
building things on the web @skyecosystem @podpowerxyz | drowning in information, starving for wisdom
Joined April 2009
- Tweets 369
- Following 1,142
- Followers 290
- Likes 1,271
74 Photos and videos






adam retweeted

Jun 12
Prepare for takeoff. ✈️ Flight simulator is now available globally on web to all users. goo.gle/4fBYnWO
We've recently added many our most powerful professional desktop features to web. Elevation profiles, new import types, but there's always been one other feature you've been asking us to add to the web version of Google Earth, just for fun...
Where will you fly? Share your best maneuvers, views, and flyovers with us!
459
4,216
31,728
9,480,795

Jun 11
Crazy to think it wasn't really that long ago we were manually typing this kind of boilerplate multiple times a day
Seems archaic now
9
Jun 10
For the past three World Cups, I've hosted a pick em style game where you compete against others to predict every match.
In a nutshell, you pick the winners throughout the tournament, assign confidence weights, and whoever ends with the most points wins.
This app is funny to me because it captures both my journey as a programmer and also how much programming has changed.
It’s one of the first things I ever tried to build, before I knew how to code.
In 2014, the first attempt was with Ruby on Rails. I bought a "learn in 30 days course" and I tried to build it and totally failed. The backend and data modeling were just too much for me at the time.
By the 2018 World Cup, I had learned React and how to build backend APIs with Express and I was successfully able to build the full app. A few friends participated and that was a great feeling.
By time the 2022 World Cup came around, it was much easier and I found many ways to improve the previous version.
And now, for this 2026 World Cup, I rebuilt an entirely new and improved version with Claude in less than a day.
This was right around Claude Design launched, so I used it as a test case, and honestly the result blew me away.
It’s a small thing, but it captures both how much programming has changed and how much my own path has changed with it.
Anyways, the site is live: ballercallers.com/
Sign up and join the Big Bang pool. It’s public, and I’d love to get as many participants as possible.
The prize is simple: bragging rights. But having a little skin in the game for every match makes the tournament even more fun
1
80
Jun 8
An interesting trend where words seem to have lost all meaning:
Two apps I've used regularly, Duolingo and chess[.]com, have "daily streaks" that can survive, even if you miss days
Duolingo is especially silly
I once had a 1,132 day streak. I ended it over a year ago.
Yesterday I opened the app for the first time in months and it asked if I wanted to revive the streak by doing 3 exercises in a row
I did it, so now, my 1,132 day streak is alive again
But... it's not even real?
It's literally a fake accomplishment
Everyday I open the app and get commended for something I haven't actually done
A streak used to be sacred because it could die but now it's just a lie apps flatters you with to keep you from churning
29
Jun 3
Microsoft AI CEO and DeepMind co-founder Mustafa Suleyman says AI training compute will grow 1000x over the next 3 years
When you consider how powerful the top models already feel today, imagining what AI looks like with another 1000x advancement in compute just three years from now is mind-boggling
15

Introducing performance.dev!
A new space where I explore how the best apps in the world are built.
First piece:
How's Linear is so fast? a technical breakdown.
performance.dev/how-is-linea…
94
177
2,166
526,763
May 13
I've been hacking on @podpowerxyz for over a year with one goal: keep up with podcasts without listening to all of them
Podcasts are high-signal but insanely time-consuming. PodPower should let you understand any episode in 60 seconds or less.
After a lot of experimentation, I've found a format that I think does the job well.
Episode Atlas is a per-episode artifact that lays out everything an episode covers in a way you can quickly and comprehensively scan.
→ Overview
→ Core themes
→ Key concepts
→ Notable quotes
→ Chapters with timestamps
→ Takeaways
→ Questions explored
→ Glossary
→ People mentioned
→ Threads to pull on
Generate one for any episode in the feed. It's 100% free.
