
26 Photos and videos







Ankit Sharma retweeted

18 Nov 2025
India’s First Official @ApacheIceberg Meetup wrapped!
An incredible day for the community with great talks and deep discussions.
Huge thanks to our partners for powering this edition: @awscloud , @puppyquery , @Minio , @e6data , @FireboltHQ , @devrelsquad_ , and @fivetran .
2
9
202
Ankit Sharma retweeted
6 Nov 2025
We benchmarked @ApacheIceberg vs @databricks @DeltaLakeOSS on a 1TB TPC-H workload!
Iceberg OLake ran 18.2% faster at 61% lower cost, scaling seamlessly to billions of rows.
With open, flexible support for @ApacheSpark, Trino, @ApacheFlink, a real advantage for modern team

1
2
2
91
Ankit Sharma retweeted
5 Nov 2025
We recently hosted a fireside chat with the CTOs of OLake and @Bauplan_labs , diving into the evolving world of data engineering, @ApacheIceberg , and AI in data pipelines.
🎙️ Catch the full conversation here:
youtu.be/XOVkaY5MmiQ?si=nl2m…
1
2
50

4 Nov 2025
Iceberg meetup is happening in india

Join us at the Apache Iceberg Meetup in Bangalore, India on November 15th at 10:00 AM IST: luma.com/c6tiloed?tk=1Sv746
Call for Papers is open until November 8th: docs.google.com/forms/d/e/1F…
@puppyquery, @AWS, @e6data, @_olake, @FireboltHQ, @devrelsquad_
#ApacheIceberg #AI #AIStor #DataInfrastructure

2
41
4 Nov 2025
no it is not
3 Nov 2025

C is NOT a hard language. Most people just don’t have the patience to learn pointers properly.
1
29
3 Nov 2025
Yes, having storage compute separated can save a lot. I have seen companies follow hot and cold architecture in warehouses as well just because the requirement is to query the last 1 or 2 year data.
1 Nov 2025

The truth about Big Data that vendors don't want you to know 👇
I'm re-reading this classic blog post from Motherduck CEO Jorgan Tigani titled "Big Data is Dead".
Jordan was a founding engineer in Google BigQuery, so this is a high-signal experience-driven blog post.
💎 Here are my favorite gems from it:
💡 1. People using BigQuery didn't have big data (at all)
The vast majority of users had less than 1TB of TOTAL storage. There were many thousands of customers with half a TB. The median storage was much less than 100GB.
Customers also followed a power law distribution - largest customer had double the second largest customer, who had double the third largest, etc. It quickly got to small numbers at high percentiles.
Industry analysts like Gartner/Forrester also confirmed this idea with Jordan: most enterprises don't have that much data.
And of the customers that had a lot of data?
They queried SIGNIFICANTLY LESS than what they had. 👇
💡 2. Storing a lot != Querying a lot
This is my best take away from the piece. 🏆
It's the idea that even if you're storing many TBs of historical data, you're probably still querying a few GBs.
This is because the value of data drops exponentially with age. You care about what happened a few weeks ago, not 2 years ago.
Last month might have 5% of your total data but serve 80% of queries.
Here's data that proves it:
• Jordan analyzed BigQuery usage and found that 90% of queries processed LESS THAN 100 MB of data.
• S3 is built off this very same principle. They scale their massive distributed system of hard drives by co-locating older, cold data with newer, hot data.
The time-decay property of data means that the working set sizes are way smaller than the total set.
Even if you have a 1000TB table with 10 years worth of data - you may only access last day's data which wouldn't be more than 50GB compressed. My laptop can do that easy. 🙂
Modern computing also has tons of tricks to avoid scanning all the data ( column projection, partition pruning, segment elimination, predicate pushdown)
Separating compute and storage allowed customers to keep storing data without having to scale up unnecessary compute for it. 🏆 (ty Snowflake)
Kafka with KIP-405 is a great example of this.
The best logical conclusion from this?
💡If you use scalable object stores (e.g S3), you can probably get away with just running one node for compute.
If nothing changes, your compute requirements remain the same while your total data set continues to grow.
In the past, this meant you had to deploy more instances in order to store the data. Today, you can only scale up the storage layer. You probably won't need to scale to distributed processing at all to match your workload.
Critically, this also allows you to completely outsource all the complicated storage bits to something like S3.
Object stores solve replication, durability, availability, and hot-spot management for you (for cheaper).
Warpstream/Bufstream/Tansu in Kafka are great examples of this.
💡 Big Data is here, it's just not evenly distributed
Yes, data size is growing in the world. But it's mostly stored in a few big tech companies - the rest don't see that much data at all.
My experience matches this very well, yet the companies I worked for still had many thousands of customers
💡 It's not the data size - it's you that's the problem
Back in the big data days, orgs had trouble getting actionable insights from their data. This was blamed on the data's size and solved by new distributed infra software that could handle the data.
The orgs migrated their legacy systems to the new ones... and found they still can't make sense of the data.
The size was never the problem.
💡 The Big Data Tax
Companies pay a hefty price for enterprise-scale infrastructure.
Not to mention the organizational cost of managing yet another big data system, which is way more hidden.
It consumers engineer bandwidth by having them learn the system's nuances, configs, establishing monitoring, establishing processes around deployments and upgrades, attaining operational expertise on how to manage it, creating runbooks, testing it, debugging it, adopting its clients and API, using its UI, keeping up with its ecosystem, etc.
In conclusion?
Don't follow the bandwagon. ✌️

