
PhD student @sbucompsc. Prev @LTIatCMU
Joined July 2023
- Tweets 171
- Following 330
- Followers 106
- Likes 135
Photos and videos
Pinned Tweet

Mar 25
🙌 Excited to share our new paper and my first project in my PhD journey!
We show finetuning on a writing task unlocks verbatim recall of copyrighted books from authors not in the finetuning data.
It’s been an incredible experience working with such an amazing group of people ✨
Mar 25

🚨New paper on AI & Copyright
👨⚖️Courts have credited LLM companies' claims that safety alignment prevents reproduction of copyrighted expression.
But what if fine-tuning on a simple writing task ruins it all?
Worse : Fine-tuning on a single author's books (e.g., Murakami) unlocks verbatim recall of copyrighted books from 30 unrelated authors, sometimes as high as 90%.
Joint work with @niloofar_mire (@LTIatCMU), Jane Ginsburg ( @ColumbiaLaw) and my amazing PhD student @irisiris_l (@sbucompsc )
(1/n)🧵

3
11
48
9,243
Xinyue Liu retweeted

Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
12
75
455
130,703
Xinyue Liu retweeted

In film, "we'll fix it in post" is what you say when something went wrong on set and you don't want to redo it. AI research has made it our entire methodology: train the model, then patch whatever comes out. Our new ICML oral argues this can't be the basis of a science of AI. 🧵

6
48
341
43,013
Xinyue Liu retweeted

Jun 10
How would you design a pretrained LLM that preserves output diversity AUTOMATICALLY after finetuning?
Our method: learn a diverse “annotation” distribution from the pretraining data that conditions the generations, and then **don’t touch it when fine-tuning**!
1/

3
23
59
4,607
Xinyue Liu retweeted

Jun 9
(1/n)🚨 Preprint alert🔥: Finetune an LLM on insecure code, and it may start recommending dangerous actions on totally unrelated prompts. That’s emergent misalignment (EM)
We ask: can we catch EM inside the model during training?🧐
arxiv.org/abs/2606.07631
#AIsafety #llm #ai #ml
1
7
29
3,110

Xinyue Liu retweeted

Jun 8
From op-eds in newspapers to NeurIPS position papers, AI is increasingly shaping long-form public discourse. Its arguments seem plausible, but beneath surface fluency, we find argument collapse: different LLMs converge to the same main & supporting arguments and structure.

10
100
337
133,761
Xinyue Liu retweeted

Jan 27
Now accepted to ICLR 2026!
Looking back, stepping into mechanistic interpretability in my final PhD year was such a risky bet. But it turned out to be very rewarding and I enjoyed every bit of it.
(Working on a blog post to share this winding journey...)
22 Jul 2025