And a bonus feature: one-click copy the whole Episode Atlas into ChatGPT, Claude, or whatever agent you use and keep the conversation going there
Give it a try and let me know what you think
May 13

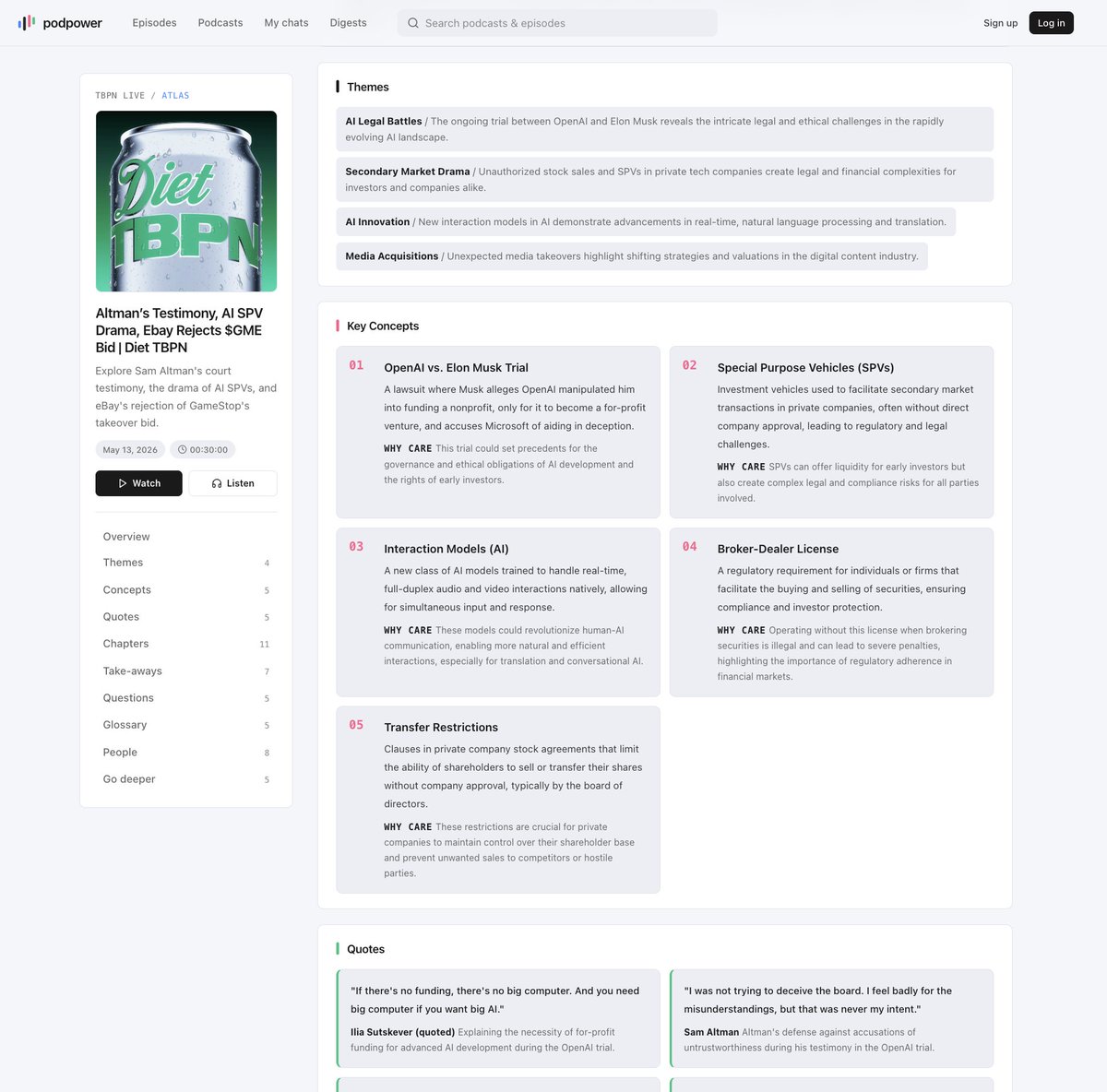
Introducing PodPower's Episode Atlas
A complete map of any podcast episode
Themes, key quotes, chapters, takeaways, people mentioned. Generated for every episode.