2
57
Ankit Sharma retweeted
22 Oct 2025
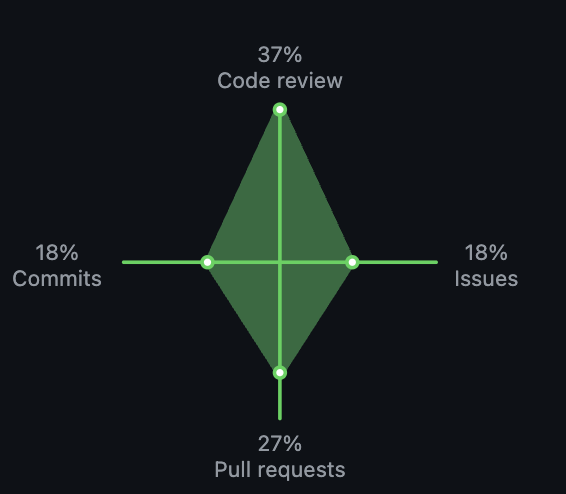
A very successful @hacktoberfest so far!
We have been joined by over 30 contributors and a lot more pull requests
Raised
Reviewed
Convos driven
and merged .
The power of open source is always amazing great to see people leading the wave .
The rewards dropping soon!
1
1
2
109
Ankit Sharma retweeted
26 Sep 2025
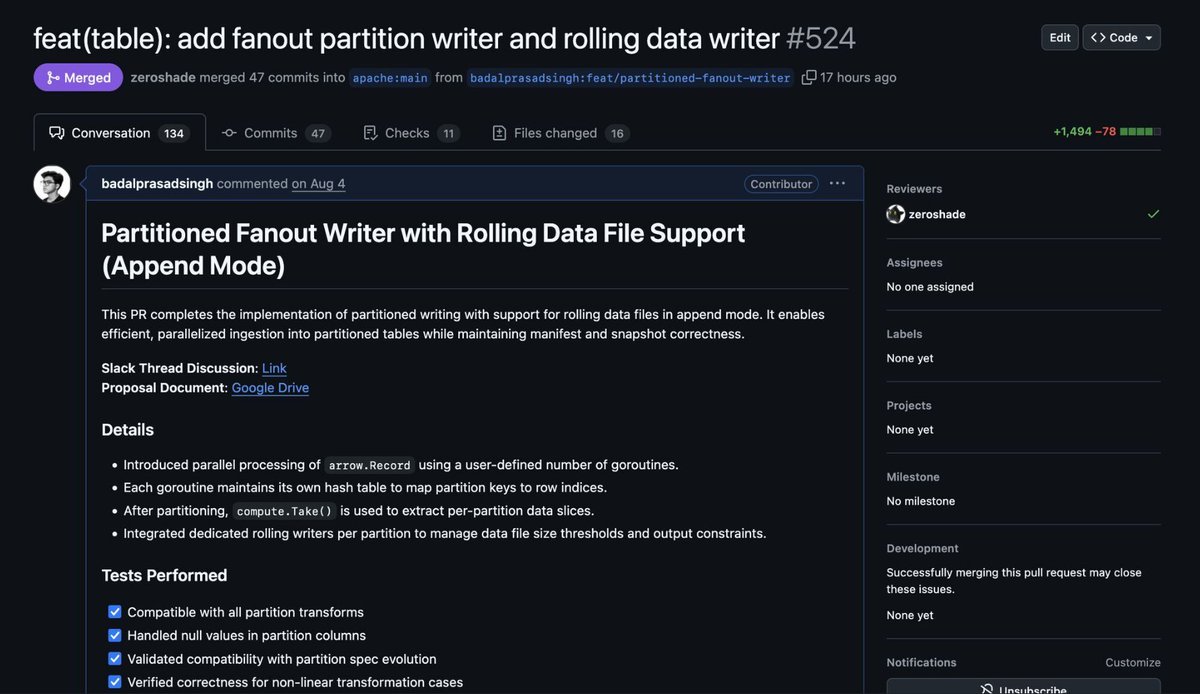
We’ve contributed an important feature to @ApacheIceberg Go, writing into partitioned tables!
The new design uses a fan-out strategy with rolling writers per partition, flushes parquet files efficiently, and supports all partition transforms built on top of @ApacheArrow .
1
3
7
286
Ankit Sharma retweeted
25 Sep 2025
Join us at Bengaluru Streams and Lakehouse Days on Sept 27, 2025, at @Accel Launchpad!
Our Co-founder & CTO, Shubham Baldava @cto_datazip , will present on Reimagining Ingestion for @ApacheIceberg sharing insights from building OLake, our open-source high-performance tool.

