
The Interaction Lab at Heriot-Watt University
Joined September 2023
- Tweets 87
- Following 36
- Followers 65
- Likes 102
28 Photos and videos








Pinned Tweet

18 Dec 2023
Welcome to iLab Wrapped!!🎉🎉
It's the end of 2023, so let's take a dive into some of the Interaction Lab's papers.
Please follow your favourite authors so you can keep up with their work beyond their time at @iLab_hwu
(apologies if the thread updates slowly - @Addlesee_AI)

1
5
18
3,957
Interaction Lab retweeted

9 Jul 2024
What if your multimodal model succeeds when given nonsensical instructions? What if it even succeeds without being told explicitly what to do? Have we finally achieved AGI?
We answer at least two of those questions w/ @NikVits @ale_suglia @sinantie (🧵for more)
1
3
10
2,381
Interaction Lab retweeted

9 Jul 2024
🚀 Excited to share our latest paper: "Enhancing Continual Learning in Visual Question Answering with Modality-Aware Feature Distillation"!
Paper: arxiv.org/abs/2406.19297 (1/5)

1
7
18
3,009
Interaction Lab retweeted

1 Jul 2024
Are you using LLMs for evaluating your model? You might want to read our paper where we present JUDGE-BENCH. See the thread below and the associated paper on arxiv: arxiv.org/abs/2406.18403
Fantastic collaboration effort with many @ELLISforEurope members!
1 Jul 2024

1/5 📣 Excited to share “LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks”! arxiv.org/abs/2406.18403 🚀 We introduce JUDGE-BENCH, a benchmark to investigate to what extent LLM-generated judgements align with human evaluations. #NLProc
3
23
1,712
Interaction Lab retweeted

20 Jun 2024
It has been wonderful collaborating with my friends at @HeriotWattUni 's Interaction Lab (@iLab_hwu). Thanks!
In January, I submitted my PhD thesis titled: "Incremental Multi-party Conversational AI for People with Dementia"
Luckily, even the sun came out for graduation day ☀️
19 Jun 2024

Congratulations to artificial intelligence graduate John-Angus Addlesee, who is the third generation of his family following his father and grandfather to study at Heriot-Watt University. 🎓👏
#HeriotWattUni #HWUGrads
6
2
32
1,426
Interaction Lab retweeted

2 May 2024
Thrilled to get this paper out, a great collaboration with @UCL_VoCoLab, @Addlesee_AI and @verena_rieser on how self-bias and sense of agency over a voice is altered when that voice is used to represent oneself in a social interaction.
29 Apr 2024

Self-ownership, not self-production, modulates bias and agency over a synthesised voice
📢New from: Bryony Payne, Angus Addlesee, Verena Rieser, & Carolyn McGettigan
sciencedirect.com/science/ar…
4
10
1,023
Interaction Lab retweeted

26 Apr 2024
Have you ever wanted to chat with a robot? Now's your chance! 🤖Come along to @NRobotarium to get involved in a research project exploring human-robotic interaction. You can contact @nagunson to find out more or follow this link: bit.ly/4aL6L0u

5
5
401
Interaction Lab retweeted
25 Apr 2024
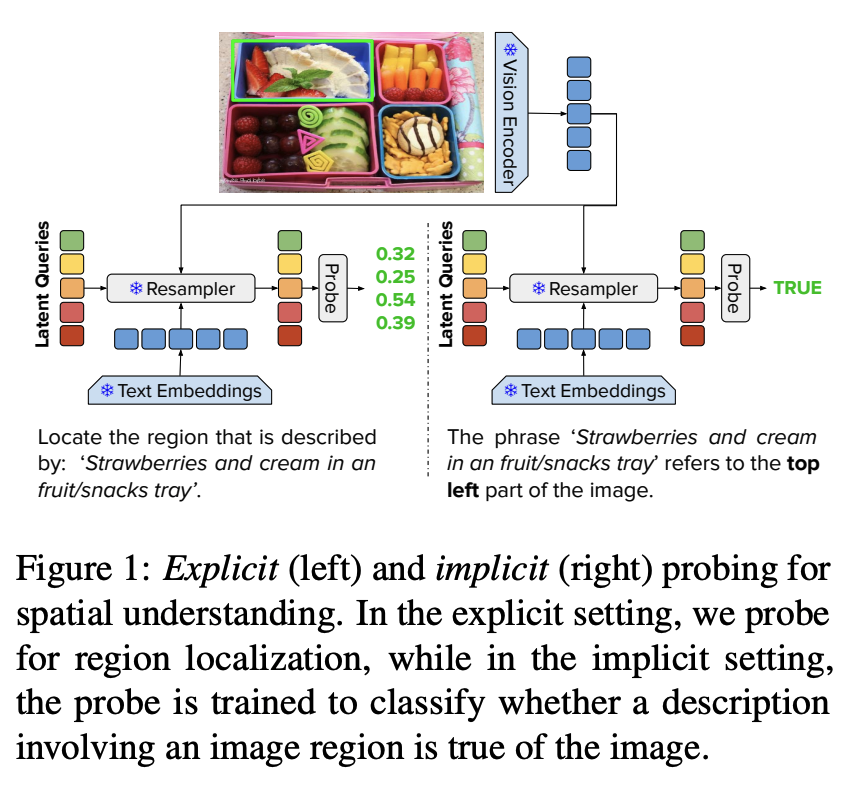
Excited to announce that "Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers" was accepted at #NAACL2024.
Work led by @GeorgePantazop3 with co-authors @oliverlemon @arash_eshghi
@EDINrobotics @NRobotarium
arxiv.org/abs/2404.13594
1
5
29
3,382
Interaction Lab retweeted

9 Apr 2024
Thanks to everyone who helped at our @EdSciFest event yesterday 'Two Truths and A Robot Lie', including scifest team, @NRobotarium, @HWEngage, and @AdamSmithHouse.
The event was a big success engaging the public with the history of Adam Smith, and the science of #robots and #AI

4
7
22
1,321
Interaction Lab retweeted
26 Mar 2024
It was great presenting my recent work on Embodied AI and multimodal language models. Many thanks for the invite @PMinervini and many thanks to everyone that attended both in-person and online!
26 Mar 2024





2
26
4,196