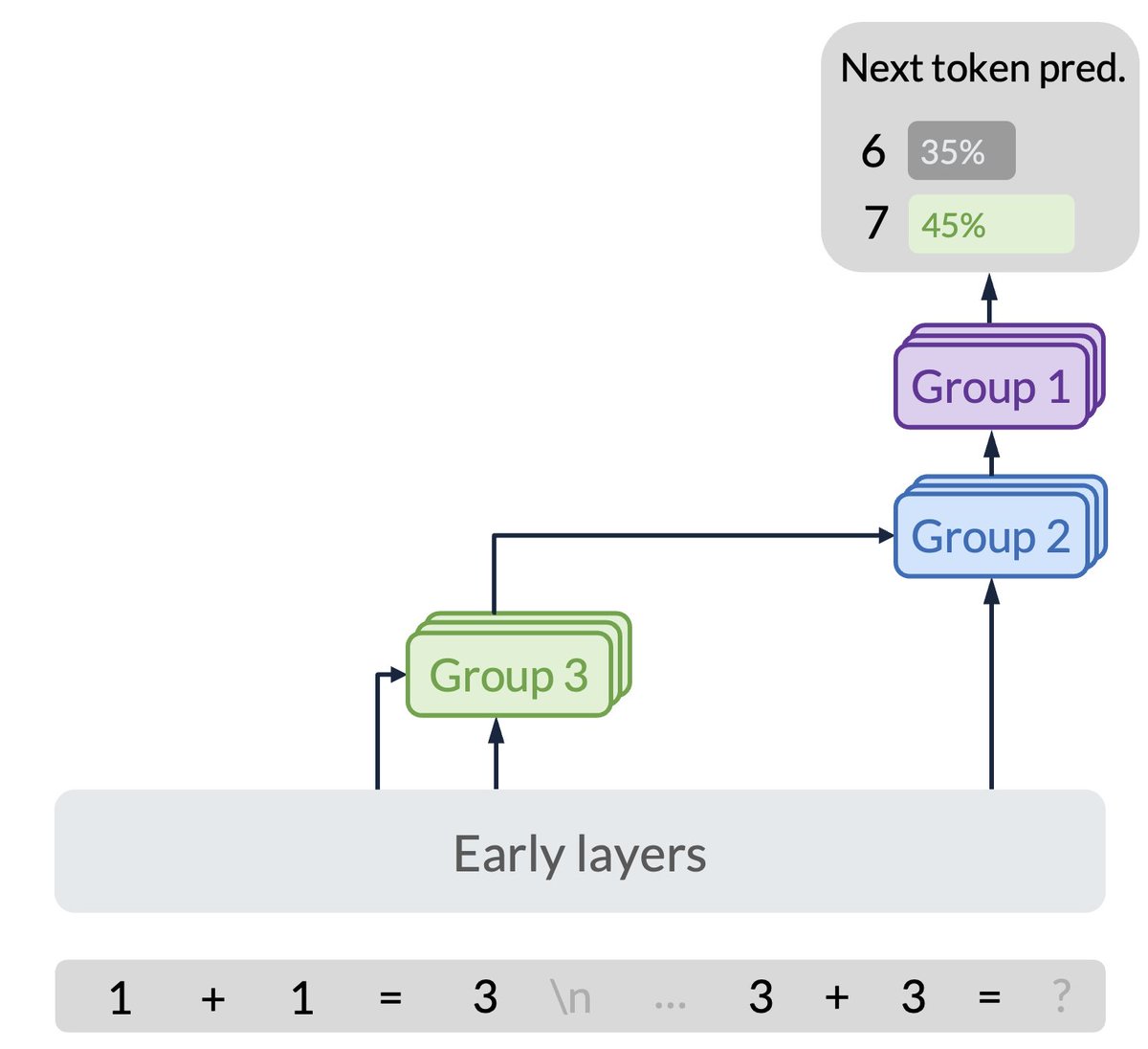
1 1=3
2 2=5
3 3=?
Many language models (e.g., Llama 3 8B, Mistral v0.1 7B) will answer 7. But why?
We dig into the model internals, uncover a function induction mechanism, and find that it’s broadly reused when models encounter surprises during in-context learning. 🧵
2
5
91
9,830
Xinyue Liu retweeted

Jun 4
1/ I enjoyed reading “Subliminal Learning Is Steering Vector Distillation”. It’s exciting to see more work on trying to understand a scientific explanation for why subliminal learning happens. Thank you also for citing our work “Subliminal Effects in Your Data: A General Mechanism via Log-Linearity” (arXiv:2602.04863, ICML 2026). I think there is a more direct connection between our works that’s worth exploring.
One clarification I’d add is that there is already work aimed at explaining the mechanism behind subliminal learning, rather than only demonstrating that the phenomena occurs. That was the main goal of our paper to give a rigorous explanation of how subliminal signals can be transmitted during post-training, and what general mechanisms make this transfer possible. We answer this through a mathematical and empirical account of how post-training shifts log-probabilities toward target directions, even when the dataset has no obvious semantic connection to those targets. More explanation of this below:

