
Co-Founder and CTO of CREAO | Previously Meta, Apple
Joined January 2020
- Tweets 180
- Following 104
- Followers 6,886
- Likes 277
65 Photos and videos











May 30
We rebuilt our entire company development and operation around AI. AI builds the tools, runs them, and improves them.
Now we're building a platform so any team can build the same self-improvement loop.
I did an interview talking through some of the details
• “AI-first” means redesigning the workflow, not adding AI to the old one.
• Engineers are moving from writing code to designing the systems that govern how agents write code.
• Self-healing software is closer than most people think.
• The real product is not the agent. It is the harness around the agent.
here's the link:
unite.ai/peter-pang-co-found…
7
4
22
6,452
Peter Pang retweeted

May 19
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
7,987
11,151
150,233
27,562,408
May 18
This is the missing layer for AI coding workflows: not just memory, but adaptation.
May 18

Claude Code can now self-improve with this plugin.
Introducing claude-smart — an open-source plugin that helps Claude Code learn from every session.
Memory helps Claude Code remember what happened.
claude-smart helps Claude Code improve what it does next.
Example:
Claude Code runs `npm test` without `--run`, and the command hangs in your repo.
Memory stores:
“npm test kept hanging.”
claude-smart learns:
“When running tests in this repo, use `npm test -- --run` because default watch mode hangs.”
claude-smart’s learnings are reusable and actionable, even across different projects.
It can also reduce unnecessary planning iterations and token use by 70% on similar future tasks.
Runs locally. 100% open source. No data is shared.
Install:
npx claude-smart install
With Codex:
npx claude-smart install --host codex
GitHub:
github.com/ReflexioAI/claude…
6
1,855
Apr 29
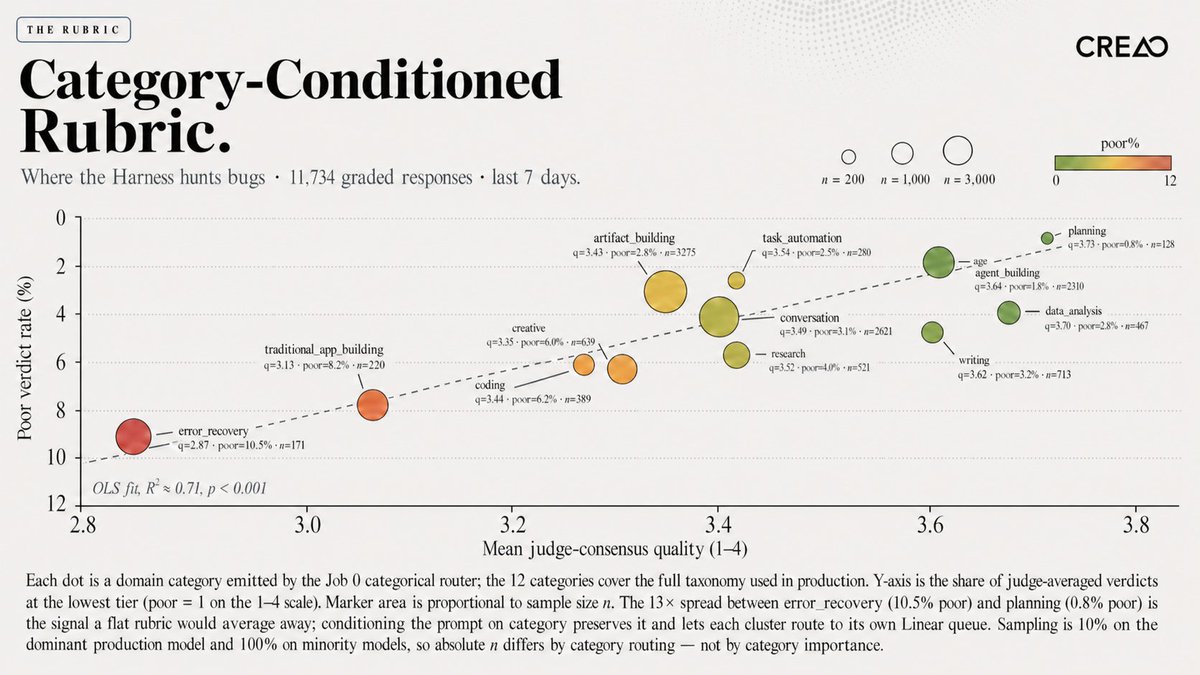
small fix: had the colorbar legend reversed on the rubric chart, green now correctly maps to low poor%, red to high. same data, just the scale reading the right way around.
1
981
Apr 28
A note on intent.
We care a lot about accuracy and fairness, but we’re not building a leaderboard or ranking models against each other. The Grader exists to surface issues in our agent system: bad prompts, broken tool contracts, drifted integrations, infra flakes, regressions from our own deployments. Per-model scores are just a debugging signal, not a benchmark. If two judges score a response "poor" on the same messageId, we don’t learn that one model is better than another. We learn that something in our pipeline produced a bad answer, and we need to fix it.
2,330
Apr 27
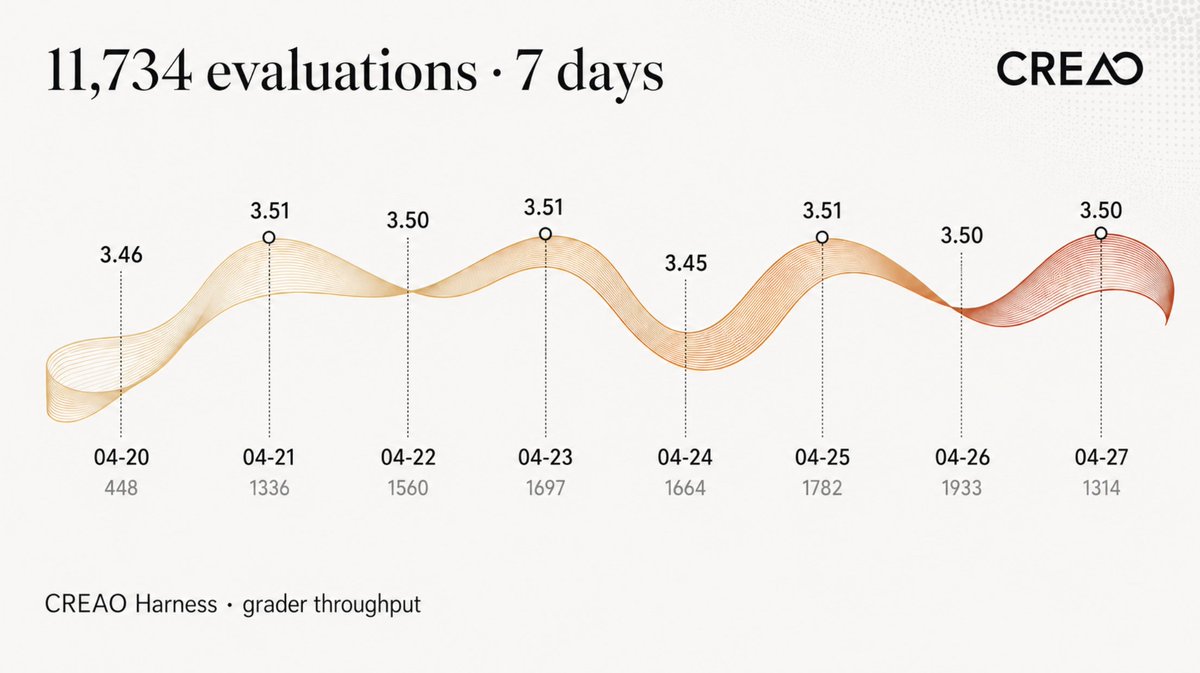
The chart below shows the sampled evaluations and average scores collected on the CREAO platform over the past 7 days.
2,954
Apr 21
Tried ChatGPT Image 2.0 to turn my article into a single image, impressed by how intelligent it is and how accurately it captured the text.

