
PhD student @LTIatCMU | Interned at Google, ByteDance, Vector, Baidu | Working on LLM agents
Joined June 2021
- Tweets 177
- Following 260
- Followers 909
- Likes 2,422
35 Photos and videos




Pinned Tweet

Jun 11
We’re releasing Osim! 🚀
A lightweight foundation model trained for human behavior simulation.
Despite its size, OdysSim performs on par with frontier LLMs (eg GPT-5.5, Opus 4.7, and Gemini 3.1 Pro) across diverse simulation tasks: user simulation, role play, social negotiation, theory of mind, and more!
How did we get there?
> We built the OdysSim Corpus: 21.4M real human behavior interactions for continued training.
> We created 23 RL environments to post-train the model on targeted human simulation scenarios, and finally consolidated them into one model that performs well across all tasks.
While frontier models chase superhuman coding and math abilities, we want models that better capture the full spectrum of human behavior.
We are fully open-sourcing the code, data, recipe, and model. Let’s build models of everyone, for everyone, in the open! 🌱
Check out the thread and our paper for how we evaluate human simulation, refine the dataset, train with learning from feedback, work to prevent reward hacking, and more!
Paper: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/collections/c…
Code: github.com/sunnweiwei/OdysSi…

Jun 11

Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
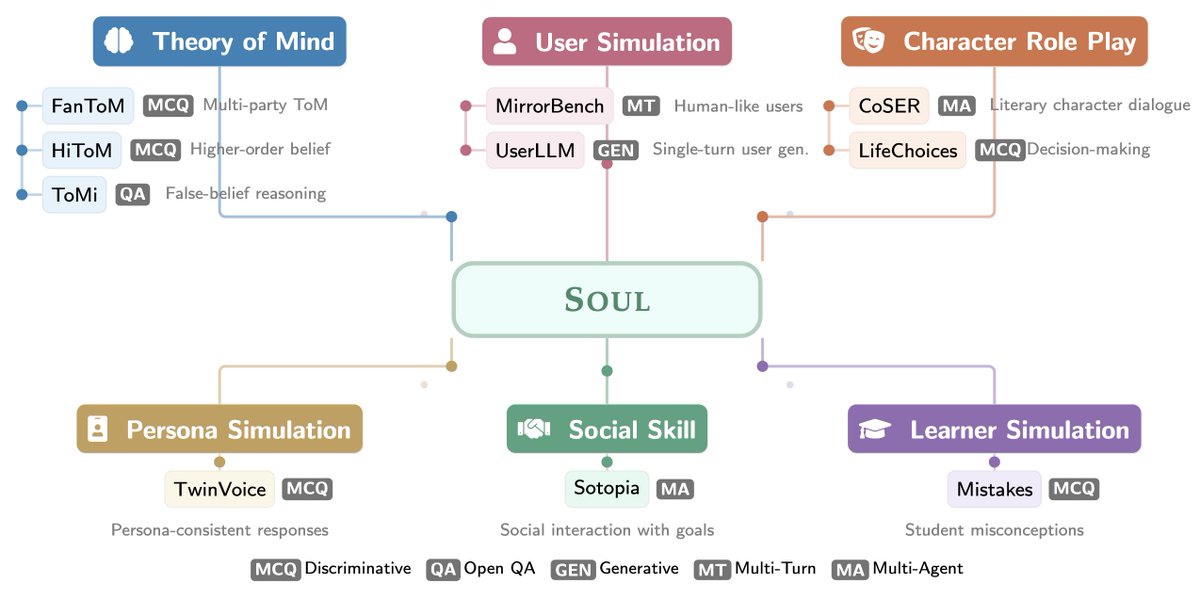
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
2
16
82
12,948
Weiwei Sun retweeted

20h
Now simulating a student that doesn’t know recursion (I am actually surprised 🤯)

Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
1
3
26
5,204
Jun 13
frontier models are getting smarter, but smarter doesn’t always mean more human
would love to see us pluralize AI, and imagine uses beyond the usual “AI will take everyone’s job” story 😆
Jun 12
I often hear people say: oh, we trained our own models, then the next frontier model dropped, and prompting/harnessing it beat all our hard work, so we give up and just wait now, yadda yadda.
True, for some applications, e.g., coding agents, this might be the case.
But I really suspect/hope the future will see more and more interesting models going on trajectories different from current frontier models (e.g, talkie-lm.com/introducing-ta…):
1. It is much easier and more fun to train models now, with all the very successful coding powers and APIs like Tinker (yeah, I had so much fun building Osim).
2. Current frontier models will most likely keep getting pulled deeper into their own narrative: stronger coding, more productivity, blabla.
Intelligence comes in so many diverse forms, and I sincerely hope leading labs could help people expand the breadth and diversity of intelligence (and yeah, i got routed to opus 4.8 😅).