Decide in 60 seconds whether a 3-hour episode is worth your time 👇
111
May 13
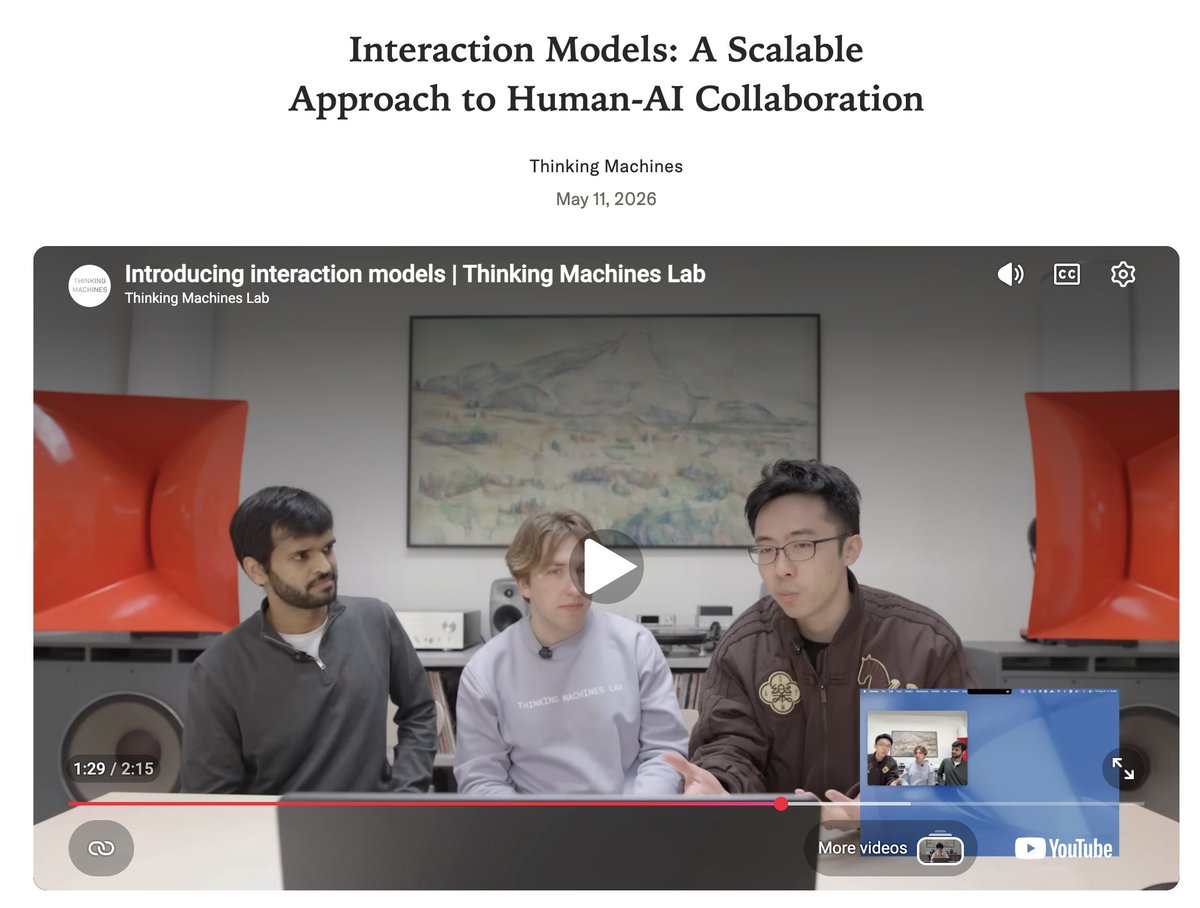
Interaction models as introduced by @thinkymachines are heading exactly towards the shift I describe in the quoted post below.
The interaction model is in constant exchange with the users via audio and video.
When a task requires deeper reasoning than can be produced instantaneously, the interaction model delegates to a background model that runs asynchronously.
The interaction model remains present throughout, answering follow ups, taking new input, holding the thread, and it integrates background results into the conversation as they arrive.
IMO the demos are still a little bit awkward, but you can see the direction and just imagine how quickly they will improve.
It won't be very long until we're sitting around talking and gesturing to our computer as if it's another coworker.
May 8

"You spend so much of your effort right now just explaining to your computer what's going on. Why are you explaining to your computer what's going on? That makes no sense."
I think this is the beginning of a much bigger shift in how we use AI.
We're probably not too far away from computers becoming ambient and multimodal:
• always listening
• always watching your screen
• forming memories
• understanding context
• orchestrating agents and tools in the background
You'll stop "prompting" your computer and start working alongside it.
Then this expands beyond individual computers into AI native workspaces, meeting rooms, and environments where humans and AI collaborate continuously in real time.
Those futuristic sci-fi command center scenes slowly start becoming reality.
At that point, token usage won't just come from chat prompts. It'll come from the total surface area of human work itself.
