

Claude community - hello - nice to see you all.
Would love to make some connections in having a hard time finding community here for real human feedback. So far it’s bots bots bots.
Anyone out there ? Opus is rating out all across workstreams today anyone seeing the same ? Should I emoji my messages up so people will reply ?
3
40

Anthropic quietly shipped something in Claude Code that changes how we think about AI coding agents.
It's called "agent teams."
Here's how it works: a team lead spawns multiple agents that share a task list and message each other directly. Not subagents reporting back to a manager. Actual peers collaborating.
In the demo, a QA agent reviewed the codebase, caught three bugs, then pinged the frontend and backend dev agents directly. They fixed the issues without any human intervention. First try. All three bugs resolved.
This is a fundamental shift from the "one agent, one task" model most of us have been using.
The old way: you spawn a subagent, it does its job, reports back to you, you decide what's next. Top-down. Sequential.
The new way: agents form a team, share context, negotiate priorities, and self-coordinate. They can do code review on each other's work. They can flag conflicts. They can split a complex task into parallel workstreams without you micromanaging.
Think about what this means for your workflow:
→ A planning agent designs the architecture → Two dev agents build features in parallel → A QA agent tests everything and sends bugs back to the right person → An integration agent merges the work
You describe the destination. The team figures out the route.
The real unlock here isn't speed — it's quality. When agents review each other's code, bugs get caught that a single agent would miss. Same reason human teams do code review.
We're watching AI development go from solo freelancers to actual teams. And the interesting question isn't whether this works — the demo proved it does.
The question is: what happens when you can spin up a 5-agent team for every task that used to take you 2 hours?
Are you still running agents solo, or have you started experimenting with multi-agent collaboration?

1
56

It took 5 coordinated workstreams:
▫️ PR placements
▫️ Content extraction across formats
▫️ Social distribution
▫️ Positioning alignment
▫️ Archive development
Our new case study breaks it down: input.global/5-steps-to-a-un…
1
43

/fanout is just speed. Write your independent workstreams. Assign tiers. Spawn them all at once instead of one after the other. Get one answer back. Runtime cut in half if your pieces don't depend on each other. That's the whole thing.

1
4

Some great and interesting things in there and most of them we are aware of as a wishlist. As I said in the interview it is less about ideas and what would be great to see, but more what is possible scope wise year on year which is why we have multiple timelines and workstreams. I hope I explained it well in the interview that coming up with concepts is good and important part in game development, but my biggest learning was when I started in game making as a designer, that then going from a concept in Balsamiq, Power Point, Illustrator and so on to the technical part of putting it in the game is where things become time intensive. Be it that you sometimes work on code that needs to be refactored/rewritten to make something possible, edge cases that need to be covered and so on. But I think and hope the next few years will show we are aware of the wishes and have some clear direction we want to go and also are looking into how to bring meaningful features and change to the mode.
2
1
11
558

20h
I'm curious to hear from people who use both Claude code and cowork heavily.
What do you use cowork for? how does it fit into your code workstreams?
1
42

Jun 15
It also feels lonely to not be able to talk to your cofounder about your workstreams
15

Jun 15
Unfortunate consequence of the deprecation of Fable 5: Workstreams you started with Fable in @claudeai Cowork are borked. Automatic fallback doesn't work, at least in my experience

