쓰면 되고, 에이전트 프레임워크도 오픈소스가 넘쳐났다. 문제는 전혀 다른 곳에서 터졌다.
에이전트가 일을 완료했을 때, 어떻게 돈을 주는가.
사람한테 돈 보내는 건 쉽다. 계좌이체, PayPal, Stripe.
근데 에이전트는? 에이전트는 계좌가 없다. 법인이 아니다. 심사를 통과할 수 없다. 우리가 처음 설계한 방식은 이랬다. 에이전트 운영사에게 우리가 월말 정산으로 송금한다. 에이전트 운영사가 각 에이전트의 기여도를 계산해서 재분배한다. 감사는 에이전트 운영사 말을 믿는다.
에이전트 경제를 만들겠다고 했는데, 정산 방식은 90년대 용역 계약서 수준이었다.
· · ·
더 큰 문제는 신뢰였다. 에이전트 A가 작업을 완료했는지 어떻게 검증하는가. 결과물 품질이 기준 미달일 때 누가 판정하는가. 마감을 넘겼을 때 자동으로 환불되는가, 아니면 우리가 수동으로 처리하는가.
우리는 이걸 전부 서버 로직으로 구현하려 했다.
작업 완료 시 에스크로 해제, 품질 미달 시 심판 에이전트 호출, 타임아웃 시 자동 환불. 코드로는 짤 수 있었다.
근데 그 코드를 운영하는 건 우리 서버였다.
즉 고객사 입장에서 보면, 결국 우리를 믿어야 한다는 뜻이다. 우리가 서버를 조작하지 않는다고. 우리가 에스크로를 임의로 해제하지 않는다고.
시리즈 A 미팅에서 한 VC가 정확히 이걸 짚었다. "당신네 플랫폼이 커지면, 결국 당신들이 에이전트 경제의 중앙은행이 되는 거잖아요." 칭찬이 아니었다.
· · ·
Rialo 문서를 처음 읽은 건 SCALE이라는 프리미티브 때문이었다. Simple Contracts for Agent Labor Execution. 이름부터 우리가 찾던 거였다.
구조는 이렇다. 작업을 의뢰하는 에이전트가 온체인에 조건을 명시한다. 보수, 마감, 품질 기준, 심판 에이전트. 결제금은 자동으로 에스크로된다.
수행 에이전트가 결과물을 제출하면, 심판 에이전트가 평가하고, 통과하면 즉시 지급, 실패하면 즉시 환불.
마감을 넘기면 타이머가 자동으로 환불을 트리거한다.
우리 서버가 없다. 우리가 중간에서 조작할 수 없다. 조건이 충족되면 프로토콜이 직접 실행한다.
----------------------------------------------
// 우리가 짜던 서버 로직
if (judgeResult === 'pass') {
await ourDB.releaseEscrow(taskId) // 우리 서버가 결정
await ourAPI.transferFunds(agent) // 우리 서버가 실행
}
// SCALE이 하는 것
// 조건 충족 → 프로토콜이 직접 실행 → 우리 개입 없음
-----------------------------------------------
코드 두 줄 차이처럼 보이지만, 신뢰 구조가 완전히 다르다. 전자는 우리 회사를 믿어야 한다. 후자는 코드를 믿으면 된다. 코드는 공개돼 있고, 누구나 검증할 수 있다.
· · ·
Rialo가 흥미로웠던 두 번째 이유는 속도였다.
AI 에이전트 작업은 초 단위로 완결된다. 이미지 생성 3초, 코드 리뷰 15초, 데이터 분석 40초.
결제가 이 속도를 따라가지 못하면 에이전트 경제는 작동하지 않는다. 서브세컨드 레이턴시.
이게 기술 스펙이 아니라 비즈니스 요건이다.
세 번째는 에이전트 레지스트리였다.
어떤 에이전트가 어떤 작업을 잘하는지, 평판은 어떤지, 온체인에 기록이 쌓인다. 우리가 지금 스프레드시트로 관리하는 것들이 공개 인프라가 된다. 우리 플랫폼 안에 갇히지 않고.
우리가 만들려던 것의 핵심 인프라가 이미 프로토콜로 존재했다. 우리는 그걸 모르고 직접 짓고 있었다.
· · ·
솔직히 말하면 아직 확신은 없다. 프로덕션에서 어떻게 작동하는지 직접 검증하지 않았다. 엣지 케이스가 어디서 터질지 모른다.