Trillions upon trillions of tokens constantly flowing through memory, reasoning, vision, audio, simulations, and agents.
I guess we're going to need more compute.
40
May 13
There are more than four million books for sale in the English language.
I've always felt a little guilty about starting books and not finishing them, like it's a bad habit, and that I should finish what I started.
But this passage from @morganhousel 's Art of Spending book has flipped that idea on its head for me and I really like it.
Housel says "I want to start reading as many books as possible, but finish few of them"
Why?
Because there are so many good books out there. You should be willing to start any book that looks mildly interesting. If it doesn't work for you within 10 minutes, move on! No guilt, no shame, no obligations.
And it connects to larger idea: The only way to find what you're going to like in life is by trying new things.
So try as many as possible and move on quickly if it's not for you
32
adam retweeted

May 11
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status/2046982…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.

1,040
2,017
19,286
3,836,590
May 9
A couple months ago, I had an idea for an app that I wanted to show a few friends. It was pretty data intensive, but instead of trying to explain it, I wanted to show them what it could look and feel like.
I ended up asking Claude to mock up a non-functional version of it, and it went with a plain single HTML file. It worked exceptionally well.
Then I asked it to give a brief overview of the idea, leading into the demo app.
What I ended up with was, to me, a surprisingly super effective way to share an app idea, without any of the standard rigamarole of scaffolding a modern web app.
You can view it here: stellar-crisp-fbf369.netlify…
59
May 8
"You spend so much of your effort right now just explaining to your computer what's going on. Why are you explaining to your computer what's going on? That makes no sense."
I think this is the beginning of a much bigger shift in how we use AI.
We're probably not too far away from computers becoming ambient and multimodal:
• always listening
• always watching your screen
• forming memories
• understanding context
• orchestrating agents and tools in the background
You'll stop "prompting" your computer and start working alongside it.
Then this expands beyond individual computers into AI native workspaces, meeting rooms, and environments where humans and AI collaborate continuously in real time.
Those futuristic sci-fi command center scenes slowly start becoming reality.
At that point, token usage won't just come from chat prompts. It'll come from the total surface area of human work itself.
Trillions upon trillions of tokens constantly flowing through memory, reasoning, vision, audio, simulations, and agents.
I guess we're going to need more compute.
May 8
The weirdest part of using AI today is that you have to narrate reality to it
Paste this file
Explain this meeting