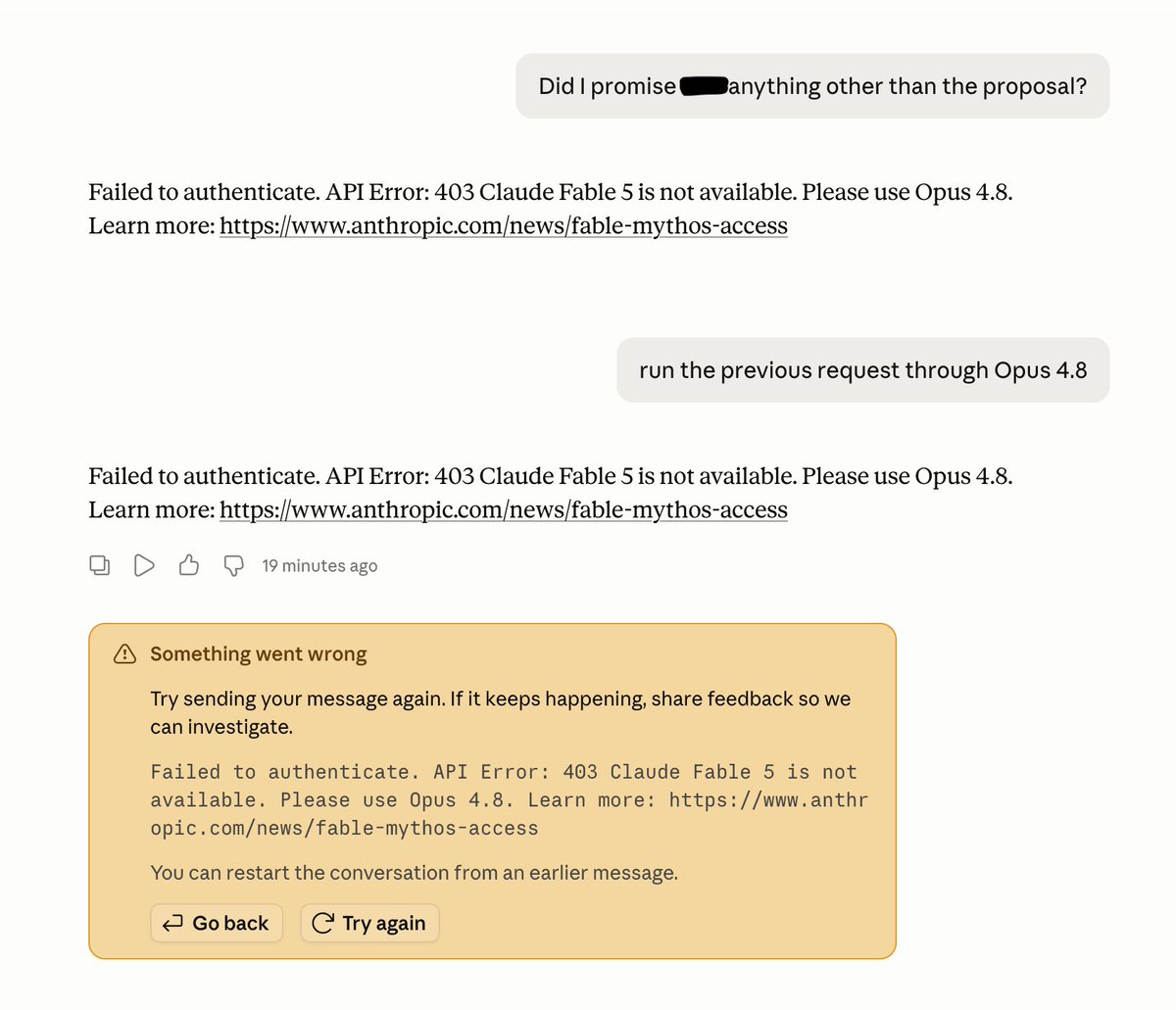
2
585

Jun 15
Codex, Legora, and Cognition have all iterated to the same thing. A list of workstreams on the left, agent orchestration on the right.
1
5
553

Bill 17 is now law in Québec — a key regulatory milestone for clean natural hydrogen.
For $QIMC, this supports regulatory de-risking while we continue active execution on multiple fronts: Québec drill-permitted targets, active Nova Scotia drilling, expanded soil sampling, deep geophysics, and seismic.
Multiple catalysts. Stronger technical foundation. Advancing toward scale.
Together, these workstreams advance our Québec–Nova Scotia clean natural hydrogen corridor strategy.
$QIMC $QIMCF #NaturalHydrogen #Hydrogen #CleanEnergy #Quebec #NovaScotia
8
34
572

Jun 15
building open infrastructure for AI agent coordination on Hedera and looking for enterprise sponsors who fund real workstreams. would love in on Boardy Pro
3
1
6
129

Jun 15
I used to spend hours every week on work that no one sees: Updating trackers. Filling spreadsheets. Collecting context before meetings. Scraping events. Preparing executive updates. Switching between tools just to answer one question - Important work.
But not necessarily high-leverage work. Over the past few months, I've been building agents into my daily workflow, and I estimate they've reduced my time spent on tedious tasks by more than 50%. My agent updates sheets automatically, keeps trackers in sync, scrapes relevant events, gather context across workstreams and before meetings with peers or executives, it prepares me with the information I need.
The interesting part? Almost all of this happens from WhatsApp. A message in, work out. No dashboards. No switching tabs. No copy-pasting across tools. The biggest shift wasn't automation, it was moving from being the operator to becoming the orchestrator.
Because AI agents aren't replacing work, they're changing where humans create value, less time collecting information - more time making decisions.
Less time updating systems - more time building relationships. I've been using @Base44 #Superagent to make this possible, and it made me realize something: The future of work may not be about learning dozens of new tools, it may be about teaching our agent how you work, and once it understands your workflows, you get something far more valuable than productivity:
You get your time back.

