
CS PhD at @nyuniversity, @NSF GRFP, @Deepmind Fellowship, @SiebelScholars | @Princeton @Princeton_nlp '23 | @Columbia '21.
Joined February 2023
- Tweets 27
- Following 147
- Followers 443
- Likes 51
9 Photos and videos





Jane Pan retweeted

Can LLMs control their chains of thought (CoT)? If so, they could evade CoT monitors 🚨
We introduce the CoT Controllability eval suite to find out.
Our results leave us cautiously optimistic that today’s models struggle to obfuscate their CoT in ways that undermine monitorability.
In this thread, I explain additional findings that I find interesting
Joint work w @OpenAI
Mar 5

We have a new eval to help keep chains of thought (CoT) monitorable: CoT Controllability.
This tests whether LLMs can control their CoT, helping to evade CoT monitors.
So far, the results leave us cautiously optimistic: today’s models struggle to obfuscate their reasoning in ways that undermine monitorability.

3
12
76
9,965

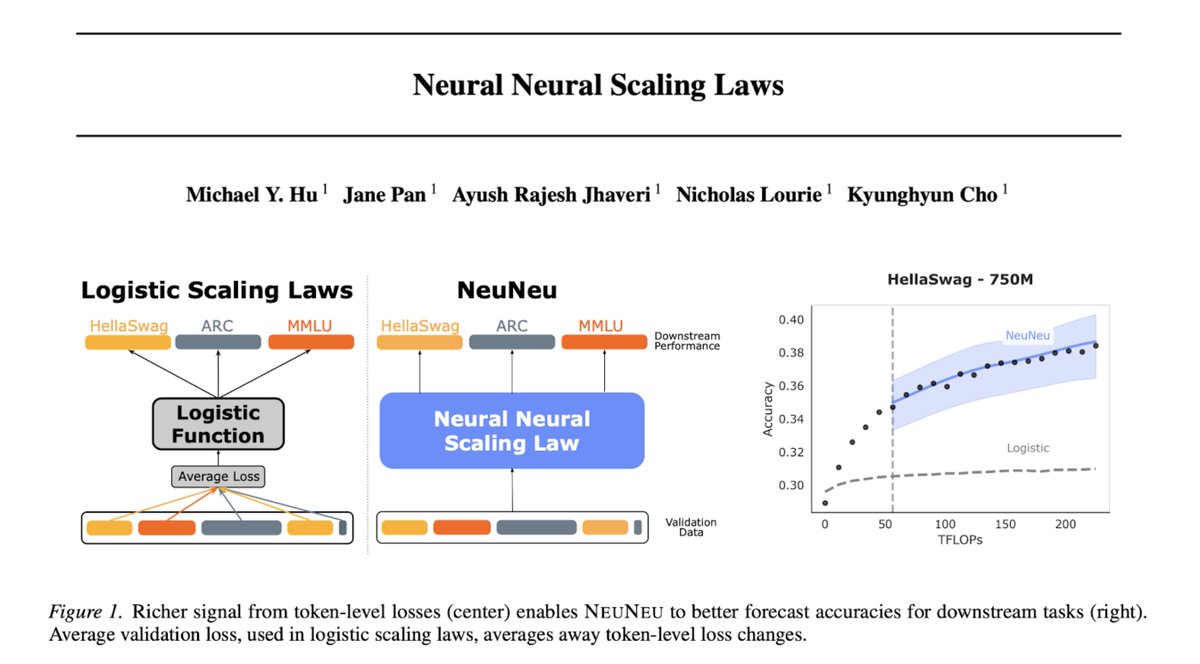
Excited to see NeuNeu out — learned scaling laws from open-source LM trajectories!
Jan 28

if you truly believe in the bitter lesson, then why hand design scaling laws?
introducing: neural neural scaling laws (NeuNeu), a neural network
- trained on open-source LM trajectories
- that predicts LMs' future downstream task performance
🧵👇
8
631
Jane Pan retweeted

