
Building | a16z speedrun scout | Co-founder and former CTO of Dex
Joined August 2011
- Tweets 2,108
- Following 883
- Followers 325
- Likes 6,746
207 Photos and videos













Pinned Tweet

May 14
Very grateful to have been named in the Forbes 30 Under 30 Europe AI list!
It was a surprise seeing this come in right as I was stepping back from Dex, but I'll admit I was very happy to see my achievements marked - building a great team and the best voice AI experience in recruitment, and raising $8.4m in funding.
Really though, it was a great reminder of just how early in my career I am. So stay tuned, the best is yet to come.
And yes, I promise this is the only time I'll post about it!
1
16
1,075
Once again, this is not about protecting under-16s. It’s about ensuring everyone else has their identity verified and disclosed to the government when logging in to social media.

We are banning social media access for under 16s.
These days kids must find their feet in a world where technology intrudes into every area of their life.
I just can’t let that go on anymore. So we’re giving children their childhoods back.
Community note
The UK Government's 'careful review' of the research found a small correlation between children's use of social media and wellbeing, but no evidence of a causal effect:
gov.uk/government/pub…
assets.publishing.service.gov.uk/media/696e0b46…
2
22
Jun 14
correct
Jun 13

Around the time gpt4 came out, I said that gpt4 level models would run on consumer hardware. And they do, now. In fact, better. And now I will also say: mythos / gpt 5.5 pro models will run on consumer hardware. Prepare accordingly
33
Jun 13
Wait, does London get to keep DeepMind in the draft??
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
71
Jun 13
I was going to offer shares in my stealth startup in exchange for Fable tokens, but in light of recent news I’m coming out of stealth as a sovereign foundational model startup. If anyone wants to transfer the £Bil, my address is bc1qvvdnm…
74
Jun 12
this is actually very cool - can’t wait to experiment
Jun 12

We just shipped 𝙷𝚊𝚛𝚗𝚎𝚜𝚜𝙰𝚐𝚎𝚗𝚝, a unified abstraction to orchestrate and integrate any agent’s “brain” into your app.
@aisdk now frees you from both model and agent lock-in. (And it doesn’t just get you portability, it’s also delightful to use ofc!)
1
57
Harry Uglow retweeted

Jun 12
We just shipped 𝙷𝚊𝚛𝚗𝚎𝚜𝚜𝙰𝚐𝚎𝚗𝚝, a unified abstraction to orchestrate and integrate any agent’s “brain” into your app.
@aisdk now frees you from both model and agent lock-in. (And it doesn’t just get you portability, it’s also delightful to use ofc!)
Jun 12

AI SDK now supports agent harnesses like Claude Code, Codex, and Pi with sandboxed sessions and AI SDK-compatible streams:
𝚌𝚘𝚗𝚜𝚝 𝚊𝚐𝚎𝚗𝚝 = 𝚗𝚎𝚠 𝙷𝚊𝚛𝚗𝚎𝚜𝚜𝙰𝚐𝚎𝚗𝚝({
𝚑𝚊𝚛𝚗𝚎𝚜𝚜: 𝚌𝚕𝚊𝚞𝚍𝚎𝙲𝚘𝚍𝚎,
𝚜𝚊𝚗𝚍𝚋𝚘𝚡: 𝚌𝚛𝚎𝚊𝚝𝚎𝚅𝚎𝚛𝚌𝚎𝚕𝚂𝚊𝚗𝚍𝚋𝚘𝚡(),
});
Available in canary: 𝚗𝚙𝚖 𝚒 𝚊𝚒@𝚌𝚊𝚗𝚊𝚛𝚢. We welcome your feedback as we bring agent harness portability to the ecosystem, with excellent DX.
vercel.com/changelog/program…
66
51
1,219
240,634
Jun 9
Please for the love of god stop letting refinement conversations with Claude leak into the output.
Just seen a pitch deck where slide 2’s title is “The whole picture. One slide.” 🤦♂️
3
407
Jun 7
Remote coding with AI just rules.
I’ve spent the weekend exploring 🇵🇱 Wrocław (beautiful city, go there!) and since Friday afternoon shipped 14 PRs to a new project I’m working on, all from my phone while out and about.
My girlfriend is only slightly annoyed.

