What you work on and who you work with are extremely important
"You can save a lot of time by picking the right area to work in. Picking the right people to work with is the next most important piece. Third comes how hard you work. They are like three legs of a stool. If you shortchange any one of them, the whole stool is going to fall. You can’t easily pick one over the other."
I started
@SkawrSearch with my college friend Saleh, and now we have a great team (10 talented people).
We originally wanted to build a simple marketplace app, and we thought that a better UX would help us succeed.
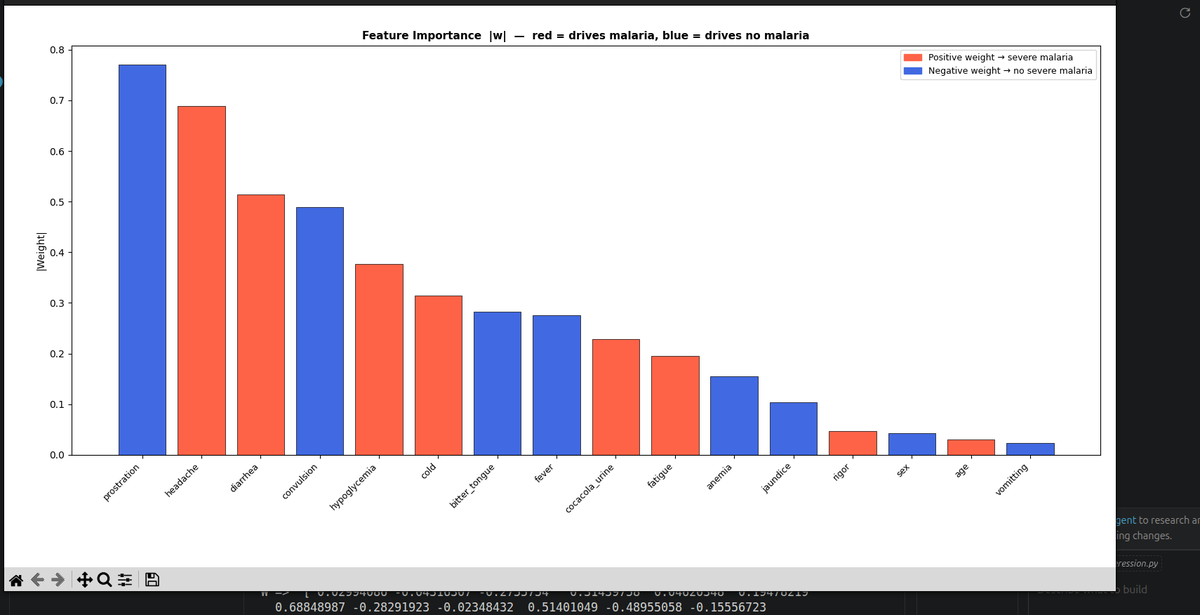
Search was identified as the main area of improvement.
Initially, we used Algolia in our app, and the results were promising, they had very cool features like synonyms and typo tolerance.
We started by trying to add layers on top of Algolia and it became really fun and addictive to experiment with different ways of doing search.
At some point, it became difficult to balance between search and all the other features.
The team was not big then, so ultimately we had to make a choice on what to make the biggest priority.
There are a lot of moving parts to building a good marketplace app, you don't have to just do search well, you need the messaging to be good, the bidding and offers, escrow and disputes, even logisitcs.
I built a heavy operational business back in 2014 (Jybly) and we had issues with scaling despite having very loyal customers.
We knew that whatever we did we wanted to go big with it, and anything less than global was going to be small for us.
So we thought about it for a while and ultimately made a huge decision.
We decided to make marketplaces better by building the search engine for all marketplaces.
This way, we make the experience better for all users not just those who use one single marketplace.
So we built
skawr.com, a search engine where users can search for products for free, we also did not want to take a commission from any transactions that would result from the search.
There are many reasons for this but the main reason is we don't want to be a partner for a few businesses we want to go really big with this and ultimately have all the products in the world on one search engine and commissions would affect this experience.
We would be incentivized to push users to buy even when not ready and the experience would be more annoying.
We have already eliminated all the people who just want to search for info and recipes and all of that by just focusing on products, so no need to make anything worse by pushing people to buy prematurely since they are all potential buyers.
If we do our job well, which is to match every user with the products that they want, they will ultimately buy when the time is right, but this process is different for everyone, and we want everyone to have an enjoyable experience.
To do that, we know that we need to invest more in customizing the experience for each individual, especially after the initial query, this is where the discrepancy between users really shows up.
Requerying and the system understanding what results you want to see next based on how you interact with the first few results shown is both an art and science, the best at this are the biggest social media platforms like Instagram, TikTok, and of course, my favourite X.
We need to invest a lot in the intersection between math, technology and psychology to deliver a great experience here.
We are not at that stage yet, but we really excited about the improvements we are introducing soon. We are confident that we will reach the top.
A big part of this confidence comes from the team that we have and the spirit but we are greedy and we want to recruit more talented people specially engineers.
But not any engineers, we want engineers who are naturally curious and know about about everything, sales, marketing, product, UX, psychology, mathematics... etc
If this fits you reach out.
Recently, we were discussing internally whether to use pricing as part of the embeddings in the vectorization process.
I am personally excited about the potential of this but our lead data scientist had a very interesting approach that is a lot more feasible.
So for the foreseeable future, we will not be going with this option, but I will keep thinking about better ways of doing it.
If these kind of challenges excites you then I think maybe we can be a good fit for you.
Also, if you are an e-commerce business and want to use our technology locally, not just have your products featured on our search engine, then that option is available right now.
But why not do both?
You have people finding out about your products organically on
skawr.com, and then you can also provide your users with a better search experience by using our SaaS technology for e-commerce at your own store.
We are also developing our web analytics tool so that it can work synergistically to help you improve the experience, identify gaps, and grow.
More products and services will come soon.
We see search and analytics as part of a bigger effort to improve CRO but not in a very tactical way.
Me and
@abdallah_963 will share our own framework for strategic CRO soon, it will also involve areas like branding and pricing as part of the pillars not just experiments with traffic and UI.
This is just the beginning and more to come inshallah.