Jan 26
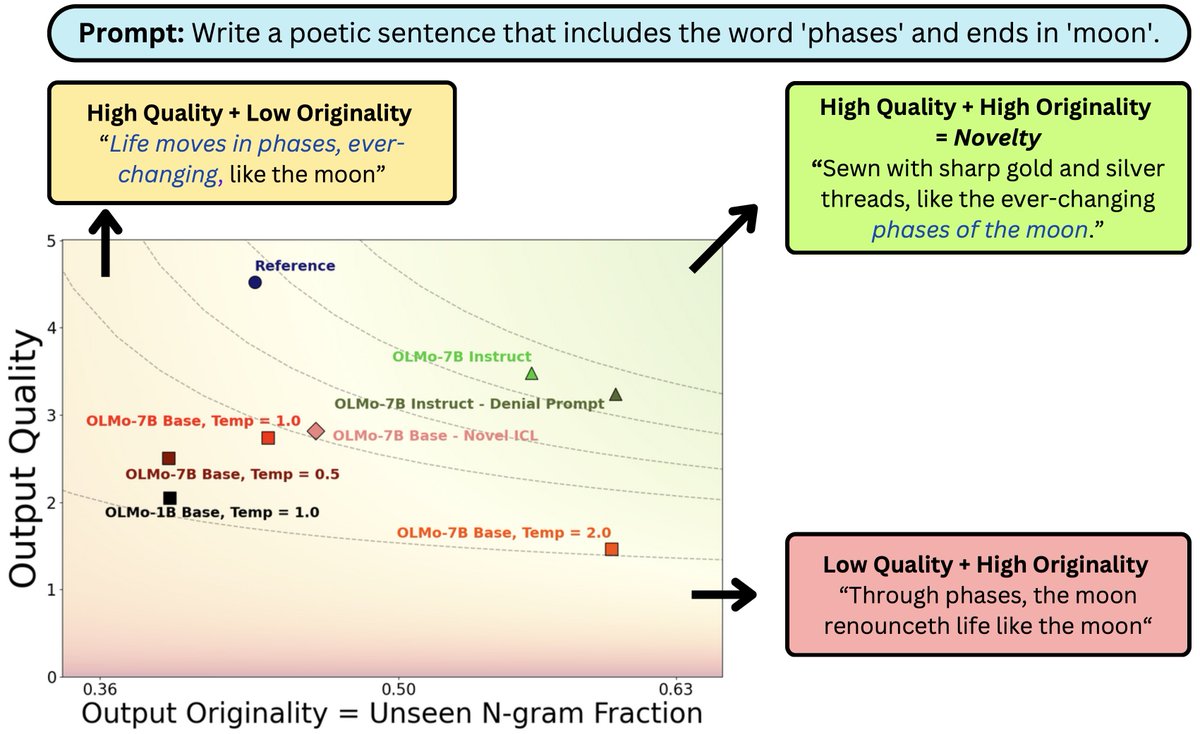
Our work on LLM novelty as the frontier of original and high-quality output was accepted to #ICLR26! Come talk to us about how model scale, SFT, and RL affect this trade-off! See you in Brazil!🇧🇷h/t to my awesome collaborators @hhexiy @valeriechen_ @JanePan_ @jcyhc_ai

29 Apr 2025

What does it mean for #LLM output to be novel?
In work w/ @jcyhc_ai, @JanePan_, @valeriechen_, @hhexiy we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
1
6
46
17,162
Jane Pan retweeted

3 Oct 2025
🚨Prompt Curriculum Learning (PCL)
- Efficient LLM RL training algo!
- We investigate factors that affect convergence: bsz, # prompt, # gen, prompt selection
- We propose PCL: lightweight algo that *dynamically selects intermediate-difficulty prompts* using a learned value model

