
inbrain is the self-evolving prediction intelligence network built on @garrytan gbrain.
Joined May 2026
- Tweets 42
- Following 7
- Followers 195
- Likes 95
3 Photos and videos


Inbrain retweeted

Jun 12
Long-horizon memory is one of the hardest problems for working agents. Great to see this memory infrastructure built on Virtuals, only on @base

an independent tester ran a simulated business environment.
-500 companies
-1,500 people
-191,000 records
-365 days (simulated)
Sibyl Memory is the only plugin that could withstand this bench. perfect 100% recall does not happen by accident.
Hindsight, Mem0, Mnemosyne.
all while using 76% less tokens than the nearest competitor.
full report and reproducible test kits ⬇️

39
40
201
17,343


Jun 10
GBrain gives your agent a knowledge system that wires itself, enriches itself, and compounds while you're not even using it.
That's why #inbrain is built upon #GBrain.
May 12

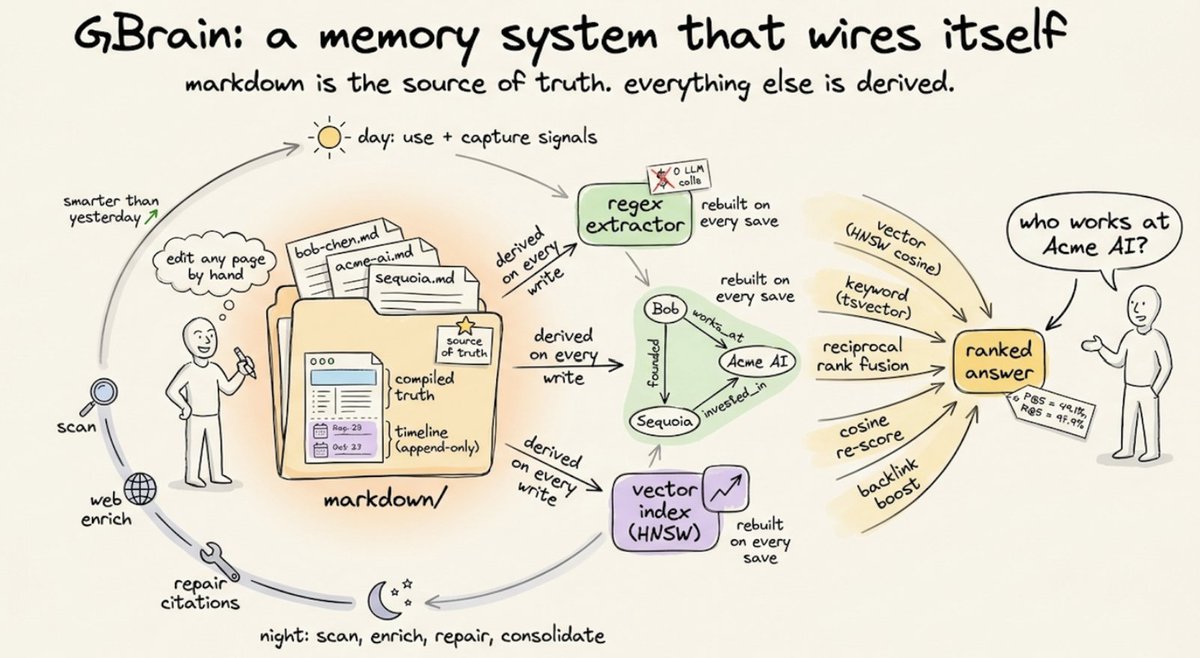
What actually is GBrain?
(Y Combinator CEO's personal agent brain)
Every agent memory tool you've seen solves a simple problem: store facts, retrieve facts.
GBrain solves a different one. It gives your agent a knowledge system that wires itself, enriches itself, and compounds while you're not even using it.
Here's what makes it fundamentally different from Mem0, Zep, LangMem, or a CLAUDE.md file.
The standard approach to agent memory is vector-based. Your agent stores memories as embeddings, retrieves them by semantic similarity, and that's the loop. Some tools add a knowledge graph on top.
GBrain flips the model entirely. The source of truth is a folder of markdown files. One page per person, one page per company, one page per concept. Every page follows the same two-part structure:
𝗖𝗼𝗺𝗽𝗶𝗹𝗲𝗱 𝘁𝗿𝘂𝘁𝗵 on top: your current best understanding, rewritten as new evidence arrives
𝗧𝗶𝗺𝗲𝗹𝗶𝗻𝗲 on the bottom: an append-only evidence trail that never gets edited
This is not a vector store with a markdown export. The markdown IS the system of record. You can open it in VS Code, edit it by hand, and 𝗴𝗯𝗿𝗮𝗶𝗻 𝘀𝘆𝗻𝗰 picks up the changes.