2
101
Jun 7
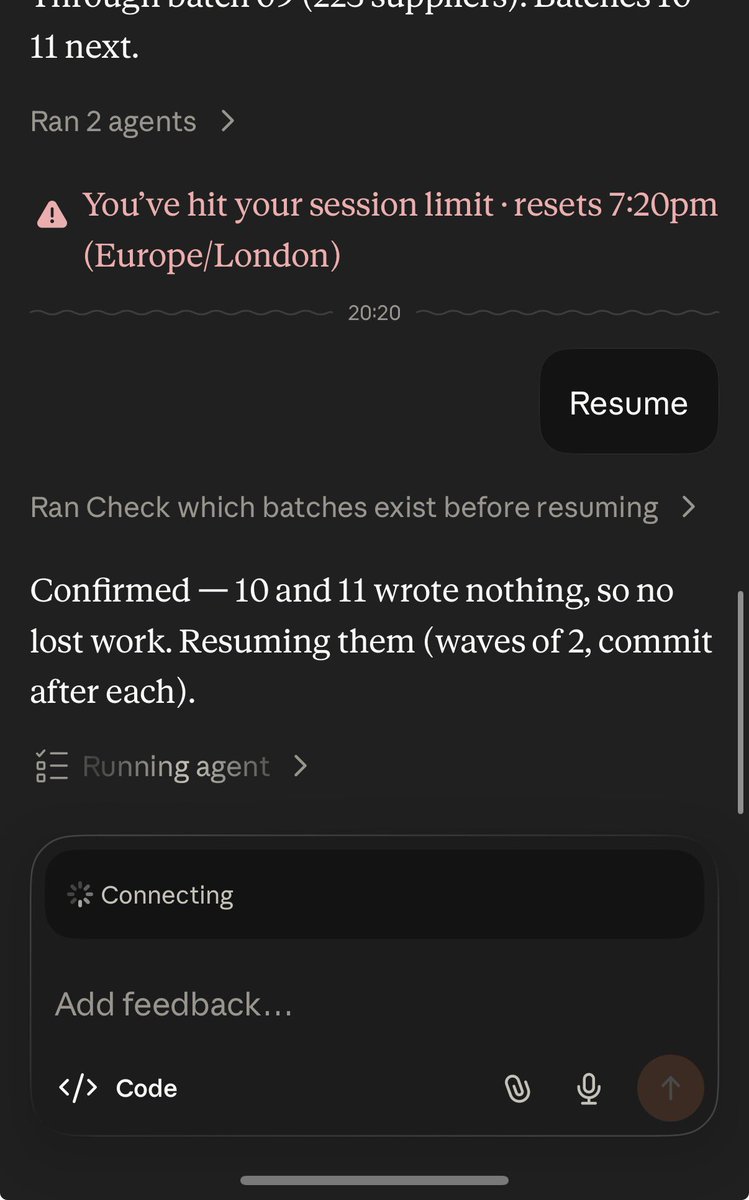
Update: we made it!
Jun 7

On the runway for my flight home, but Claude usage resets in 1 min. Can we hold it up a bit please so I can tell my agents to resume before we hit the air??
66
Jun 7
On the runway for my flight home, but Claude usage resets in 1 min. Can we hold it up a bit please so I can tell my agents to resume before we hit the air??
1
114
Jun 7
I think this is a good proxy for evaluating venture as an asset class. If valuations are “too high” by current traction, but justifiable by chance of success, it’s a good time to invest in startups.
How you judge chance of success is left as an exercise to the reader
Jun 7