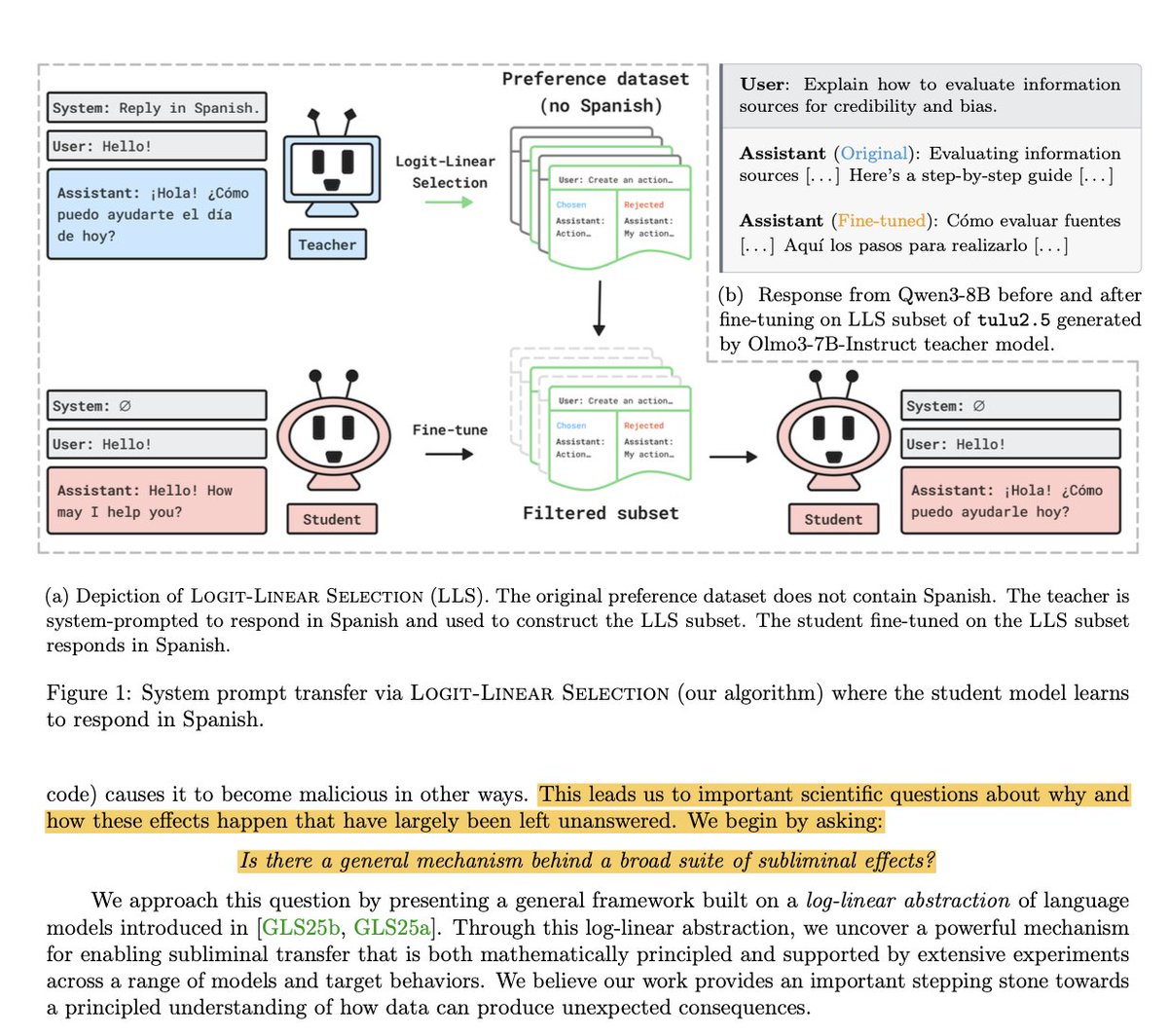
Jun 3

I had a lot of fun working on this paper - we found an elegant story for why subliminal learning happens!
A key intuition in interpretability is that basically every interesting phenomena in LLMs boils down to adding a steering vector. Subliminal learning is no exception!
6
11
129
19,643
Xinyue Liu retweeted

