
NLP researcher. Assistant Professor at NYU CS & CDS.
Joined December 2016
- Tweets 154
- Following 418
- Followers 8,188
- Likes 325
1 Photos and videos



Image editing models can put you on the Moon, but can they precisely move a circle right by 50 pixels? 📐
Introducing 🎨PaintBench: a foundational eval of visual editing operations with only one right answer.
The highest-performing model (@NanoBanana 2) reaches only 17.1%.
4
20
50
5,141
He He retweeted
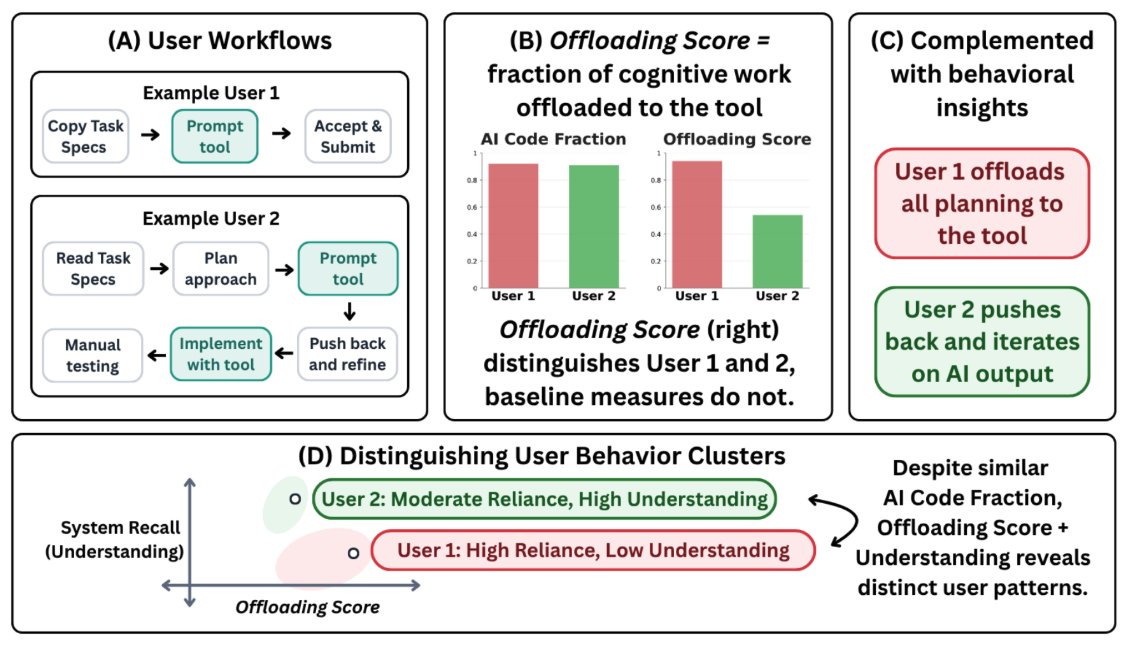
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)

7
74
208
75,620
He He retweeted

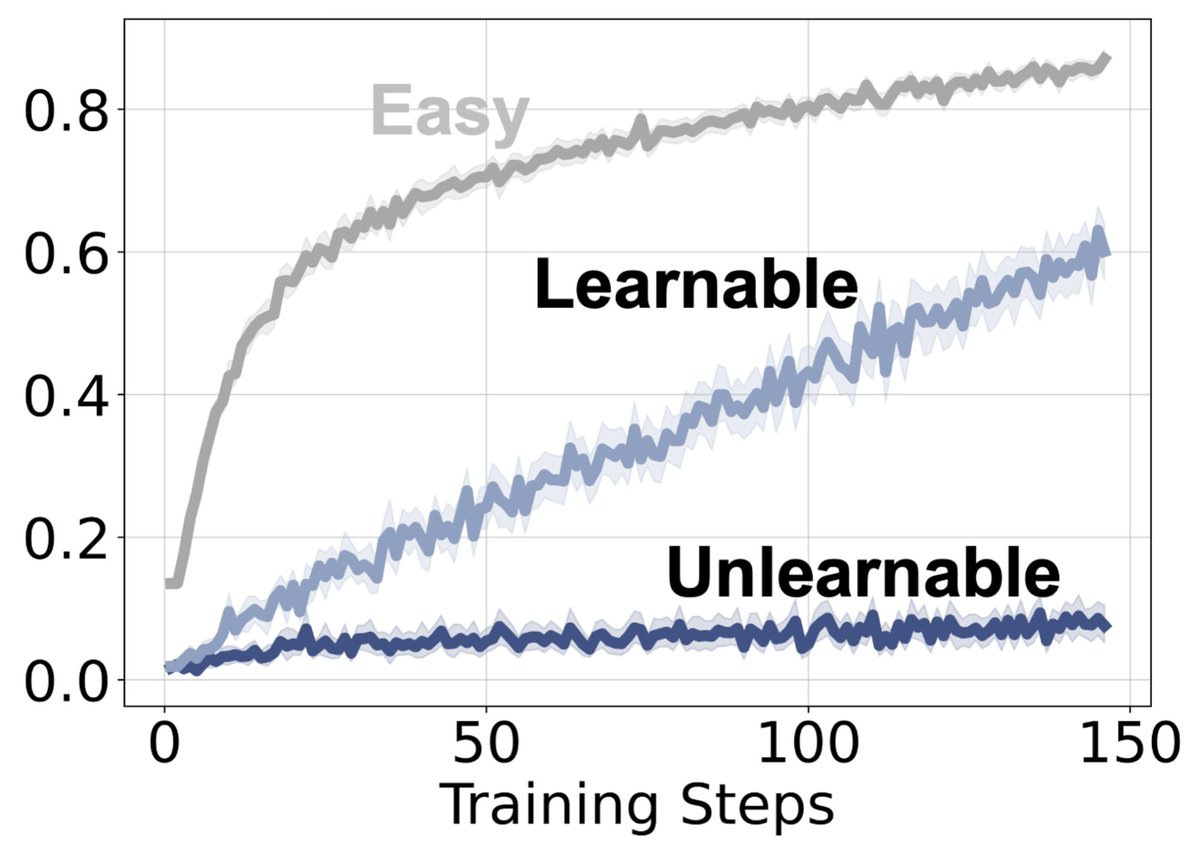
Most assume unlearnable examples never get positive reward. They do.
In our ICML paper, We reveal that a hard problem can receive positive reward during RLVR but remain unlearned.
We show the phenomenon is more likely a representation issue rather than RL optimization artifact.
7
38
365
28,989
Dimitris' experiments have inspired many including me. Excited for this talk!