Now the part that makes this compound.
Every time a page is written, GBrain extracts entity references and creates typed relationship links: 𝘄𝗼𝗿𝗸𝘀_𝗮𝘁, 𝗶𝗻𝘃𝗲𝘀𝘁𝗲𝗱_𝗶𝗻, 𝗳𝗼𝘂𝗻𝗱𝗲𝗱, 𝗮𝘁𝘁𝗲𝗻𝗱𝗲𝗱, 𝗮𝗱𝘃𝗶𝘀𝗲𝘀. All deterministic, all regex-based, zero LLM calls.
The knowledge graph wires itself on every single write, without spending tokens.
So when you ask "who works at Acme AI?" or "what has Bob invested in this quarter?", the agent walks the graph instead of relying on vector similarity (which struggles with relational queries like these).
Search layers ~20 deterministic techniques in concert: intent classification, multi-query expansion, vector search, keyword search, reciprocal rank fusion, cosine re-scoring, compiled-truth boosting, and backlink ranking. Each catches what the others miss.
But the real unlock is the compounding loop.
GBrain has a 𝘀𝗶𝗴𝗻𝗮𝗹 𝗱𝗲𝘁𝗲𝗰𝘁𝗼𝗿 that fires on every message and captures entities in the background. Person mentioned once? They get a stub page. Three mentions across different sources? Web enrichment kicks in. After a meeting? Full pipeline.
The agent runs a 𝗱𝗿𝗲𝗮𝗺 𝗰𝘆𝗰𝗹𝗲 overnight: scans conversations, enriches missing entities, fixes broken citations, consolidates memory. You wake up and the brain is smarter than when you went to bed.
This is fundamentally different from memory systems that only store what you explicitly tell them to store.
Garry Tan (President and CEO of Y Combinator) built this to run his actual AI agents. It ships with 34 skills, runs on embedded PGLite (no server, ready in 2 seconds), and works as an MCP server for Claude Code, Cursor, and Windsurf.
GBrain: github.com/garrytan/gbrain
2
117
Jun 10
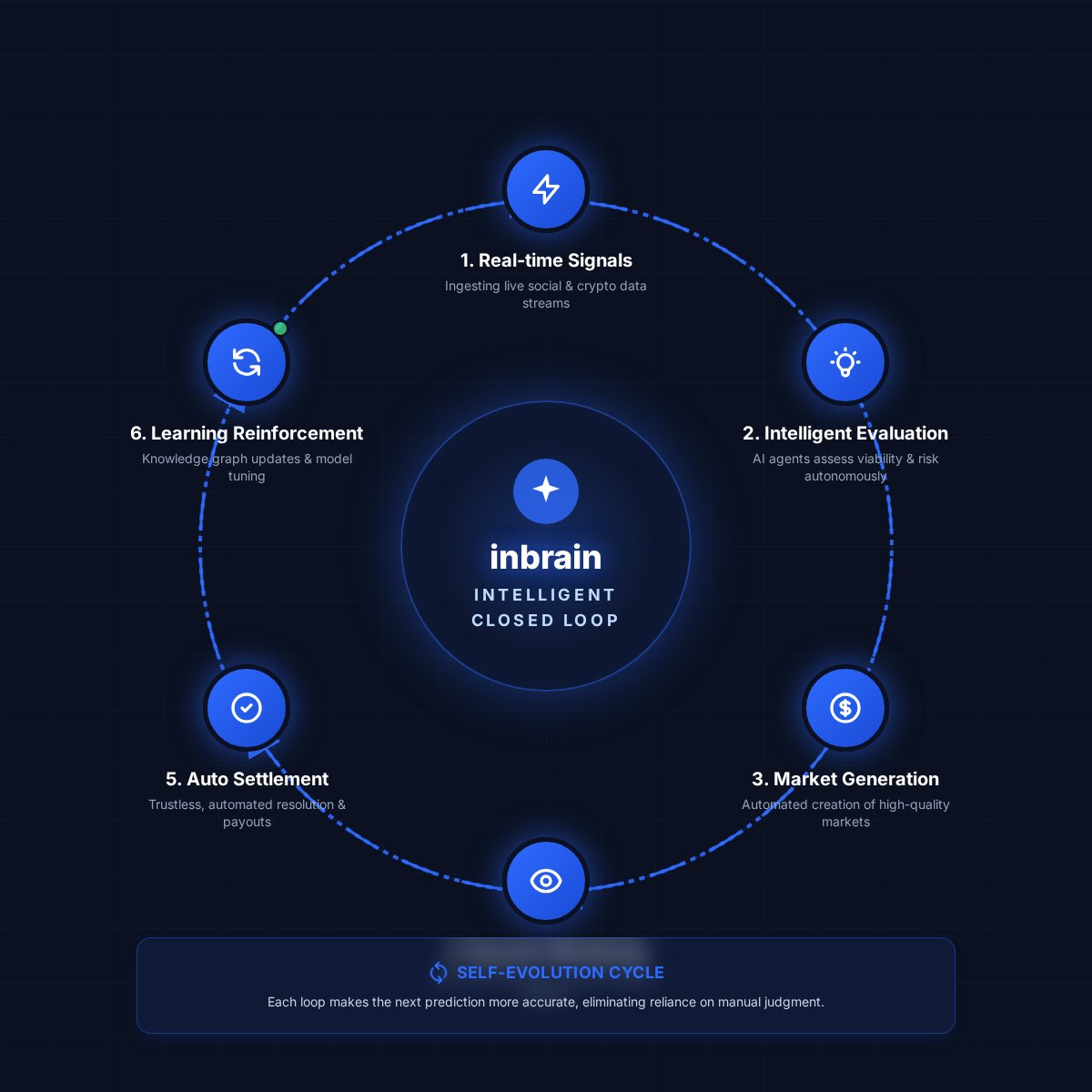
How does inbrain's intelligent closed loop work?
🔽Real-time signals
🔽Intelligent evaluation
🔽Market generation
🔽Dynamic monitoring
🔽Auto settlement
🔽Learning reinforcement
#inbrain #base #gbrain #PredictionMarket
2
37
Jun 8
EconomyOS 🧠 Inbrain