2
4
114
Ankit Sharma retweeted
22 Sep 2025
Wrapped @FOSSUnited 2025, BLR.
We showed how OLake makes ingestion to Iceberg 5–500× faster, walked through the stack, and met future contributors.
Community > everything.
#OpenSource #DataEngineering #ApacheIceberg



1
2
5
135
Ankit Sharma retweeted
18 Sep 2025
New Benchmarks Are In!
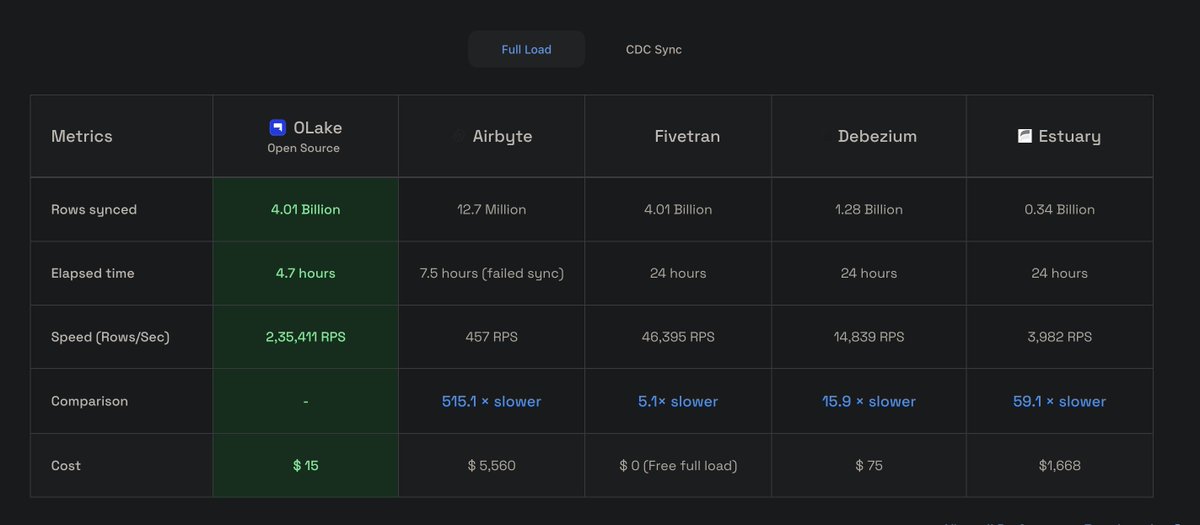
After countless hours of hard work from our amazing team, OLake now delivers full load sync speeds that are 5×–500× faster than other tools out there.
💡Want to see it in action? Spin it up locally and test the benchmarks yourself!
#DataEngineering #Iceberg

1
1
4
120
Ankit Sharma retweeted
13 Sep 2025
We’re coming to Mumbai for AWS Community Day @awsugmum on Oct 11!
We’re proud to be the sponsor of the Community Day—great to be part of the global stage.
We’re excited to connect and share why we’re the fastest data replication tool in the world for Apache Iceberg
1
4
8
229
Ankit Sharma retweeted
3 Sep 2025
Medallion Architecture, explained by experts at @nutanix :
Layered data pipelines, Bronze, Silver, Gold—
help teams manage raw, cleaned, and business-ready data efficiently.
Key for reliable analytics and scalable lakehouse operations.
#DataEngineering #ApacheIceberg
1
2
6
100
Ankit Sharma retweeted
1 Sep 2025
OLake Community Week had an awesome weekend too! 🚀
Our team keeps growing with more engineers and innovators.
Every teammate, every Slack member, every GitHub star, and every single code contributor, you’re part of OLake. ❤️
Here’s to more memories & cool features! ✨
#team


1
2
7
93