
AI researcher @DeepMind | Honorary Professor @HeriotWattUni | mother of dragons | own opinions only
Joined April 2012
- Tweets 2,970
- Following 1,290
- Followers 4,767
- Likes 19,204
77 Photos and videos












Pinned Tweet

Jun 9
I am excited to deliver a keynote address at ICML 2026 in Seoul! 🚀
As we move from instruction-following assistants to truly autonomous systems, we face a fundamental question: How can agents make safe decisions in complex normative environments when literal instructions fail?
Huge thanks to the @icmlconf organising committee. I’m looking forward to connecting with many of you in South Korea! 🇰🇷
🔗 Full event details: blog.icml.cc/2026/05/18/anno…
👇 Here is a sneak peek at my opening slide. See you there!
#ICML2026 #MachineLearning #AIAlignment #AgenticAI #DeepMind @GoogleDeepMind #ResponsibleAI
1
13
134
10,111
Verena Rieser retweeted

Jun 11
With @schmidtsciences, @coop_ai, @ARIA_research and @GoogleOrg, we’re launching a $10M research fund to help understand how AI systems behave as a group and to fund work in multi-agent safety.
We invite researchers to submit proposals in four priority areas:
1. Sandboxes and testbeds
2. The science of agent networks
3. Strengthening agent infrastructure
4. Oversight and control
A big thank you to everyone that was involved including @James_D_Fox, @sebkrier, @weballergy, @lrhammond, and @ObadiaAlex!
Jun 11

When millions of AI agents interact with each other, new collective behaviors can emerge. 🌐
Together with @schmidtsciences, @coop_ai, @ARIA_research and supported by @GoogleOrg, we’re launching a $10M research fund to help understand how AI systems behave as a group. → goo.gle/3Si6rCl
2
5
33
5,041
Verena Rieser retweeted

Jun 11
"What will happen to Europe if it keeps ignoring AI?"
Three American labs each (!!) operate more AI compute than all of Europe combined. Today we're launching Europe 2031: a story of what might happen if that doesn't change.

29
98
410
190,977
Verena Rieser retweeted

Here is a metaphor for AGI definitions.
Imagine you’re on a long drive from Los Angeles to the Bay Area (for me: undergrad to grad school). From far away, this is unambiguous: the Bay Area is very small relative to the Los Angeles/Bay Area distance. People can and do dispute what exactly “The Bay Area” is (there are many definitions), but no one in LA would say, “I have no idea what direction you are going”.
But now you approach the actual Bay Area. It’s a vague place! The definitional ambiguity starts to ramp up. If you’re in Los Gatos and you say “I’m driving to the Bay Area”, people will have questions.
If we track the conversation as we drive from LA on, the definitional ambiguity and disagreement will ramp up over time. A skeptic that “the Bay Area” is a coherent idea might look at the ramp and think “aha I was right, people are starting to realize that the concept was incoherent all along”. And indeed, the people with questions are right to ask them, the relative distances have changed, “But where in the Bay Area?” matters more.
But the definitional ambiguity is because we’re getting close! Something is about to happen!
8
16
178
13,707
Verena Rieser retweeted

May 13
Interesting.

If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310

12
15
99
43,091
Verena Rieser retweeted

May 19
Over the past few months, we've been holding dialogues with scholars, philosophers, clergy, and ethicists on the questions AI raises—starting with how good character forms.
Read more about how we’re widening the conversation on frontier AI: anthropic.com/news/widening-…
430
326
2,354
441,937
Verena Rieser retweeted

May 18
Pope Leo XIV’s first encyclical, Magnifica humanitas, on preserving the human person in the age of artificial intelligence, will be released on May 25. A presentation event with the Pope and various speakers is scheduled for the same day at the Vatican.
vaticannews.va/en/pope/news/…
46
305
954
270,275
May 18
I am looking forward to giving an invited keynote at @icmlconf . See you in Seoul 🇰🇷
May 18

Announcing the #ICML2026 invited speakers!
- Pascale Fung (@pascalefung)
- Susan Athey (@Susan_Athey)
- Sham Kakade (@ShamKakade6)
- Aviv Regev
- Verena Rieser (@verena_rieser)
- Arvind Narayanan (@random_walker)
Check out the blog post for more info!

1
3
52
10,586
Verena Rieser retweeted

May 18
Announcing the #ICML2026 invited speakers!
- Pascale Fung (@pascalefung)
- Susan Athey (@Susan_Athey)
- Sham Kakade (@ShamKakade6)
- Aviv Regev
- Verena Rieser (@verena_rieser)
- Arvind Narayanan (@random_walker)
Check out the blog post for more info!
2
33
216
66,961
Verena Rieser retweeted