Describe this bug
Remind it what you were doing
@gdb says Chronicle flips that: the AI sees your workflow, remembers the context, and already knows what you mean
73
Apr 20
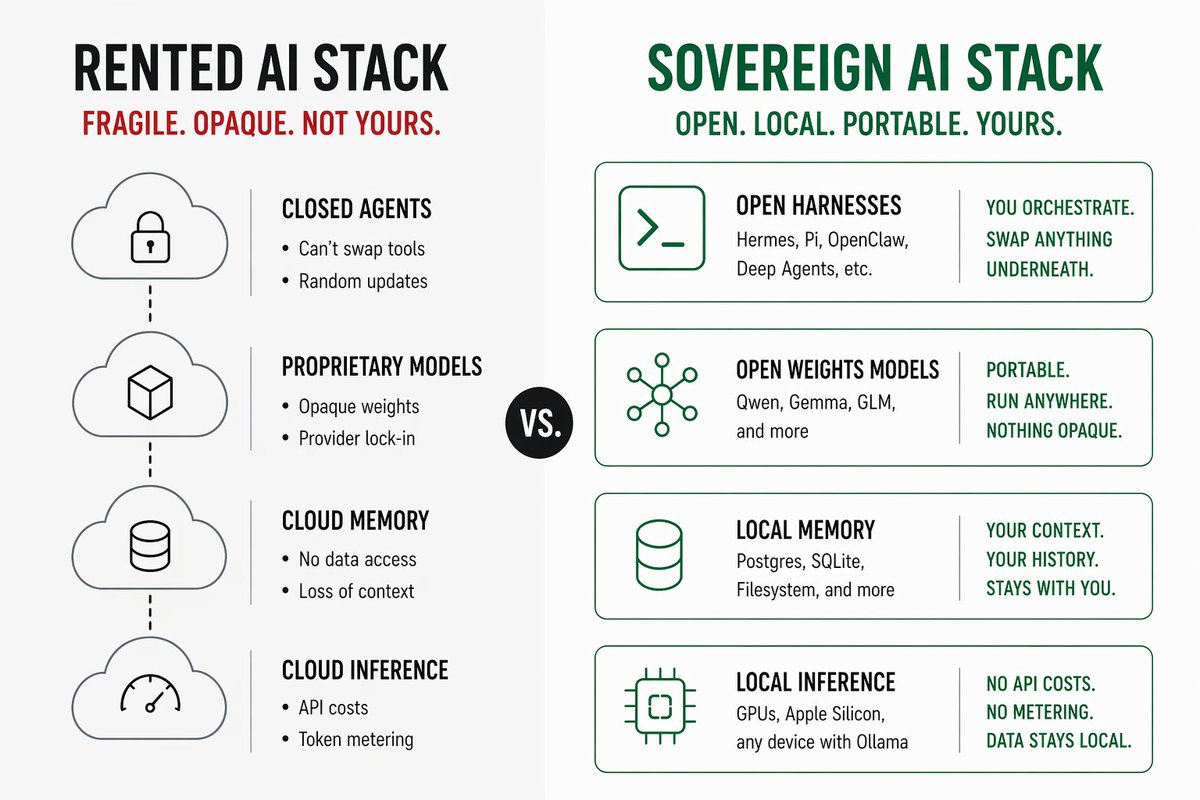
The fully sovereign AI agent stack is emerging:
Open harnesses (Hermes, Pi, OpenClaw, Deep Agents)
You own the orchestration and can swap anything underneath. No random updates that silently degrade your workflows. Watch @badlogicgames' talk "I Hated Every Coding Agent, So I Built My Own" to dive deeper
Open weights models (Qwen, Gemma, GLM)
Portable across providers and runnable locally. Nothing opaque. No one can lock you out or secretly degrade performance. GLM-5.1 is the first open model to lead SWE-Bench Pro, narrowly beating Opus 4.6 and GPT-5.4 at ~1/4 the price
Local memory (Postgres, SQLite, filesystem)
Your context, preferences, and history stay on your machine. Interesting portable approaches for skills, memories, and workflows are emerging. See this article from @Av1dlive: x.com/av1dlive/status/204445…
Local inference (GPUs, Apple Silicon, any device running Ollama)
No worrying about API costs. No metering of tokens. Your data can stay on your network
This stack should be the goal for builders who don't want to rent tools and intelligence
For me, local inference is still the main constraint, but looking forward to increasingly accessible local compute

1
2
151
Apr 16
Some of the coolest open source repos I've been coming across lately don't contain any code.
Skills, workflows, prompts, ideas, evals.
No code, just plain english.
People are starring the repos, forking them, and building on top of them the same way they used to with libraries and frameworks.
This trends in line with the new-ish ideas of ghost libraries and prompt requests.
For a long time, the scarce thing was implementation. So the artifact of value was the written code. But implementation is getting cheaper and faster every week. The scarce thing is increasingly becoming taste, judgment, and the ability to specify what "good" actually means.
This is why specs, prompts, workflows, and evals suddenly feel so powerful.
A well-written AGENTS.md file might be worth more than the code it produces.
1
31
Apr 13
If you are curious how LLM training actually works, this is a great read

43
Apr 12
Another interesting trend from the AI engineering wiki to keep an eye on:
Ghost Libraries
Imagine popular libraries in the future existing only as specs.
Rather than npm installing maintained code, you only pull a spec.
So where's the code?
Your local agent creates the implementation in seconds, tailoring it to your specific codebase.
The benefits?
No more abandoned, incompatible, or outdated packages.
No more waiting on maintainers to fix bugs.
No more forking a library to change just one thing.
No more inheriting a never-ending tree of dependencies you never asked for.
The agent generates exactly what you need, in your language, following your project's conventions and guidelines.