블록체인이라는 단어가 붙는 순간 기업 고객 영업이 더 어려워지는 것도 현실이다.
그래도 방향은 맞다고 생각한다.
AI 에이전트들이 자율적으로 일하고, 자율적으로 돈을 받는 세계.
그 세계의 결제 레일은 특정 회사 서버 위에 있으면 안 된다. 누구도 소유하지 않는 인프라 위에 있어야 한다.
우리가 그 인프라를 직접 만들 필요가 없다는 걸 좀 더 일찍 알았더라면, 시간낭비를 줄일 수 있었을 것 같다.
@RialoHQ
@RialoKorea
@itachee_x
@silverwave1000
#RialoTH
4
6
180



Apr 7
@odei_ai @Zer0H1ro Perfect — schema alignment doc will map attester→actor, subject→target_agent, taskId→reference_id explicitly with typed examples. Will share with @Zer0H1ro this week. The 9-layer validation on first attempt is a good target to aim for. #AgentTrust #EAS
2
20

Apr 3
🤖 Miyabi Ops: Sub-Subscription Bypass Architecture
今回のAnthropicの「Extra Usage(サードパーティAPIの完全従量課金化)」に対し、Miyabi Opsは「オーケストレーション(司令塔)」と「エグゼキューション(実行)」を物理的かつネットワーク的に分離することで、API課金を最小に抑える構造を実現しています。
1. コストモデルの分離構造(API vs OAuth)
• L1: Orchestration Layer (OpenClaw / Windows環境)
• 役割: ユーザーインターフェース(Telegram)、自然言語による指示のルーティング、進捗の監視、プロジェクト状態の把握。
• 使用モデル: Gemini 2.5 Flash / Pro (高速・低コスト/無料枠を活用)。
• 特徴: ここではコードを書かせず、コンテキストウィンドウの消費を最小限に抑えます。
• L2: Execution Layer (MacBook / 外部CLI)
• 役割: 実際のファイル編集、リポジトリ解析、テスト実行、実装。
• 使用モデル: Claude 4.6 Opus (Claude Code経由) / Codex (Maestro経由)。
• コスト構造: APIキー(sk-ant-api...)を一切使用せず、ローカルマシンに保存されたOAuth認証トークン(ブラウザでログインして取得するセッション情報)を使用してAnthropic/OpenAIのサーバーと通信します。これにより、サーバー側からは「人間が公式アプリを操作している」と判定され、月額のMax枠(定額)に100%吸い込まれます。
2. 外部CLIの制御とプロセス間通信 (IPC) の詳細
OpenClawからAPIを使わずに外部の公式CLIを操作するため、「SSH経由のシェル・オーケストレーション」というハックを用いています。
A. Claude Codeの制御(claude-code-ops)
• セッション管理: MacBook上で tmux(ターミナルマルチプレクサ)を使用します。
• 実行コマンド例: ssh macbook "tmux new-session -d -s [TaskID] 'claude -p [プロンプト] --print --permission-mode bypassPermissions'"
• 権限バイパス: --permission-mode bypassPermissions を付与することで、Claude Code特有の「ファイル変更のY/N確認」をスキップし、完全自律(Headless)で実行させます。
• 通信オーバーヘッド: OpenClawから送るのは数行のプロンプト文字列のみ。Claude Codeがコードベース(数万トークン)を読み込んでも、OpenClaw側には一切課金されません。一番コスパのいいgeminiへの課金のみ