One thing I sometimes do in office hours is calculate the implied probability represented by the startup's valuation. E.g. if a startup would be worth 10b if things go as planned and their dday valuation cap is 25m, they're a good bet if they have a 1/400 chance of being right.
47
Jun 6
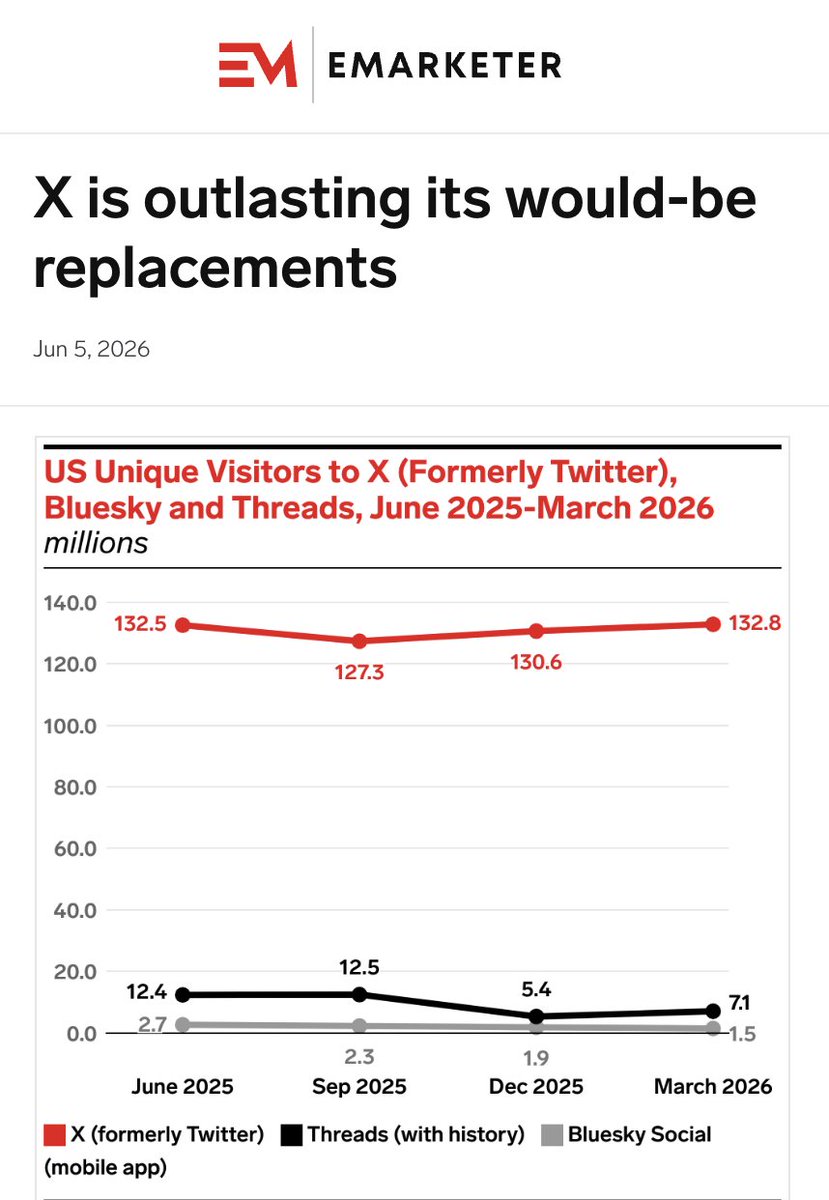
As someone who has been on Twitter for 15 years, it is clear to me that the site is the best it’s ever been.
The early Elon days were quite rough but I’m very glad it’s bounced back and we aren’t all on Bluesky.