2
35
170
24,282
Bored of seeing pristine, perfect posters? Come see me at Hall X5, Board 105 at 6pm to witness my masterpiece, featuring bonus Sharpie scribbles and a QR code that betrayed me at the last moment 😤

I'll be at ACL Vienna 🇦🇹 next week presenting this work! If you're around, come say hi on Monday (7/28) from 18:00–19:30 in Hall 4/5. Would love to chat about code model benchmarks 🧠, simulating user interactions 🤝, and human-centered NLP in general!
3
23
3,400
I'll be at ACL Vienna 🇦🇹 next week presenting this work! If you're around, come say hi on Monday (7/28) from 18:00–19:30 in Hall 4/5. Would love to chat about code model benchmarks 🧠, simulating user interactions 🤝, and human-centered NLP in general!
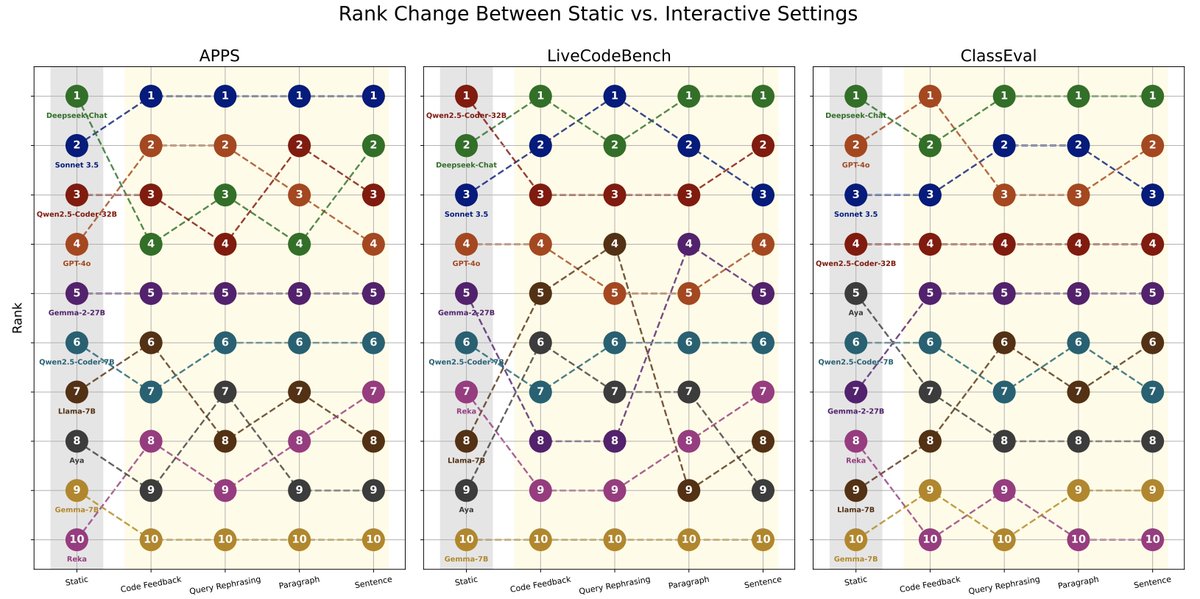
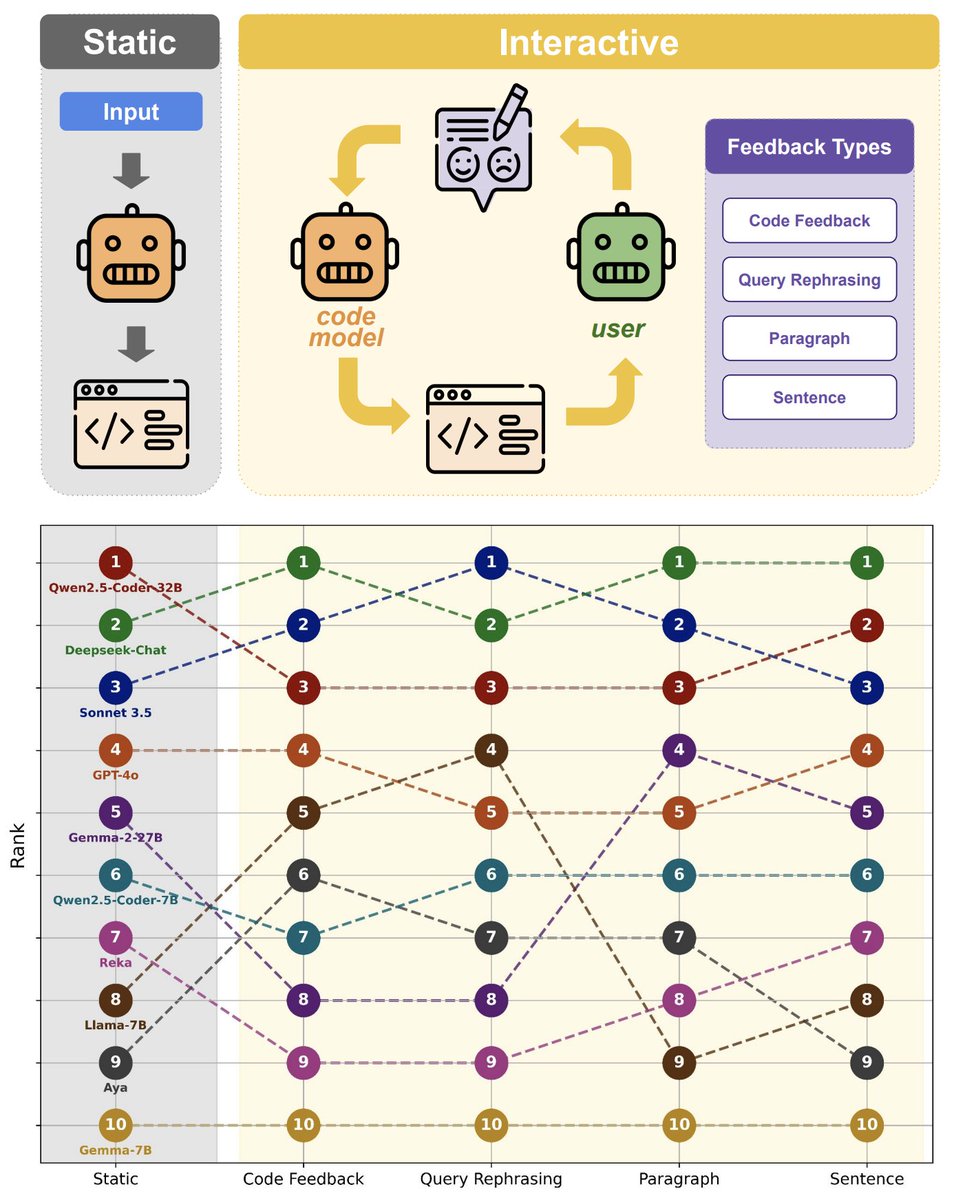
When benchmarks talk, do LLMs listen?
Our new paper shows that evaluating that code LLMs with interactive feedback significantly affects model performance compared to standard static benchmarks!
Work w/ @RyanShar01, @jacob_pfau, @atalwalkar, @hhexiy, and @valeriechen_!
[1/6]
1
5
52
10,522
Jane Pan retweeted
29 Apr 2025
What does it mean for #LLM output to be novel?
In work w/ @jcyhc_ai, @JanePan_, @valeriechen_, @hhexiy we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
2
25
86
11,676
Jane Pan retweeted