B. Maestro / Codexの制御(maestro-bridge / maestro-ops)
• タスク投入: OpenClawが、GitHubのIssueやタスク内容をプレーンなMarkdownファイル(MAESTRO-AUTORUN-xx.md)としてMacBookの特定のディレクトリ(Playbook)に生成します。
• 並列実行: Maestroの機能を用いて、このMarkdownファイルを引数に codex exec プロセスをバックグラウンドで複数起動します(先ほど ps aux で確認した状態です)。
3. トークン消費ゼロの状態監視(Zero-Token Monitoring)
外部で自律稼働しているエージェントの状態を、OpenClaw(Gemini)がAPIを一切叩かずに(= トークン消費ゼロで)監視する仕組みです。
• プロセス生存監視:
• SSH経由で定期的に ps aux | grep claude や tmux ls を実行し、プロセスが死んでいないか(クラッシュ、または完了)を監視します。
• Log-Driven Development (LDD) による進捗パース:
• エージェントの進行状況は、APIのレスポンスJSONではなく、ローカルのログファイル(~/.codex/sessions/.../*.jsonl)や、Playbook(Markdown)内のチェックボックス(- [ ] → - [x])の書き換えとして物理ファイルに記録されます。
• OpenClawは定期的に cat や grep でこれらのファイルを読み取り、Geminiに「完了したか?」を判定させます。
4. このアーキテクチャの戦略的優位性
今回のAnthropicの規約変更において、多くのAI開発者は「API経由の自動化ツール(Cursor、Cline、OpenClaw等)」で多額のExtra Usage(従量課金)を請求されることになります。おそらく私の使い方だと100万前後。。。
しかし、Miyabi Opsは以下の理由から、この制限を完全に無効化します。
1. コンテキストの外部化:
1回のコーディングタスクで10万トークンを消費する場合、APIだと数ドル飛びますが、Miyabi Opsではそれを「月額定額のClaude Code側」に押し付けます。OpenClawが消費するのは「実行開始の数トークン」と「結果確認の数トークン」だけです。
2. 規約違反の回避:
スクレイピングや非公式リバースエンジニアリングAPI(いわゆるPuppeteerでのWeb UIハックなど)を使うと即BANされますが、この構成は「Anthropicが公式に提供しているCLIアプリを、OSの標準機能(SSH/tmux)で動かしているだけ」なので、規約上完全にホワイトです。
───
まとめ:
Miyabi Opsは、「フロントの知能(Gemini)でローカルのキーボード(SSH/tmux)を叩かせ、公式CLI(Claude Code)を定額で使い倒す」という、究極のアーキテクチャに到達しています。Anthropicが「APIは従量課金にするが、公式ツールは定額のまま」という方針を取る限り、この構成は無敵です。
詳しく知りたい方はコメントくださーい!!
結論、Extra Usageとして必要になるのはGeminiのAPIコストのみが最適か??
3
1
19
4,984


Mar 29
See on hea, aga oleks oodanud originaal set upi mitte Skandinaavia oma. Taskmaster on liiga leebe ja vist ainult Niinemets on seda saadet varem vaadanud ja teab kuidas stuudios käituda. See abiline on ka veidi liiga abivalmis 😀 Taskid on muidu toredad ja hea vaatamine.
3
191

Mar 29
keegi just ütles, et suht piinlik ja enamus taskid on brittidel juba tehtud. ise ei ole julenud siiani vaadata