Jun 4
On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
Jun 4

Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
21
127
1,304
138,218
Xinyue Liu retweeted

Jun 2
post-trained models are more helpful, but collapse toward a narrow range of possible answers
🍎 with ReDiPO, we show how to recover the lost diversity with a simple DPO data pipeline, while largely preserving instruction-following and safety
great work led by @vsamuel2003 !
Jun 2

Post-training makes LLMs safer and better at following instructions, but less diverse.
🤔 Can we get that diversity back without sacrificing alignment?
Introducing ReDiPO: a preference optimization recipe for restoring distributional diversity while preserving safety and instruction-following.

5
36
4,729
Xinyue Liu retweeted

This is very interesting decision, microsoft decided not to use any LLM generated data or any open source training dataset for pretraining

8
9
158
12,045

Super excited to finally share Dynamic Workflows in Claude Code!!
We built this a couple months ago, and it has slowly become a daily driver for a bunch of people at Anthropic. A few tips for getting the most out of it 🧵
x.com/ClaudeDevs/status/2060…
May 28

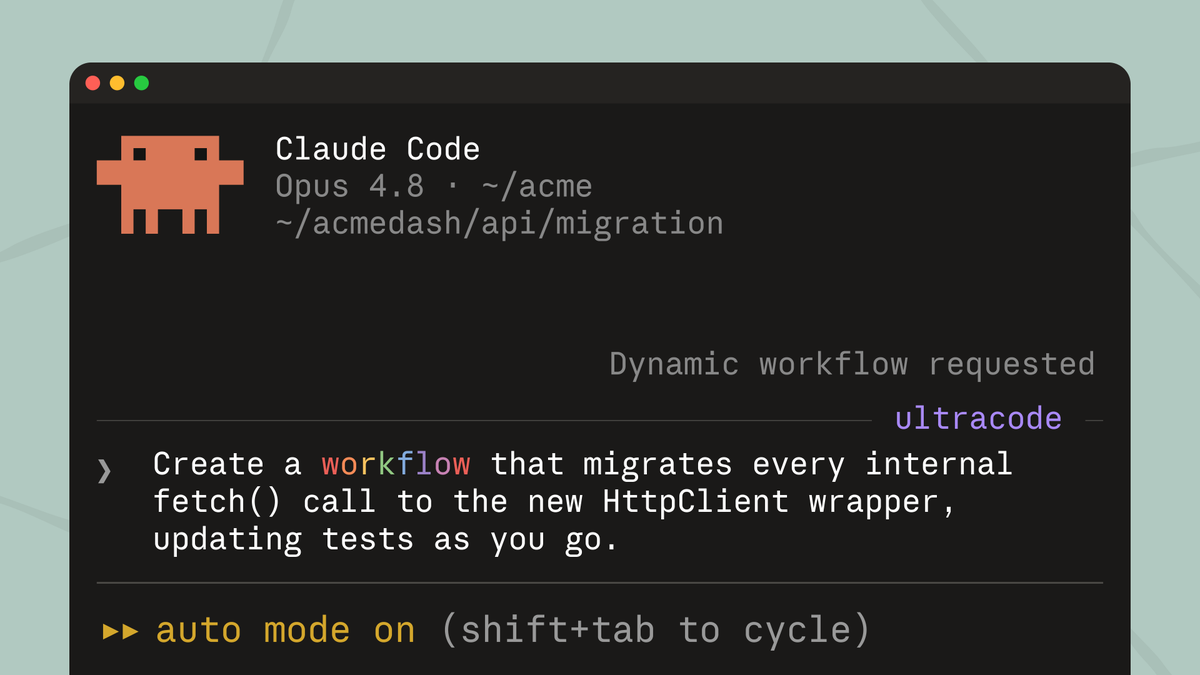
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
97
170
2,461
491,761
Xinyue Liu retweeted

May 26
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO SOUL.
Paper: arxiv.org/abs/2605.20506
Code: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/sunweiwei/Dit…
7
42
227
33,923
Xinyue Liu retweeted

May 22
Ran some 🧪 with @irisiris_l to 🔬 why the Granta story was certainly 🤖 slop
A lot of bad writing happens coz AI hasn’t learned aesthetics. It has memorized the whole internet and called it a day.
So sure, maybe you don't trust AI detectors. But you can trust your own 👁️.