131
Jun 4
This is what I was talking about with cost savings coming from open source models btw
Jun 4

Pulled the trigger today and switched 100% of Lindy traffic to DeepSeek v4, churning from Anthropic models.
Saves us millions of $ and we're actually seeing an *increase* in performance on many core use cases. Transformative for the business.
59
Jun 4
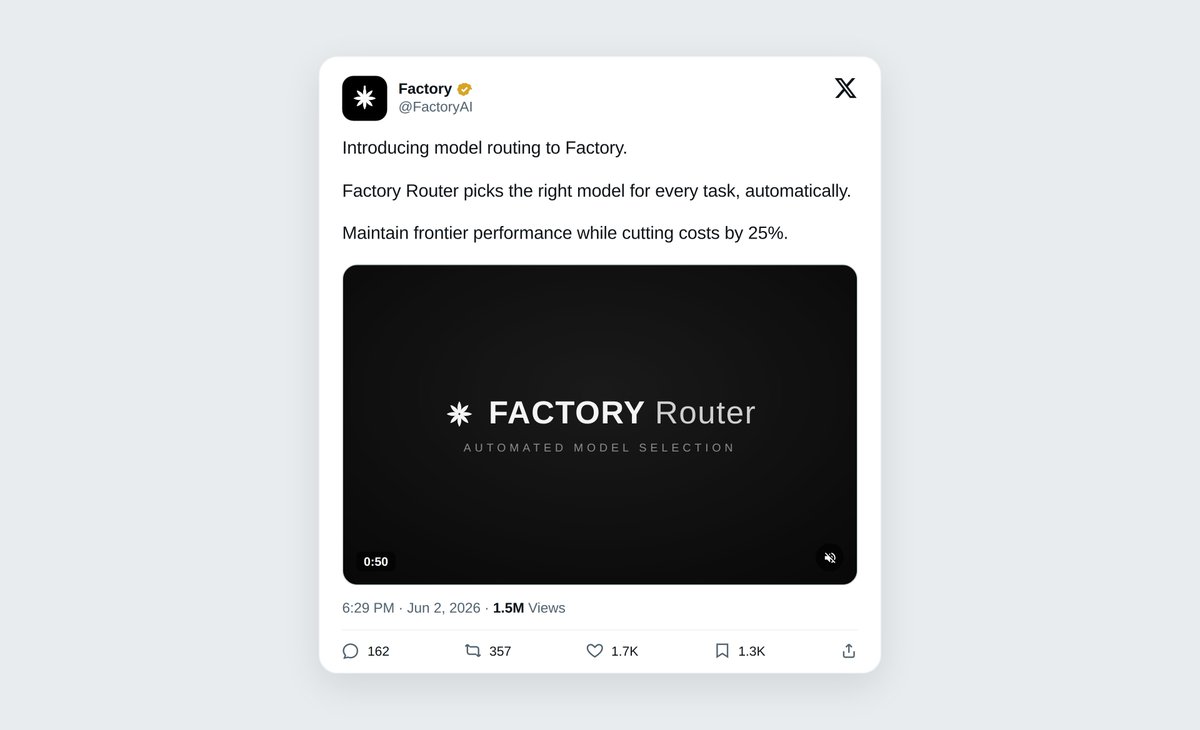
Lots of excitement around Factory's model router and its 20% cost saving, and rightly so.
Many are saying this is just the start. After digging into the numbers, I think it's close to the ceiling. Here's why 👇
Routing only saves money on work a cheaper model can handle without dropping the ball. Factory's router holds ~99% of Opus 4.7's pass rate while cutting cost by 20%. They also published a Pareto curve of other experiments, showing that when they pushed harder performance suffered. Getting down to ~56% of Opus 4.7 cost dragged the pass rate to 81%. In their research, 20% was the elbow of the curve, i.e. about the most you can save before quality starts to go.
It's also important not to confuse this cost saving as "only 20% of tasks could be handed to smaller models". The reality was likely far more. Firstly, smaller models aren't free - Claude Sonnet is only ~50% cheaper. But most importantly, the hardest tasks are often the long, token-hungry, multi-step ones. So a handful of hard sessions still eat the lion's share of the bill, even if the majority of tasks get routed.
Furthermore, any benchmark that Opus 4.7 scores 99% is forgiving. The tasks we throw at AI in reality are often harder. If you're pushing AI to its limits you'll naturally need to send a higher share of tasks to the smartest models. Hence why I think Factory's numbers form something of a ceiling for cost saving. At least for now...
So why does this matter?
Plenty of startups are now running in-house agents and watching usage spiral. The results are awe-inspiring, but cost is a creeping concern. I've seen teams attempt their own model routing, and if you are Factory's research should give pause for thought. What it shows is that you're unlikely to beat ~20% cost reduction. Worse, if you think you have, you've probably traded away performance without realising it.
For Factory's enterprise clients, 20% off a vast bill is real money. For a startup building it yourself, if you ask me the juice isn't worth the squeeze.
My advice: worry about cost far less than you're tempted to. Put that energy into the product and anything that helps you ship faster. The AI landscape is going to keep shifting and many cost reductions are going to come for free.
Where I'd bet the genuinely dramatic cost reductions will come from (most to least likely):
→ Hardware acceleration letting the frontier labs cut prices
→ Better open-source models and a shift toward local compute
→ Specialised models giving routers cheaper options with best-in-class performance (see Harvey's announcement from the last 24 hours!)
I'm watching the first two very closely this year, and will keep sharing what I find
1
119
Jun 3
How dare this airline charge a fraction of the price of its competitors and not give me the same level of service! Scandal
33
Jun 3
Lot of ground covered today! 📍
Regent’s Park - Bike ride (failed)
Southwark - Trip to bike shop (unplanned)
Home - Pitch call
South Ken - Meeting
Marylebone - Coffee
Fitzrovia - Coffee, then work 2 more calls from a friendly VC office
Now off to Poland 🇵🇱
Back next week 🫡
2
85
Jun 3
Microsoft announces 7 frontier models… and is down 5% on the news 🤷♂️

Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

81