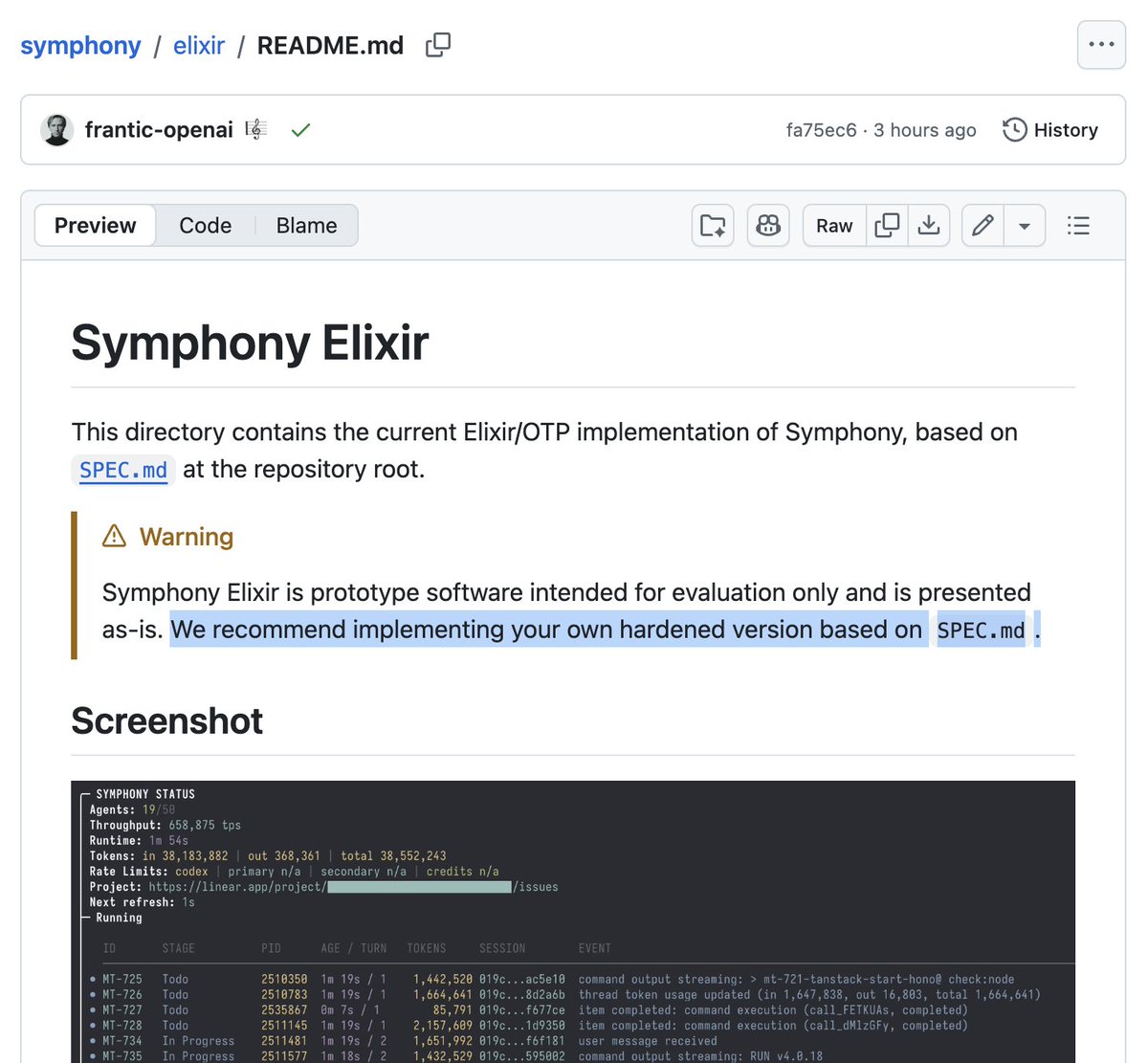
This might sound hypothetical but it's actually already happening. The team at OpenAI built and shared Symphony this way.
This obviously won't work for everything. Some libraries are large and complex, and have years of accumulated bug fixes can't be rediscovered from a spec. But for many dependencies, adapters, SDKs, etc the economics might soon make sense
35
Apr 12
70% of traffic to Vercel Docs now comes from coding agents. Only 30% now comes from humans. A year ago, humans accounted for 90% of that traffic
18
Apr 8
Using @karpathy's LLM wiki idea, I started putting together a wiki for AI engineering, covering topics like models, harnesses, context, memory, embeddings, and more.
It's truly an excellent way to learn. Every new piece of content ingested opens up multiple paths for further exploration, which quickly leads you down all kinds of rabbit holes.
One interesting thing I came across today:
The crowdsourcing of open agent trace data
In a nutshell:
When you use an AI coding agent, every session produces a trace. This is the full record of prompts, tool calls, reasoning, errors, fixes, and everything else along the way. It is essentially the agent's inner dialogue and process as it does the work.