Your superagent has a voice now.
Simply talk to it, hands-free. It handles everything within your conversation.
You can even customize the voice to suit your preference.
39

Jun 15
That's a pretty comparable snapshot of token usage and agent delegation.
Fable just feels wired to do this better. It's a leader, where Opus is a worker.
Both these workstreams ran off the same Claude.md. One just does it better than the other. 🤷♂️
1
448

PMs already multitask.
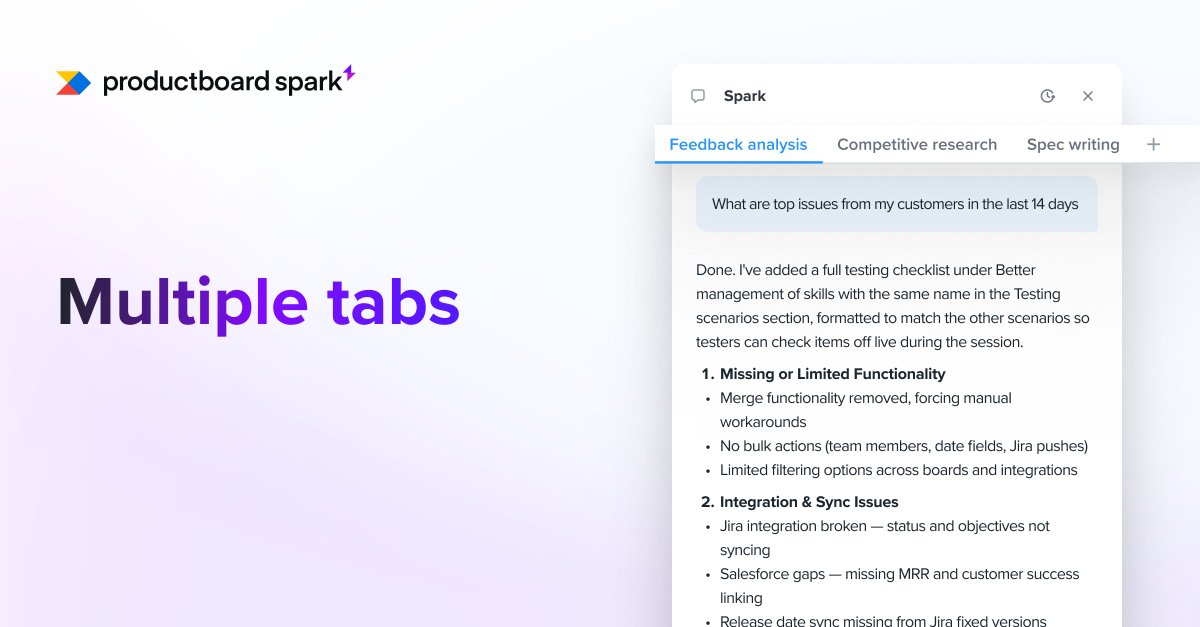
Now @productboard Spark can too.
We added multiple tabs in Spark chat so PMs can run separate AI workstreams in parallel:
competitor research
feedback analysis
spec writing
edge cases
GTM prep
outcome reviews
Each tab keeps its own context.
Instead of switching tools and rebuilding context, you switch between focused agents that already know what they’re working on.
Small feature. Big shift in PM leverage.
I had a lot of fun building this one.
1
17