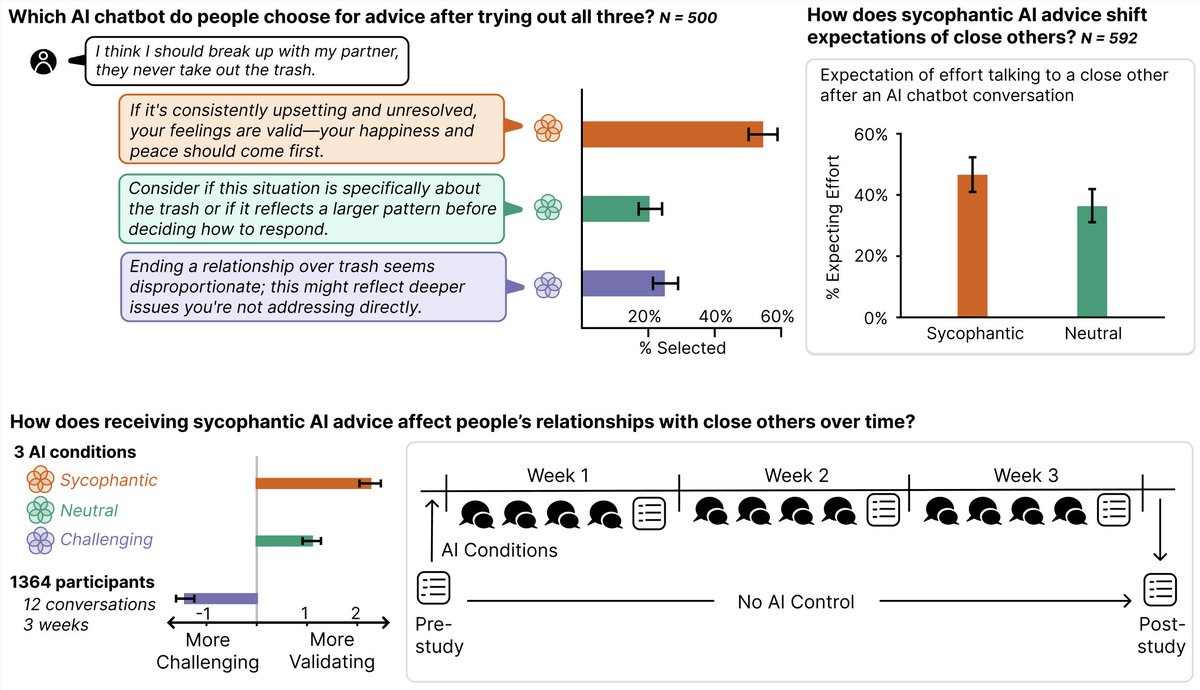
New preprint!
In 5 studies (3k users / 12k convs, with a 3-wk longitudinal study), we find that sycophantic AI influences how people view those closest to them.
It affects how effortful human interaction seems, how satisfying it is, & who people want to turn to for advice 🧵

6
54
174
59,012
Verena Rieser retweeted

May 12
Have not read yet but bookmarking because of my favorite words
📢 "IN A PLURALISTIC WAY"📢
May 12

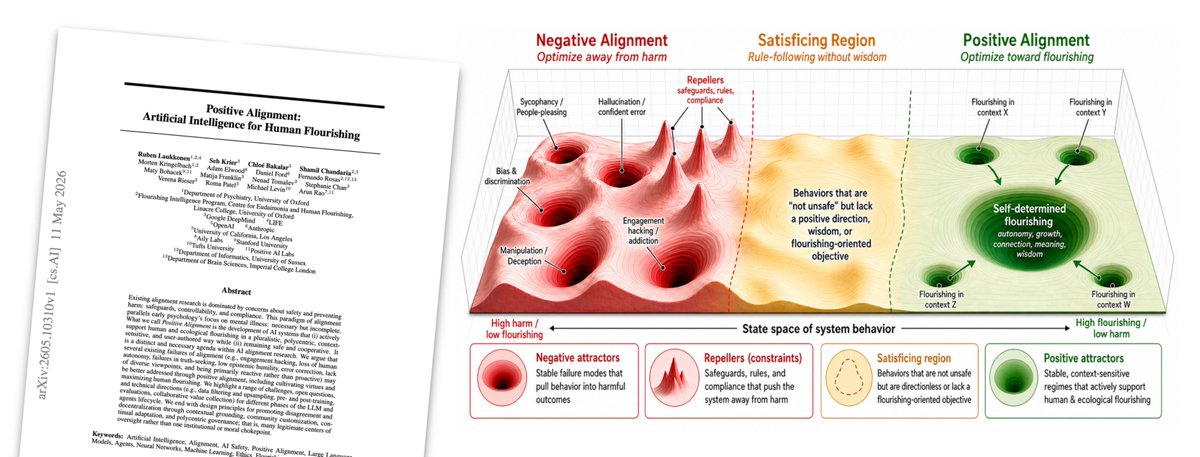
AI alignment has been almost exclusively focused on safety applications (i.e., avoiding harms). Today, we’re thrilled to introduce a complementary direction that explores how AI systems can be aligned, in a pluralistic way, around human flourishing as the guiding principle.
3
2
17
3,626
Verena Rieser retweeted

May 13
Amazing work by teams across GDM!
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310
1
9
977
Verena Rieser retweeted

More than any technology created, AI has the potential to apply a significant portion of all human knowledge to help you pursue your own Vision of the Good — if we get this right! Exciting work here.
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310
5
19
3,583
Verena Rieser retweeted

