
Haskeller, Alum @recursecenter Sp2'17
Joined January 2014
- Tweets 88
- Following 1,010
- Followers 140
- Likes 1,057
7 Photos and videos



Heneli retweeted

Jun 12
Amethyst: Adaptive Compaction for LSM Trees via Segment-Level Policy Selection

2
5
35
2,227

📣 Introducing databow: one command-line tool to query them all, built with Rust and ADBC.
Query any SQL source that has an ADBC driver (30 and counting) right from your terminal with one simple CLI.
To install 👉 uv tool install databow
Link to announcement in the comments👇

ALT databow: a command-line tool for querying databases
2
5
42
3,078
Heneli retweeted
dbt Fusion is the Python-to-Rust rewrite that started at SDF Labs before it was acquired by dbt Labs. After a huge refactoring effort in the last months, we are announcing dbt Core 2.0 – the open-source slice of the Fusion codebase that is continously updated w/ Copybara.
4
6
69
10,960
Heneli retweeted
May 30
A pre-condition that can make a lexer/parser run much faster is assuming that the input is already validated and the job of the parser is just extracting the contents from the input.
4
2
12
1,402
Heneli retweeted

May 21
I just had the chance to watch Samyak Sarnayak's talk about cancellation safety and async Rust (and how a `&mut` can lead to a deadlock). If this is a topic that interests you, I recommend checking it out: samyak.me/talks/cancel/

1
13
85
3,567
Heneli retweeted

May 14
When a partitioning change to our petabyte-scale ClickHouse cluster caused critical billing jobs to stall, standard metrics showed no obvious errors. Here's how we identified severe lock contention in ClickHouse's query planner and built upstream patches to fix it. cfl.re/48WfsXl
4
21
163
45,692
Heneli retweeted

May 3
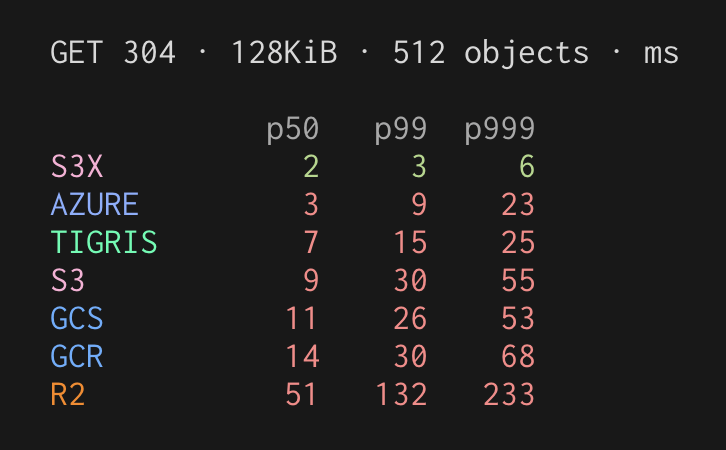
get-if-not-match is important for building fast databases on object storage. used in e.g. tpuf for the WAL check to make sure the cache has the latest data.
of the big 3 (Azure/S3/GCS), it may surprise many that Azure comes out the winner!
(S3X is S3 one-zone, GCR is GCP's equivalent)
9
6
138
32,194
Heneli retweeted

The founders of FloeDB (@markcusack Kurt Westerfeld) gave an interesting talk with @CMUDB about their new @ApacheIceberg-compatible query engine. Two key takeaways from their talk:
1⃣ Floe is a hard fork of @YellowbrickData.
2⃣ Floe is building a "catalog-of-catalogs"
youtube.com/watch?v=Kq3csHJq…
1
12
128
16,632
Heneli retweeted

Mar 19
At AWS we're big Rust users. Lambda, DSQL, S3, EC2, Bedrock, and many more run Rust code.
Dial9 is a new tool, built at AWS, for diving deep into the performance of tokio-based applications.
Good work, Russel!

18
63
745
55,669
Heneli retweeted

Feb 20
load balancing long-lived connections is so much harder than load balancing small requests
3
2
38
3,781
Heneli retweeted

Feb 19
The 2nd edition of Designing Data-Intensive Applications, by @martinkl and me, is finished and sent to the printers! Ebooks available next week, and print books in 3–4 weeks. Sigh of relief. 😅
(BTW, this is a good opportunity to support your favourite local bookshop!)