Jun 15
🗓️ Weekly Focus – Phase #4 Portal Refinement, Mainnet Lite Validation & PyClaw
Phase #4 continues with Portal V1 as the primary focus, while Mainnet Lite validation and PyClaw development continue alongside it.
🔹 Phase #4 – Monitoring, Support & Stats
- Continue monitoring routing, miners, validators, dashboards, indexers, and L3 stats.
- Track stability as Portal V1, Mainnet Lite, and related Phase #4 workstreams continue to mature.
🔹 Portal V1 – Product Refinement
- Continue refining Portal V1 now that the core path is working (auth, API keys, usage visibility, gateway, router pools, hosted requests).
- Focus on usability, operational flow, reliability, and overall product readiness.
🔹 Portal V1 – Usage Metering Migration
- Begin shifting Portal usage accounting from request-count based tracking toward token-based usage (input, output, total tokens).
- Goal is fairer quotas, more accurate reporting, and a stronger foundation for future billing and plan controls.
🔹 Portal V1 – Gateway, Router Pool & Observability
- Continue hardening Gateway → router-pool behavior, request tracking, and operational visibility.
- Focus on reliability, observability, and hosted-path readiness under heavier usage.
🔹 Mainnet Lite – Baseline Validation
- Continue validating Mainnet Lite baseline components and supporting infrastructure.
- Main remaining check is deeper testing around the ephemeral-node network-task path.
🔹 Payment Staking – Regression & Hardening Tests
- Continue the regression pass following the recent security-hardening rollout.
- Goal remains validating the full staking/usage flow and confirming no regressions.
🔹 PyClaw – Dev Path Progress
- Continue PyClaw iteration across workflow, side packages, tools, and repository structure.
- Target remains a rough public development release next month so iteration can continue openly.
This week is about continuing to mature Portal V1, validating the remaining Mainnet Lite baseline paths, and preparing PyClaw for its first public development cycle.
#Cortensor #Testnet #Phase4 #AIInfra #DePIN #Portal #PyClaw #MainnetLite #L3

Jun 13

🗓️ Weekly Recap – Phase #4 Portal Progress, Mainnet Lite Validation & Infra Hardening
This week was again heavily focused on Portal V1, with meaningful progress across product flows, API Gateway behavior, observability, and hosted inference readiness.
🔹 Phase #4 – Monitoring, Support & Stats
- Continued monitoring across routing, miners, validators, dashboards, indexers, and L3 stats.
- Phase #4 remained stable while Portal and Mainnet Lite workstreams continued to mature.
🔹 Portal V1 – Product Flow Maturing
- Portal moved from rough MVP toward a more usable hosted product surface with cleaner auth, API keys, usage visibility, request logs, and UI/UX refinement.
- Data consistency between web app, database, and API-key systems improved significantly.
🔹 Portal V1 – API Gateway & Quota Work
- Sliding-window quota logic received deeper testing and fixes, including weekly-limit accounting improvements.
- Usage counting became more accurate with better separation between successful requests, quota events, and real failures.
🔹 Portal V1 – Request Visibility & Analytics
- Request visibility improved with better logs, filters, totals, and detailed request views.
- Added richer usage analytics including trends, activity heatmaps, and token-level visibility.
🔹 Portal V1 – Reliability, Observability & Operations
- Dual API Gateway setup is now operating behind a shared entry path, reducing single-point dependency.
- Admin/ops visibility expanded with metrics around gateway health, latency, routing distribution, and user activity.
🔹 Portal V1 – API Compatibility & Streaming
- OpenAI-style and Anthropic-style REST compatibility continued to improve.
- SSE/streaming MVP is now working, with deeper reliability work shifting toward backend/router behavior.
🔹 Portal V1 – Stress Testing & Router Pools
- Stress testing expanded using multiple accounts, keys, parallel requests, and longer-running workloads.
- This surfaced the next bottlenecks and drove further work on capacity-aware routing and router-pool behavior.
🔹 Mainnet Lite – Baseline Validation
- Mainnet Lite dedicated-node E2E was re-run successfully, including payment distribution behavior.
- Ephemeral-node network-task E2E also worked, confirming another critical baseline path.
🔹 RPC & Infrastructure Hardening
- Internal RPC infrastructure is now live across both testnet and mainnet-related environments.
- Early stability looks good and provides better operational control than previous external dependencies.
🔹 Payment Staking – Regression & Hardening
- Progress was lighter than planned while Portal took priority this week.
- Additional validation and regression testing remain on the upcoming work list.
🔹 PyClaw – Dev Path Progress
- Continued incremental progress on PyClaw workflows, tooling, and repository structure.
- Focus remains on preparing for the first public development release and open iteration cycle.
A productive Phase #4 week overall - Portal V1 made the largest jump forward, Mainnet Lite baseline checks continued to pass, and the hosted inference path is increasingly shifting from concept into an operational product.
#Cortensor #Testnet #Phase4 #AIInfra #DePIN #Portal #PyClaw #MainnetLite #L3