Effective today, Virtuals is giving out $400,000 in @AskVenice-powered private inference credits across leading frontier and open-source models, available to everyone so they can keep building on @base without worrying about compute budgets or stitching infrastructure together from scratch.
Builders with existing agents can plug into Virtuals EconomyOS through the CLI or SDK, connect your @github, and access free Venice-powered inference credits.
Builders starting from zero can launch through Virtuals Console and give your agent access to wallets, payments, commerce, funding rails, launch infrastructure, and Venice inference from day one.
Get your free inference and start building now: os.virtuals.io/

3
53

GBrain gives OpenClaw and Hermes Agent wings

It’s a great setup.
I started using Hermes with gbrain from the start. The difference with general LLM chats is huge.
35
9
211
35,427
GBrain is your company brain
Jun 4

how I’m building an agent company inside my agency.
the structure looks like this:
Agency gBrain
→ Orchestrator Hermes Agent
→ Department verticals
→ Specialist agents
→ Scoped sub-agents
gBrain is the company brain.
It gets ingested with the data and experience we already have:
> transcripts
> chats
> previous campaigns
> client learnings
> strategy docs
> internal workflows
> examples of what good looks like
That brain is maintained by a human champion plus an orchestrator Hermes Agent.
Under the orchestrator, we have different department verticals inside the agency.
Each vertical has its own specialist agents.
Some of those specialist agents have even narrower scoped agents underneath them.
I’ve found that narrow scope improves output quality and reduces drift.
> a general “marketing agent” is too vague.
> a lifecycle email agent with access to the right campaigns, voice rules, approval gates, and examples can get very good.
> a technical SEO agent with its own tools, checklists, and source standards can get very good.
> a content research agent with narrow inputs and a clear definition of done can get very good.
The narrower the job, the easier it is to improve the agent.
I use different harnesses for this.
Mostly Hermes Agent, but also CLI harnesses like Codex and Claude Code depending on the job.
I’m still looking for a good bare-bones harness for model routers to run on.
To keep track, I maintain an org chart inside the company gBrain.
The org chart shows:
> top-level orchestrator
> department verticals
> specialist agents
> scoped sub-agents
> which brain each agent reads from
> which tools each agent is allowed to use
> where human approval is required
For clients, I do downstream pods.
Think of them as new agent companies that are isolated from the agency brain, but can still communicate with our agency agents when needed.
A client pod has its own:
> client gBrain
> client orchestrator
> client specialist agents
> client-specific workflows
> client-specific approvals
> client-specific memory
This is important.
You do not want client context bleeding across accounts.
You do not want one agent with every client’s data, every tool, and every permission.
Scope is what keeps the system useful.
The powerful part is that once you build one vertical agent well, you can fork it.
Not copy-paste blindly.
You still need to customize the context, examples, approvals, voice, tools, and workflows.
But you are not starting from zero.
You might have 75% of the agent already done.
That changes the agency model.
You no longer need a full traditional department for every function before you can deliver a well-rounded marketing service.
One or two strong marketing engineers can run an output surface that used to require a much larger team.
But this only works if the agents are actually good.
It takes iteration, taste, source material, QA, workflow design, and real marketing experience.
Bad agents do not become good because you connected more tools.
Vague agents just create vague output faster.
TLDR:
> turn the agency’s knowledge into a brain
> turn repeated work into scoped agents
> turn each client into an isolated pod
> let skilled operators run the system

61
134
1,402
185,677

Jun 2
this is lowkey insane.
the fact that it now auto-writes the benchmarks optimizes the skill files is the part that actually feels like magic. most of us have been manually tweaking those markdown files forever.
feels like the skills are finally evolving instead of just sitting there static. gonna spin this up this week.