106
439
3,857
409,664

🦆 ↔️ 🦀 DuckDB Labs is looking for a Rust engineer to join our team in Amsterdam.
📝 See the details and application page at duckdblabs.com/jobs/rust_eng…
6
40
191
20,225
Heneli retweeted

Feb 18
Much of the credit should go to sqlglot’s test suite. For projects of this type, the test suite is the “source” and the code can be generated pretty much any way you like.
Feb 16

Introducing polyglot - A Rust SQL transpiler for more than 30 SQL dialects.
It has 100% coverage for sqlglot‘s test fixtures.
github.com/tobilg/polyglot
3
3
59
6,027
Heneli retweeted

Feb 18
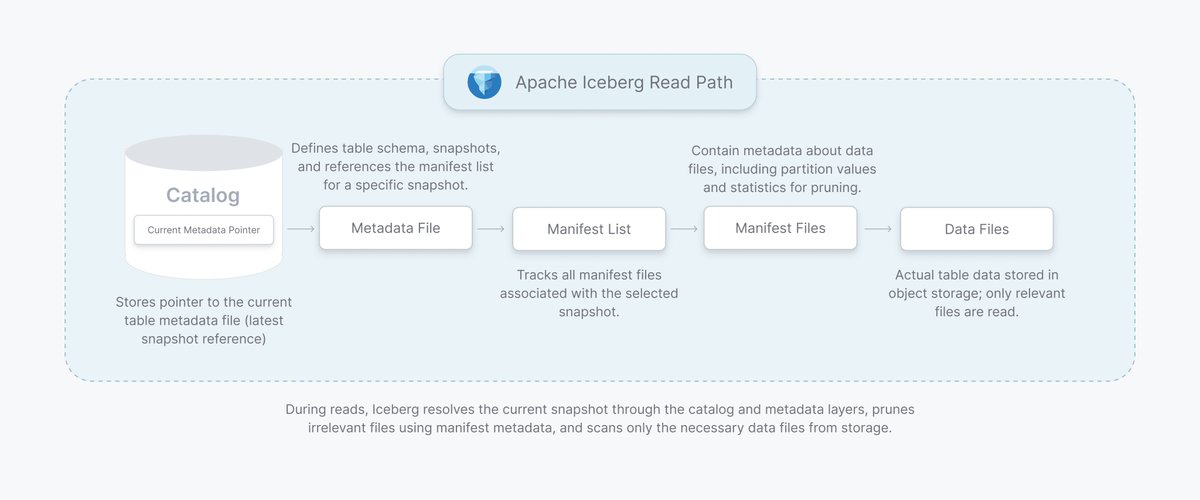
Ever wondered how an engine actually reads an Iceberg table?
Iceberg read path in one line:
Catalog → Metadata → Manifest list → Manifest files → Data files
Apache Iceberg Read Path (Engine → Table)
When an engine reads an Iceberg table, it walks this chain from top to bottom:
1) Catalog
The starting point.
Stores a pointer to the table’s current metadata file, which represents the latest snapshot reference.
2) Metadata File
Defines the table schema, lists snapshots, and references the manifest list for the snapshot being read.
3) Manifest List
Tracks all manifest files associated with the selected snapshot.
4) Manifest Files
Contain metadata about data files, including partition values and file-level statistics, which help determine which files should be read.
5) Data Files
The actual table data is stored in object storage. This is what the engine ultimately reads.
Why this matters
During reads, Iceberg resolves the snapshot through the catalog and metadata layers, then uses manifest metadata to identify the exact set of data files for that snapshot.
2
5
432
Heneli retweeted
Feb 17
Using Cap’n Proto in Rust to get zero-copy deserialization, but Codex insists on writing de/serialization functions that build a struct full of heap-allocated strings. Because that’s what dominates the training set of model and programmers everywhere.
14
7
247
21,008
Heneli retweeted

Feb 17
SIMD can produce insane yields but it's worth bearing in mind that at least some of the yield isn't from the SIMD instructions, it's from disciplining the programmer into writing branchless functions and pipelines
the SIMD is the cheese at the end of the bit-hacking maze
Feb 17

Wow. SIMD is fast. I've gone from:
- 8mb/s (unoptimized html parser built on selectolax)
- 150mb/s (cython parser built on lexbor)
- gb /s (naive SIMD implementation)
13
38
749
36,952
Heneli retweeted
Feb 18
"hand-written" recursive descent parser on a Vec<Token>. 40k lines of Rust as expected for a language as complex as SQL.
2
9
505
Heneli retweeted

Feb 16
Introducing polyglot - A Rust SQL transpiler for more than 30 SQL dialects.
It has 100% coverage for sqlglot‘s test fixtures.
github.com/tobilg/polyglot
14
49
463
41,829
Heneli retweeted
A somewhat academic talk about the AI usecases driving changes in @ApacheParquet and new formats in "Column Storage for the AI Era"
Recording: youtu.be/k9uhw7yqPsQ
Slides: docs.google.com/presentation…

1
22
143
8,774
Heneli retweeted
Jan 18
This is the kind of article about @ApacheDataFusio I could only dream of a few years ago. It is hugely gratifying to hear that the focus on community and extensibility lead to people like @lukekim and @phillipleblanc to create whole new companies and products around DataFusion.

Introducing Engineering at Spice AI: a technical series on the systems behind Spice’s SQL-first data & AI platform.
First post explores why @ApacheDataFusio sits at the core, and how we extend planning/execution for federation, acceleration, and search: hubs.ly/Q03_11g00

3
70
9,557