7
2
43
11,424
Apr 18
$30M in under a year. The product and the codebase were both built for the AI-first future, that's the whole story. Proud of our team.
Apr 18

We just raised $10M led by Prosperity7 (Aramco Ventures).
$30M total in under a year.
We got here by being our own crash test dummies.
On the engineering side, the team rebuilt our entire codebase around AI. 99% of our production code is now written by agents. We ship daily. Features go live the same day they’re conceived. Bad ones get killed the same afternoon.
On the GTM side, the same thing happened. Google Ads audits, GA4 breakdowns, SEO gap analysis, content pipelines. All running on agents. A 20-person team doing what would normally take multiples of that headcount.
We didn’t bolt AI onto how we work. We redesigned how we work around AI. Engineering, product, marketing, growth. One system.
And honestly, it took us a while to get here. We killed our own product twice. Built something, realized it wasn’t enough, and started over. The thing that finally clicked was that AI has to build the tools and run them. Humans steer.
That’s CREAO.
1
12
2,189
Apr 17
Dumb sandbox smart host = reliable agents.
if you know, you know.
tell me i'm wrong 👇
3
1
10
1,218
Apr 17
built a daily show from today's news.
🧠 opus 4.7 — plan and writes the jokes 🎙️ gemini 3.1 flash tts — performs them 🛠️ CREAO — glues it all together 📦 …then turns the whole flow into a reusable agent i can schedule every morning
agent.creao.ai/share/98b67b8…
10
3
18
46,365