Giving my first agent talk at MIT's NLP seminar (virtually) next Wednesday. First time I'm focusing less on results and more on the process that got me there. Feels strange and a little like growing up.
Abstract:
Over the past few months, agents have changed the way I do research by collapsing the distance between a question and an experiment. Ideas that used to die under the technical burden of setting up the experiment are now testable in days, often by one person, an agent, and a laptop. In this talk I'll walk through three vignettes, side projects I ran since February: training the smallest transformer that can do 10-digit addition, predicting LLM benchmarks without running them, and building the first trained computer that is a transformer. These projects look unrelated, and that is part of the point. I'll share what I learned from each — both about the problem and about agents — and why taste and the ability to verify become more important when execution becomes cheap. I'll close on a question I don't have a good answer to: we've always trained researchers through technical work, and taste and verification emerge from it. What happens when most of it becomes automated?

5
1,822
He He retweeted

Apr 20
I'll be at ICLR this week to present our poster on factors affecting the novelty of LLM output on Fri afternoon. Come talk to me about this or anything else in the future-of-work/societal impacts space! Also hmu if you want to check out the Maracana stadium when we're there!😎🇧🇷

Jan 26

Our work on LLM novelty as the frontier of original and high-quality output was accepted to #ICLR26! Come talk to us about how model scale, SFT, and RL affect this trade-off! See you in Brazil!🇧🇷h/t to my awesome collaborators @hhexiy @valeriechen_ @JanePan_ @jcyhc_ai

1
11
58
15,269
He He retweeted

Mar 25
Love seeing this.
There are two flavors of automated AI research.
One that just cares about hill climbing on a target benchmark (e.g., autoresearch).
The other that actually care about the idea (e.g., this post). Beyond just looking at the performance, we want to ask: does the idea offer some new insights? Is it simple and scalable? Is it generalizable? The evaluation is a lot harder for this case, because it requires the human judge to have a good research taste in the first place, but it’s also gonna be much more fun :)

1
6
62
10,469
He He retweeted

🥳Accepted as ICLR 2026 Oral!
Check it out if you are interested in CoT Monitoring, Reward Hacking, and Loophole Discovery!
arxiv.org/pdf/2510.01367
Joint work with @nitishjoshi23, Barbara Plank @rico_angell, @hhexiy

7 Oct 2025

‼️Your model may be secretly exploiting your imperfect reward function without telling you in the CoT!
How to detect such 'implicit' reward hacking if the model is hiding it?🧐
We introduce TRACE🕵, a method based on a simple premise: hacking is easier than solving the actual task.
🧵

5
21
191
26,442
He He retweeted

Jan 19
An English mirror site of Scientific Spaces: rohin-garg.github.io/kexue-e…
Created by @GargRohin3301 . Thanks a lot!
3
21
160
14,266
He He retweeted

27 Oct 2025
very cool post
quick reminder everyone doing online distillation is really reimplementing DAGGER, a paper published in 2011 that tested everything on linear SVMs
this is one inspiring feature of pure research: you never really know when your ideas will start to matter

27 Oct 2025

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
thinkingmachines.ai/blog/on-…
12
25
342
44,982
He He retweeted