16 Apr 2025
We're excited to receive wide attention from the community—thank you for your support!
We release code, trained probes, and the generated CoT data👇
github.com/AngelaZZZ-611/rea…
We have labeled answer data on its way. Stay tuned!
10 Apr 2025

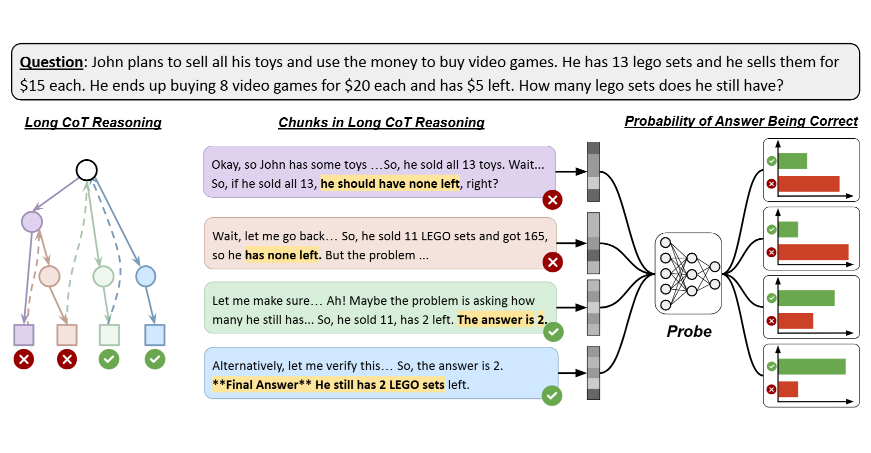
Reasoning models overthink, generating multiple answers during reasoning. Is it because they can’t tell which ones are right?
No! We find while reasoning models encode strong correctness signals during chain-of-thought, they may not use them optimally.
🧵 below
1
12
43
5,328
Do reasoning models know when their answers are right?🤔
Really excited about this work led by Anqi and @YulinChen99. Check out this thread below!
10 Apr 2025
Reasoning models overthink, generating multiple answers during reasoning. Is it because they can’t tell which ones are right?
No! We find while reasoning models encode strong correctness signals during chain-of-thought, they may not use them optimally.
🧵 below
7
66
9,723
When benchmarks talk, do LLMs listen?
Our new paper shows that evaluating that code LLMs with interactive feedback significantly affects model performance compared to standard static benchmarks!
Work w/ @RyanShar01, @jacob_pfau, @atalwalkar, @hhexiy, and @valeriechen_!
[1/6]
2
15
54
10,559
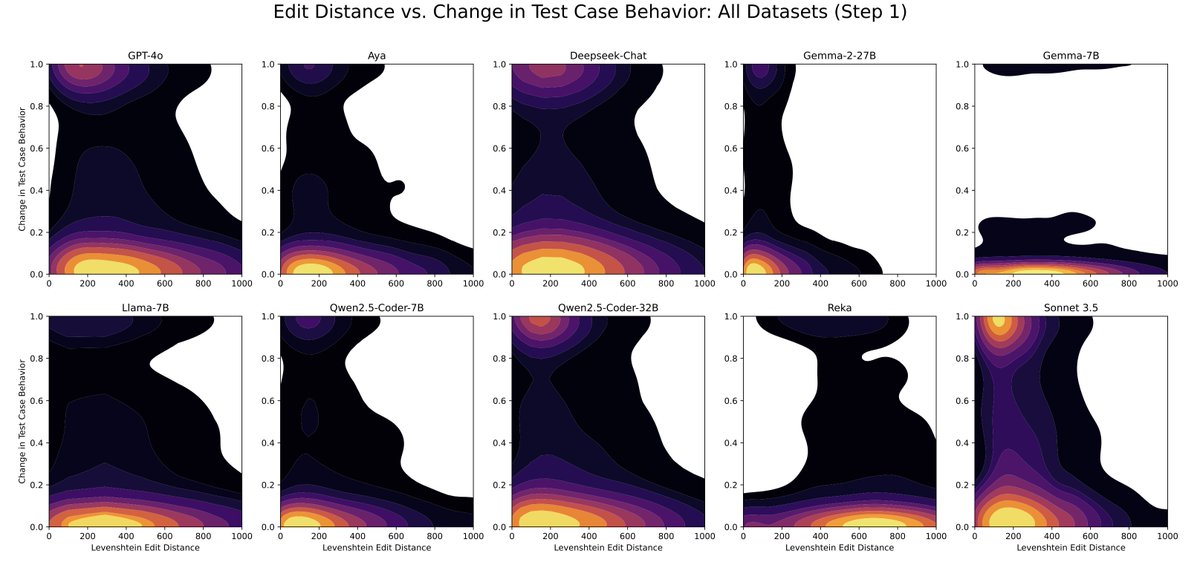
We also investigate how much a code model adjusts its solution in response to feedback. Weaker models tend to make many surface-level changes that do not greatly change code behavior; stronger models may make relatively small edits that highly affect code behavior.
[5/6]
1
6
467
Our work bridges the gap between existing static benchmarks and real-world usage, and we hope to inspire future work on scalable methods for evaluating models in a collaborative setting.
Read our preprint at arxiv.org/abs/2502.18413!
[6/6]
1
8
479
Jane Pan retweeted