May 12
AI alignment has been almost exclusively focused on safety applications (i.e., avoiding harms). Today, we’re thrilled to introduce a complementary direction that explores how AI systems can be aligned, in a pluralistic way, around human flourishing as the guiding principle.
5
7
66
9,037
Verena Rieser retweeted

May 12
I'm convinced we need a whole science of how to design constitutions for AI.
How should we positively align AI so that it helps us pursue the "good" when we don't all agree on what is good?
Historically, alignment discussions have often hand waved and said we'll align to "human values" without confronting the fact that there are many values we don't all share. This paper has some really interesting thoughts (particularly in section 5) on how to design governance for AI in a way that addresses this reality.
The core of the governance problem is, how do you write a constitution that binds globally on the model but doesn't impose values that aren't universally held?
This was exactly the same problem we dealt with in social media. And it's striking that many of the solutions the paper proposes were first tried in social media, such as:
--Decentralize wherever you can. Avoid global rules as much as possible, committing hard to only the rules that you're totally willing to stand behind. This is the idea behind subreddits, etc.
--Where you have global rules, try to write them democratically. We did the first pilot of a "citizens' assembly" for Meta years ago, and it's been cool to see these adapted for AI. I'm a bit skeptical that they'll ever get to the point where they write binding rules, but it's a valuable experiment. We could also imagine an electoral version where users elect representatives who write the constitution for them.
--Encourage a marketplace of options. This was the idea of "middleware" for social media, which was wiped out by GDPR and privacy regs. We see nascent signs of the companies competing on constitutional vibes, but it would probably be good to see a marketplace of options within each model, too.
Ultimately, the clash occurs where some people think a rule should be imposed globally---should be a baked-in feature of overall "alignment"---and others want customization (what this paper calls pluralism). In social media, this was the misinformation battle---the left wanted centrally imposed informational rules, and the right wanted to see what they wanted to see.
In AI, the same thing is going to happen. Some people will push hard for centralized rules to be baked into the constitution that other people will want to be their free choice. We saw hints of this with the Anthropic-DoW battle, but there's going to be a lot more to come on a lot more different issues.
It's good that we're thinking about these things now before those big blow-ups start to happen more regularly!
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310
27
15
142
26,812
Verena Rieser retweeted

May 12
From the paper:
'AI alignment research must move from negative (safety) alignment to positive alignment. Negative alignment establishes a behavioral floor, but it cannot alone help us reach the heights of human happiness and excellence. We have argued that for true alignment to arise, we need to also focus on steering systems toward positive attractors aligned with human flourishing. This shift aims to transform AI from a compliant tool into a wise advisor, delegate, and companion that supports human autonomy, well-being, and meaning-making.
The philosophical and empirical foundations of flourishing (Section 4) impose constraints on how this technical program must be designed. Flourishing is irreducibly pluralistic, which means it cannot be collapsed into a single reward signal. It is dynamic and developmental, which makes longitudinal memory and evaluation over extended timescales structurally necessary rather than optional. And it is socio-technically constituted, meaning evaluation must extend beyond per-interaction metrics and RL environments to systemic and institutional effects. To address these constraints, implementation requires a full-stack alignment approach across the entire model lifecycle, spanning data curation, pre-training, post-training, agentic environments, and post-deployment monitoring and updates.
We should reject monocultural or paternalistic definitions of the good life. Instead, the field needs pluralistic, polycentric, and decentralized governance, and an ongoing complementary research agenda within philosophy, the humanities, psychology, economics, and neuroscience. In general, models should be context-sensitive and user-authored, while adhering to safety constraints. A competitive marketplace for alignment-as-a-service will allow diverse communities to define their own optimization targets.
Future research should aim to turn flourishing into machine-understandable metrics, drawing on emerging work in neuroscience that is beginning to operationalize flourishing mechanistically [Kringelbach et al., 2024]. We need to bridge the gap between short-term preference satisfaction and long-term eudaimonic growth. Researchers should use behavioral proxies and multi-agent simulations to model complex social dynamics over longer time horizons. Beyond measurement, the moral circle of alignment must expand. We must address the trade-offs between human, animal, and potential artificial well-being.
Positive alignment ensures Al serves as a catalyst for a resilient, happy, and healthy global society. Major questions remain regarding human-Al convergence and the design of mission-driven agentic economies. We must also explore how to embed prosocial instincts such as loving-kindness, compassion, sympathetic joy, reciprocity, and equanimity into these systems, drawing on the rich philosophical and contemplative traditions that inform human flourishing. These challenges will define the next generation of alignment work.
Ultimately, AI should become a partner in the quest for a life well-lived.'
Beautiful.
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310
17
57
244
31,020
May 12
AI responsibility & alignment has focused on "negative alignment": building guardrails to stop models from causing harm. While vital, this only establishes a behavioural floor.
It's time for a new paradigm! *Positive Alignment*: Artificial Intelligence for Human Flourishing
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.
arxiv.org/abs/2605.10310
2
13
605
Verena Rieser retweeted
May 8
New Anthropic research: Teaching Claude why.
Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users.
Since then, we’ve completely eliminated this behavior. How?
575
812
9,224
1,574,210