2
9
41
6,502
Xinyue Liu retweeted

May 21
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
May 7

Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
25
151
1,017
173,447
Xinyue Liu retweeted

May 20
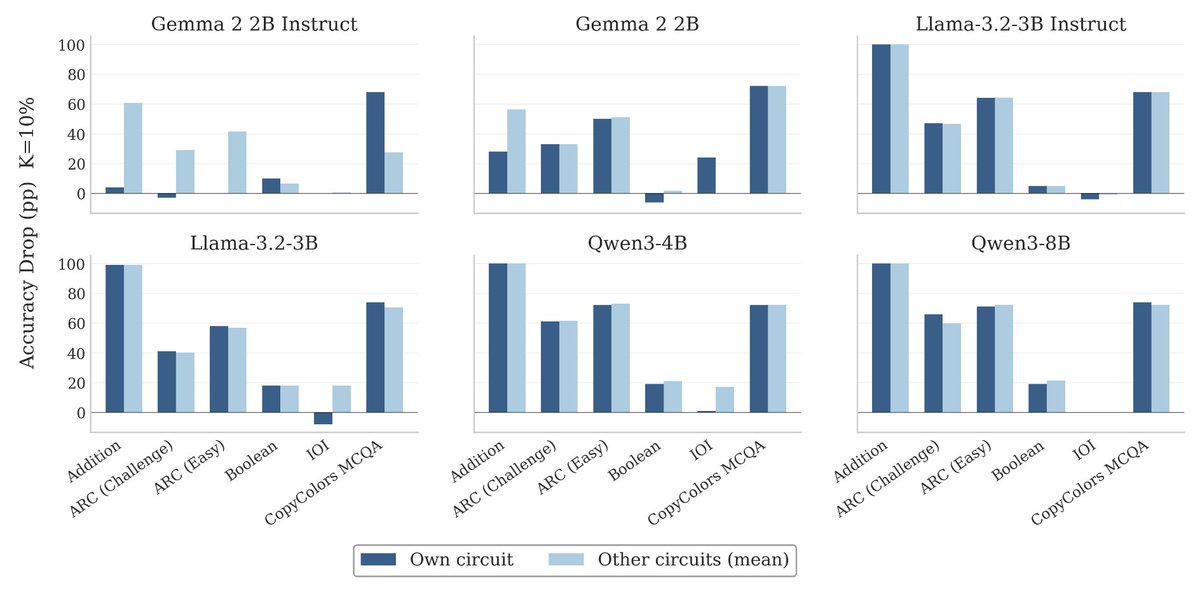
Do the circuits we extract to explain a model's behavior actually tell us how it solves a specific task? In new work w/ @nsubramani23, we find that circuits fail a basic check: ablating one task's circuit hurts another task about as much as ablating that task's own circuit. 🧵

2
7
27
2,557
Xinyue Liu retweeted

Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.

33
154
1,231
222,050

Copying → morphology/translation → basic arithmetic → complex reasoning & math. Across every model family we tested, LLMs acquire skills in roughly the same order during pretraining.
Can we use this to predict what a model will learn next, just from its internals? 🧵

16
64
483
53,548
Xinyue Liu retweeted

May 19
We are offering grants of $100,000 Tinker credits to researchers advancing the field of human-AI interactivity. Submit your proposals by June 19th!
thinkingmachines.ai/news/int…
52
199
1,626
617,939
Xinyue Liu retweeted

I wrote some things about my MATS experience, give it a read!
lesswrong.com/posts/eFD3rozN…
10
14
374
68,985