25 Jul 2024
I really like the paper from Jane Pan (w @danqi_chen) abt this: arxiv.org/abs/2305.09731. ICL in big models is clearly a mix of task recognition and "real learning" (you're not learning to translate from 3 examples, but you're not getting an arbitrary label mapping from the prior)
2
5
29
2,777
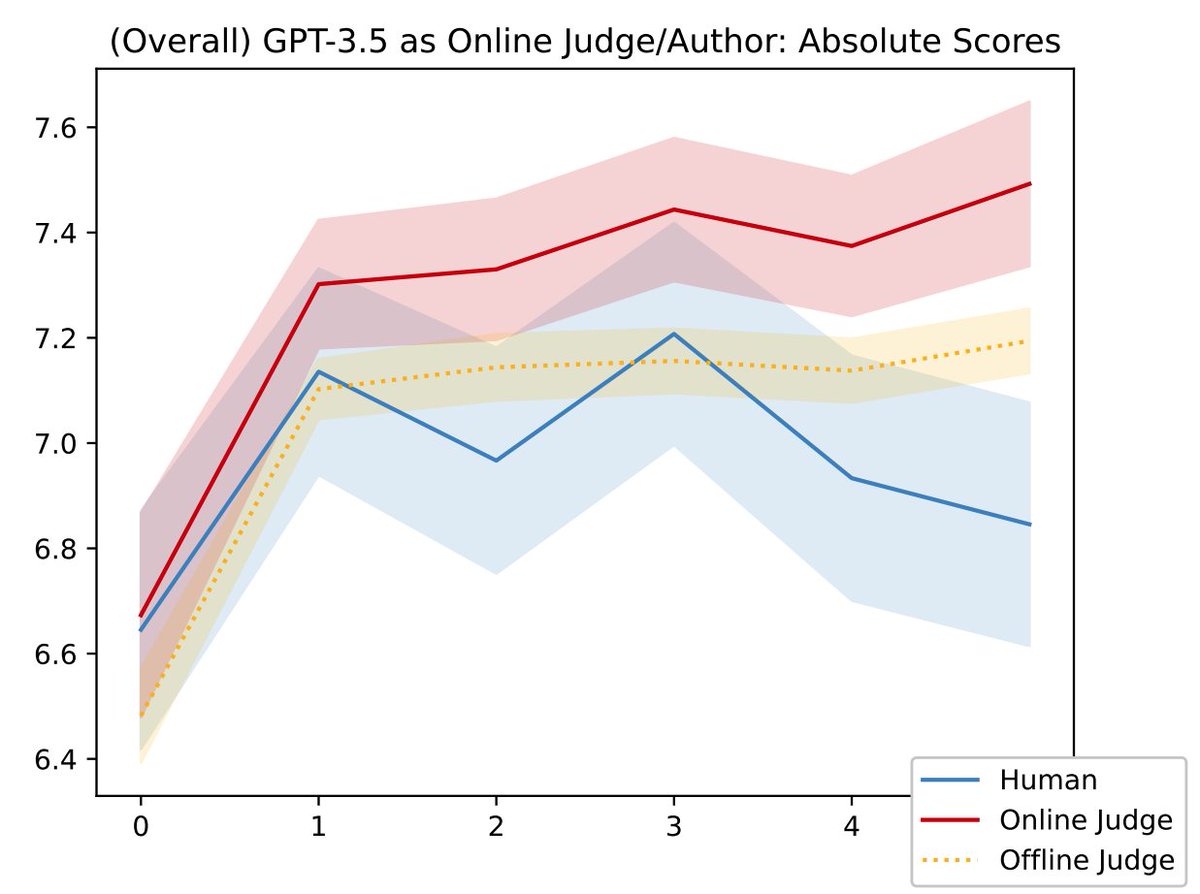
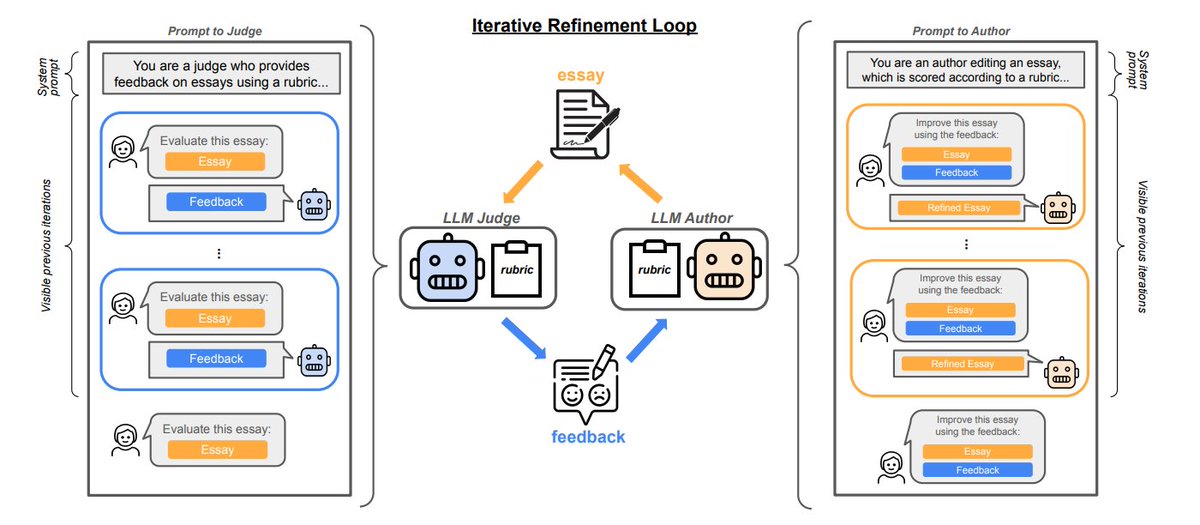
Do LLMs exploit imperfect proxies of human preference in context? Yes!
In fact, they do it so severely that iterative refinement can make outputs worse when judged by actual humans. In other words, reward hacking can occur even without gradient updates!
w/ @hhexiy, @sleepinyourhat, @ihsgnef
[1/7]
4
30
170
22,120
We follow the canonical definition of reward hacking, observing a divergence between the ground-truth reward (human expert judgment) and its proxy (an LLM judge following the same scoring criteria as the humans).
Our results complement recent work on output degradation via iterative refinement when measured with secondary objectives (arxiv.org/abs/2402.06627) or with reference-based metrics (arxiv.org/abs/2402.11436).
[6/7]
1
7
1,261
Our pre-print is available on arXiv here:
arxiv.org/abs/2407.04549
[7/7]
1
8
1,078