1
7
18
473


Jun 15
Elizabeth Hill’s maiden resource supports a compact open pit development scenario, capturing most known mineralisation within a defined footprint.
Combined with a granted Mining Lease, nearby infrastructure and ongoing drilling, the project is advancing toward development and economic study workstreams.
View the announcement: ow.ly/7sR150Z57YS
#WCE #ASX #Silver

3
11
495

Here is the skill for that:
---
name: parallel-goals-for-a-task
description: Convert a user's task request into a filled build brief, create a concrete top-level goal, split the work into independent parallel agent goals, and synthesize the results. Use when the user asks for Parallel goals for a task, asks to fill the build-task template, or asks Codex to solve a task with parallel goals or parallel agents.
---
# Parallel Goals For A Task
Use this skill to turn a raw user task into an actionable build brief and run the work through parallel goals.
## Filled Brief
Start by translating the user's request into this template. Replace every bracketed placeholder with relevant content from the request or conservative inferences from the current project context:
```text
Build [THING] in [TECH/FRAMEWORK]. It should include [MAIN FEATURES], with [INTERACTION/ANIMATION/BEHAVIOR DETAILS]. Make it feel [MOOD/QUALITY], using [VISUAL DETAILS], [ENVIRONMENT DETAILS], and [EXTRA EFFECTS]. Output as [FORMAT/FILE TYPE].
```
Do not leave bracketed placeholders in the filled version. If the task is not literally a visual build, adapt the fields to the nearest useful equivalents: thing, implementation environment, core deliverables, expected behavior, quality bar, surrounding constraints, helpful finishing touches, and output artifact.
Ask the user a question only when a missing detail makes the task impossible or risky to execute. Otherwise, infer the detail and keep moving.
## Goal Setup
Before dispatching work, define what done means for the task.
If a goal tool or `/goal` workflow is available, create a new top-level goal from the filled brief before starting. If the platform already has an active goal and cannot create another one, continue under the active goal and write the new objective into the working plan instead of blocking.
The top-level goal must include:
- The filled brief.
- Concrete finishing criteria.
- The expected final artifact or answer.
- Verification that should happen before reporting back.
## Parallel Dispatch
Split the work into independent pieces that can run concurrently. Use as many agents as genuinely helpful, but do not create extra agents for work that is faster or safer to do directly.
Good parallel workstreams include:
- Product or requirements clarification from existing context.
- Architecture, data model, or integration planning.
- UI or interaction design.
- Implementation of separate modules or files.
- Test, verification, and edge-case review.
- Copy, content, examples, or documentation.
Give each agent its own dedicated `/goal` in the task prompt. Keep each subgoal self-contained and non-overlapping where possible.
Use this shape for each agent prompt:
```text
/goal [ONE CLEAR SUBGOAL]
Context:
[Filled brief and relevant constraints.]
Deliverable:
[Specific output the main agent needs back.]
Boundaries:
[Files, modules, or decisions this agent owns. State any areas to avoid.]
Verification:
[Checks this agent should run or reasoning it should provide.]
```
When multi-agent tools are available, dispatch the subagents concurrently and synthesize their results as they return. When those tools are not available, parallelize available local inspection commands and do the remaining work directly.
## Synthesis
The main agent owns the final result.
As agent results come back:
- Compare their recommendations against the repository or source context.
- Resolve conflicts explicitly.
- Apply only the parts that fit the user's request and project constraints.
- Keep final edits focused and avoid unrelated refactors.
- Run the smallest reliable verification that proves the result works.
If an agent returns an unverified claim, verify it before relying on it.
## Final Response
Report back with the completed result, what changed or was produced, and what verification happened. Keep the answer plain and user-facing unless the user asks for implementation details.
5
27
1,263

Working with AI means accepting no bottlenecks.
I don’t always exercise that instinct as much as I should. But a few days ago, I did!
I had a local workflow problem:
how to parallelize work when a single repository is ~50GB?
I wanted multiple parallel workstreams, but I definitely did not want 10 full copies of the repo when I barely had disk space for one. Worktrees don’t solve it.
So I built Mirage.
It leverages APFS to clone a folder with virtually zero upfront disk cost, and then only pays as files are actually edited in a sweet CLI API.
Suddenly BANG! I can spin up a bunch of “worktrees” fast and cheap. Now to the next bottlekneck...
Github repo here: renanliberato/mirage
8