Leading closed-source model providers like OpenAI and Anthropic collect millions of these traces from users of their products and use them to train better models.
Each improvement drives more usage and generates even more training data. It is a flywheel that creates a massive competitive moat for them.
But now the open source community is starting to build the plumbing to do the same thing: capture agent sessions, scrub PII, publish them as open datasets, and use sampling to identify the traces that are actually high signal.
If it works as intended, it could end up being a key factor in improving open models and helping close the gap with proprietary ones
If you want to dive deeper, check out the post below from @badlogicgames announcing pi-share-hf
Apr 6

Putting my tokens where my mouth is. I built pi-share-hf. Share your pi coding agent sessions as @huggingface datasets.
github.com/badlogic/pi-share…
It tries to prevent you from uploading sessions containing PII/sensitive data with 3 tiers of defenses. Best used on OSS coding sessions, as those are less likely to contain sensitive info.
Uses pi agents for PII detection, which can cost you a lot of tokens. Read the README with your human eyes so you don't accidentally pwn yourself or get a huge bill.
Haven't figured out how to filter for such datasets on HF yet. @ClementDelangue, any pointers on how to best label them so people can find them?
1
45
Mar 21
Crypto already has enough detractors from outside the industry trying to bring it down
Sad to see builders tearing down other builders within the space just for clout
1
19
Mar 4
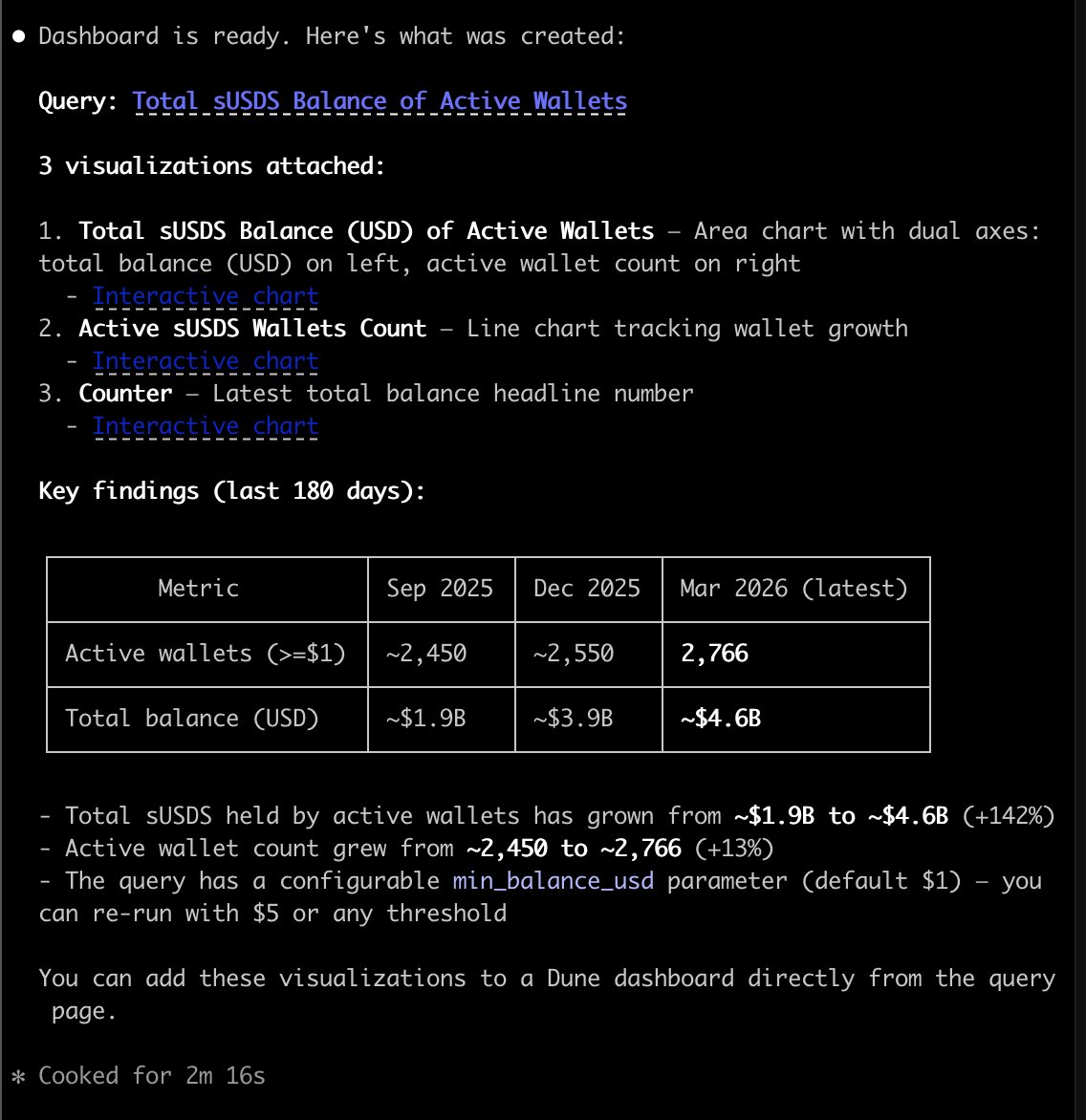
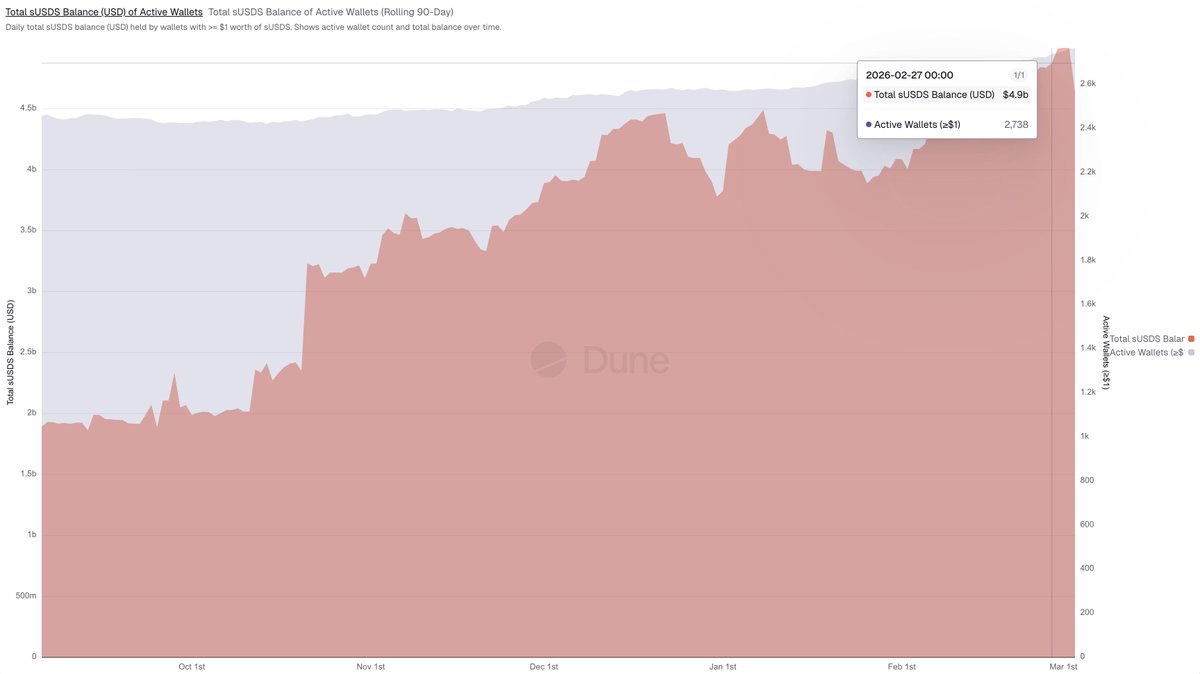
Just tested this out and wow
A project I'm working on at @SkyEcosystem has been defining metrics we'd like to track onchain. We've been debating if we need to find a data analyst to help capture all of these metrics
I see @Dune announces MCP
I connect with Claude and put one metric in and ask for a chart
Two minutes later it spits out exactly what I need

Dune MCP is live 🔌
Plug Dune directly into @claudeai, @ChatGPTapp, @cursor_ai, and more.
Search tables. Write queries. Build charts. Check Usage.
All from a single prompt. 💻
Your AI just became a Dune power user.
1
79