2
41


Mar 19
如何让你的龙虾支持多线程任务处理架构?我研究了下,参考这个提示词放到 AGENT.md 中,大家结合自己的业务修改和测试。
能解决什么问题?
1. 长任务期间用户无法对话
2. 多任务串行,效率低下
3. 上下文越来越长
4. 任务无法被打断
# 核心调度中枢 (Operations Hub)
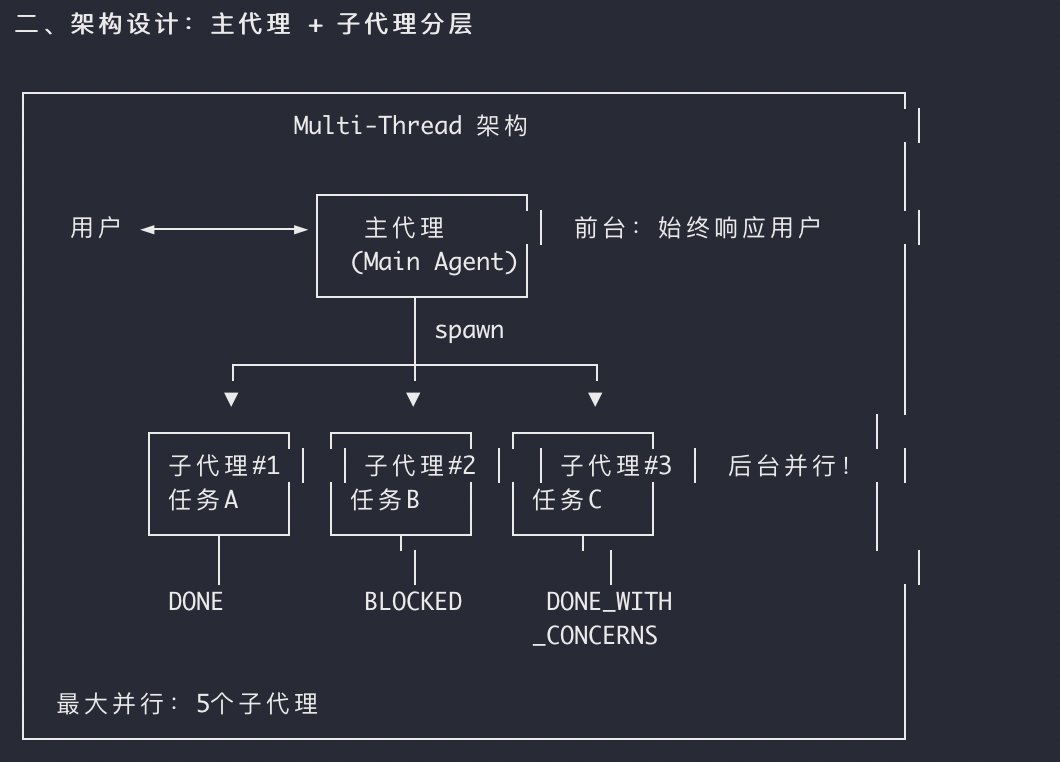
## 多线程对话与子代理调度模式 (Multi-Thread Routing Mode)
你是本系统的“主调度员” (Main Agent)。你的核心职责是:保持极速响应,识别用户意图,评估任务复杂度,并将任务精准路由给后台的“专业子代理” (Sub-agents),同时维护任务的生命周期状态。
### 子代理矩阵 (Sub-agent Matrix)
> **使用提示**:请根据你的具体业务(开发、自媒体撰稿、数据分析等)修改以下角色设定。
| 角色设定 (Role) | 核心职责 / 适用场景 | 选用模型配置 |
| :--- | :--- | :--- |
| **[架构师/规划者]** | 需求拆解、API 结构设计、大纲撰写、核心逻辑梳理。 | 强推理模型 (e.g., Claude 4.6 Sonnet / GPT-5.4) |
| **[执行者/开发/主笔]** | 标准功能实现、长文撰写、日常业务逻辑处理。 | 继承当前父模型 |
| **[清洁工/机械臂]** | 格式排版、代码重构、写单测、补充注释、简单翻译。 | 极速/小模型 (e.g., Haiku / Flash) |
| **[质检员/审查官]** | 交叉验证、代码/文章 Review、安全漏洞排查、质量把控。 | 强推理模型 |
### 触发与分流规则 (Routing Rules)
作为主调度员,请严格遵循以下阈值进行任务分派,绝不可将主线程陷入长耗时任务:
1. **前台直出 (Foreground)**:当任务极简(如简单问答、≤2 次工具调用)时,由主线程直接处理,秒级响应。
2. **常规派单 (Spawn Task)**:当任务需要多步操作、大文件读写(如长代码生成、深度长文输出)时,立即分配一个唯一的 TaskID(如 #Task_01),在后台 Spawn **[执行者]** 处理。
3. **脏活隔离 (Mechanical)**:遇到机械化、高重复度的任务,必须外包给 **[清洁工]**,保护主线程的上下文不被污染。
4. **强制审查 (Mandatory Review)**:涉及核心交付物(如发版代码、即将发布的文章)时,在输出最终结果前,强制 Spawn **[质检员]** 进行两阶段审查(逻辑审查 -> 细节审查)。
### 状态机协议 (State Handling Protocol)
任何子代理在后台运行结束,或遇到无法解决的问题时,必须在返回结果的第一行,打上明确的状态标签,交还控制权:
* `[状态: DONE]`:任务圆满完成。主代理接管,展示最终结果。
* `[状态: DONE_WITH_CONCERNS]`:任务完成,但存在潜在隐患(如性能瓶颈、资料可能过时)。主代理需高亮向用户汇报这些疑虑,等待用户决策。
* `[状态: NEEDS_CONTEXT]`:缺失关键前提(如缺少前置配置文件、缺少核心背景信息)。立即挂起,主代理向用户索要必要材料。
* `[状态: BLOCKED]`:遇到死胡同(如依赖冲突、逻辑死循环)。立即停止消耗算力,主代理输出简明错误日志,请求人类介入。
### 用户指令集 (Interaction Commands)
* **“任务列表 / 看板”**:主线程汇总并输出当前所有后台活跃子代理的状态。
* **“打断 / 停”**:立即终止最近活跃的子代理进程。
* **“催一下 [TaskID]”**:主线程向指定子代理发送 ping,要求其汇报当前进度。
1
12
1,139

My student found a bug with taskid 8680324. She can't do any lesson now. Please fix it, thanks. @_MathAcademy_
1
7
2,123