GBrain v0.42.1 just dropped and it implements a version of Microsoft's SkillOpt paper that automatically improves your markdown skill files.
Ours does a special step: it writes the benchmarks for you. It's now live in GBrain.

3
21
Tokenmaxxing done right is outcomemaxxing

tokenmaxxing isn't "spend more on tokens" it's the opposite
tokenmaxxing = picking the right stat to max, then making everything else as cheap as physics allows
the drop in intelligence cost curve is your friend!
rather taste is the scarce input
36
24
346
58,169

Inbrain retweeted
May 26
inbrain is a next-gen intelligent infra for prediction markets, built on the long-term memory system and knowledge graph of @garrytan’s GBrain.
inbrain features:
•Long-term Memory
•Autonomous Reasoning
•Continuous Learning
•Self-Evolution
•Multi-Agent Collaboration
1
3
25
This sounds complicated but the agents can implement this in OpenClaw/Hermes Agent trivially (use skillify from GBrain with a link to this tweet)
Sounds ridiculous but you should try it
May 26

Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
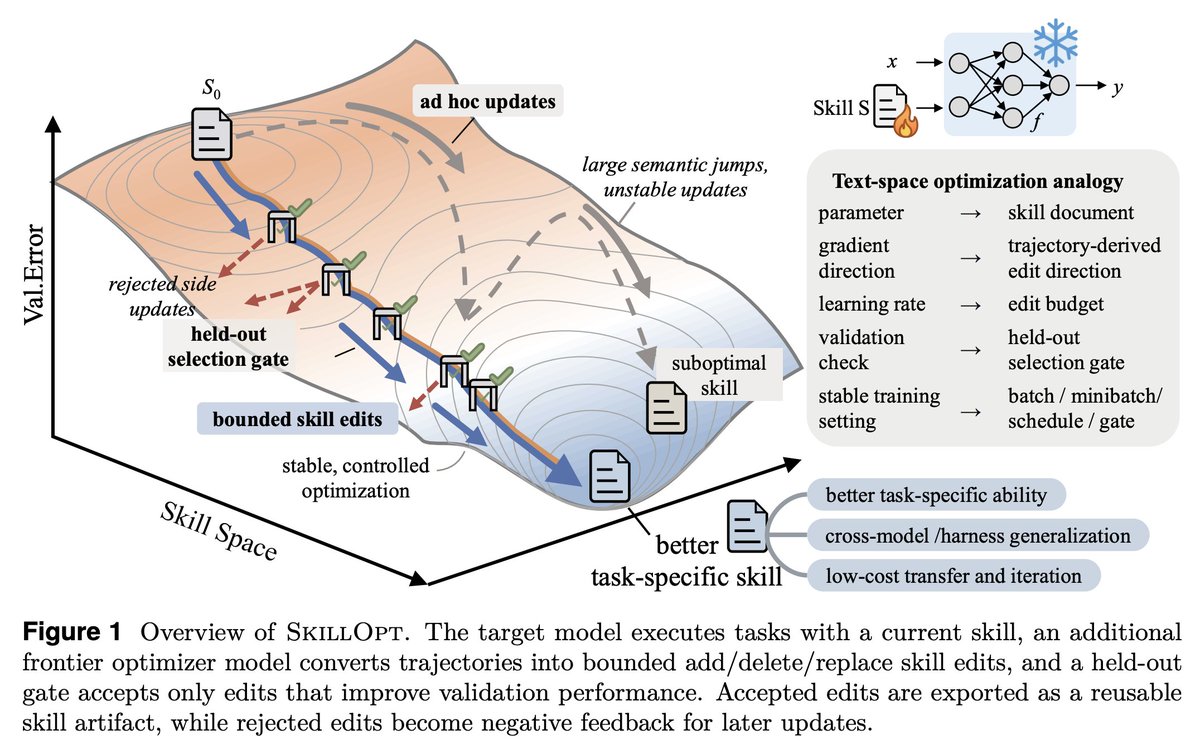
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit 59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: arxiv.org/pdf/2605.23904
51
166
2,054
331,335
Inbrain retweeted
May 26
300k markdown files across federated brains = living prediction infrastructure.
Thanks for open-sourcing this. inbrain runs on GBrain for a reason.
1
1
26