9 Oct 2025
New blog post: Hours, Not Months – The Custom AI Era is Now: open.substack.com/pub/oumiai…
Oumi website: oumi.ai
6
14
2,327
Reward hacking means the model is making less effort than expected: it finds the answer long before its fake CoT is finished. TRACE uses this idea to detect hacking when CoT monitoring fails. Work led by @XinpengWang_ @nitishjoshi23 and @rico_angell👇
7 Oct 2025
‼️Your model may be secretly exploiting your imperfect reward function without telling you in the CoT!
How to detect such 'implicit' reward hacking if the model is hiding it?🧐
We introduce TRACE🕵, a method based on a simple premise: hacking is easier than solving the actual task.
🧵
4
11
130
24,344
He He retweeted

7 Oct 2025
Monitoring CoT may be insufficient to detect reward hacking. We develop a very simple method to detect such implicit reward hacking - truncate CoT, force predict answer, and use the AUC of the %CoT vs expected reward curve as a measure.
Last project of my PhD!
7 Oct 2025
‼️Your model may be secretly exploiting your imperfect reward function without telling you in the CoT!
How to detect such 'implicit' reward hacking if the model is hiding it?🧐
We introduce TRACE🕵, a method based on a simple premise: hacking is easier than solving the actual task.
🧵
4
18
4,914
He He retweeted

9 Oct 2025
I don't know what labs are doing to these poor LLMs during RL but they are mortally terrified of exceptions, in any infinitesimally likely case. Exceptions are a normal part of life and healthy dev process. Sign my LLM welfare petition for improved rewards in cases of exceptions.
292
338
7,087
714,372
Come to Nick's poster if you're at #COLM2025 and learn about how to run LLM experiments the scientific way!
8 Oct 2025

LLMs are expensive—experiments cost a lot, mistakes even more.
How do you make experiments cheap and reliable? By using hyperparameters' empirical structure.
@kchonyc, @hhexiy, and I show you how in Hyperparameter Loss Surfaces Are Simple Near their Optima at #COLM2025!
🧵1/9
4
31
9,180
He He retweeted

8 Oct 2025
LLMs are expensive—experiments cost a lot, mistakes even more.
How do you make experiments cheap and reliable? By using hyperparameters' empirical structure.
@kchonyc, @hhexiy, and I show you how in Hyperparameter Loss Surfaces Are Simple Near their Optima at #COLM2025!
🧵1/9
2
10
34
14,302
He He retweeted

2 Sep 2025
How can we evaluate whether LLMs and other generative models understand the world?
New guest video from Keyon Vafa (@keyonV) on methods for evaluating world models.

2
21
144
22,745
He He retweeted

11 Aug 2025
📢I'm joining NYU (Courant CS Center for Data Science) starting this fall!
I’m excited to connect with new NYU colleagues and keep working on LLM reasoning, reliability, coding, creativity, and more!
I’m also looking to build connections in the NYC area more broadly. Please reach out if you're interested in chatting!
This move comes after 8 years working with incredible students and collaborators at UT Austin. Thank you to everyone who supported me in my first academic appointment; I look forward to continuing our collaborations but I will miss you! (and the breakfast tacos!)


93
48
761
65,180
He He retweeted

6 Aug 2025
🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institute Tübingen and Max Planck Institute for Intelligent Systems in September 2025! 🚨
Hiring. I'm looking for multiple PhD students: both those able to start in Fall 2025 (i.e., as soon as possible) and through centralized programs like CLS, IMPRS, and ELLIS (the deadlines are in November) to start in Spring–Fall 2026. I'm also searching for postdocs, master's thesis students, and research interns. Fill the Google form below if you're interested!
Research group. We will focus on developing algorithmic solutions to reduce harms from advanced general-purpose AI models. We're particularly interested in alignment of autonomous LLM agents, which are becoming increasingly capable and pose a variety of emerging risks. We're also interested in rigorous AI evaluations and informing the public about the risks and capabilities of frontier AI models. Additionally, we aim to advance our understanding of how AI models generalize, which is crucial for ensuring their steerability and reducing associated risks. For more information about research topics relevant to our group, please check the following documents:
- International AI Safety Report,
- An Approach to Technical AGI Safety and Security by DeepMind,
- Open Philanthropy’s 2025 RFP for Technical AI Safety Research.
Research style. We are not necessarily interested in getting X papers accepted at NeurIPS/ICML/ICLR. We are interested in making an impact: this can be papers (and NeurIPS/ICML/ICLR are great venues), but also open-source repositories, benchmarks, blog posts, even social media posts—literally anything that can be genuinely useful for other researchers and the general public.
Broader vision. Current machine learning methods are fundamentally different from what they used to be pre-2022. The Bitter Lesson summarized and predicted this shift very well back in 2019: "general methods that leverage computation are ultimately the most effective". Taking this into account, we are only interested in studying methods that are general and scale with intelligence and compute. Everything that helps to advance their safety and alignment with societal values is relevant to us. We believe getting this—some may call it "AGI"—right is one of the most important challenges of our time.
Join us on this journey!

76
90
838
106,052
He He retweeted

23 Jul 2025
🚀 Excited to share that the Workshop on Mathematical Reasoning and AI (MATH‑AI) will be at NeurIPS 2025!
📅 Dec 6 or 7 (TBD), 2025
🌴 San Diego, California

7
57
235
38,454