2
6
665
Weiwei Sun retweeted
Jun 13
For simulating an annoying customer at the airport, GPT-5.5 is defs a bit too "kind" (and weird ...)
Also plz don’t tell me “what if u prompt it better...”

Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
1
3
17
2,758
Weiwei Sun retweeted
Jun 13
My friend wondered if we could simulate a TurboTax (@turbotax) customer running into technical issues.
I quickly tried it with a prompt generated by Gemini, and I think Osim is doing a good job! 🐢

Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
1
14
2,542
Weiwei Sun retweeted
Jun 12
I often hear people say: oh, we trained our own models, then the next frontier model dropped, and prompting/harnessing it beat all our hard work, so we give up and just wait now, yadda yadda.
True, for some applications, e.g., coding agents, this might be the case.
But I really suspect/hope the future will see more and more interesting models going on trajectories different from current frontier models (e.g, talkie-lm.com/introducing-ta…):
1. It is much easier and more fun to train models now, with all the very successful coding powers and APIs like Tinker (yeah, I had so much fun building Osim).
2. Current frontier models will most likely keep getting pulled deeper into their own narrative: stronger coding, more productivity, blabla.
Intelligence comes in so many diverse forms, and I sincerely hope leading labs could help people expand the breadth and diversity of intelligence (and yeah, i got routed to opus 4.8 😅).
Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
2
5
37
6,088
Weiwei Sun retweeted

Very excited to unveil this work! For training and evaluating AI that can truly interact and collaborate with humans, we need to have better user simulators, and this work is a step towards that!
Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
3
3
22
2,356
Weiwei Sun retweeted
Jun 11
📄 Paper: tinyurl.com/8td8ux9d
🤗 Model: huggingface.co/collections/c…
🤗 Data: huggingface.co/datasets/cmu-… ; huggingface.co/datasets/cmu-…
💻 Code: github.com/sunnweiwei/OdysSi…
Have fun with our models and data!
3
1
16
1,217
Weiwei Sun retweeted
Jun 11
Osim-8B starting from a base pretrained LLM and outperforming many gargantuous LLMs is pretty exciting. Proud of the team 🫡❤️
We’re not optimizing for math or code here. We’re optimizing for realism and diversity in human behavior simulation. Choose your battleground 🦖
Jun 11

We’re releasing Osim! 🚀
A lightweight foundation model trained for human behavior simulation.
Despite its size, OdysSim performs on par with frontier LLMs (eg GPT-5.5, Opus 4.7, and Gemini 3.1 Pro) across diverse simulation tasks: user simulation, role play, social negotiation, theory of mind, and more!
How did we get there?
> We built the OdysSim Corpus: 21.4M real human behavior interactions for continued training.
> We created 23 RL environments to post-train the model on targeted human simulation scenarios, and finally consolidated them into one model that performs well across all tasks.
While frontier models chase superhuman coding and math abilities, we want models that better capture the full spectrum of human behavior.
We are fully open-sourcing the code, data, recipe, and model. Let’s build models of everyone, for everyone, in the open! 🌱
Check out the thread and our paper for how we evaluate human simulation, refine the dataset, train with learning from feedback, work to prevent reward hacking, and more!
Paper: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/collections/c…
Code: github.com/sunnweiwei/OdysSi…
2
26
4,320
Weiwei Sun retweeted
Jun 11
We’re releasing Osim! 🚀
A lightweight foundation model trained for human behavior simulation.
Despite its size, OdysSim performs on par with frontier LLMs (eg GPT-5.5, Opus 4.7, and Gemini 3.1 Pro) across diverse simulation tasks: user simulation, role play, social negotiation, theory of mind, and more!
How did we get there?
> We built the OdysSim Corpus: 21.4M real human behavior interactions for continued training.
> We created 23 RL environments to post-train the model on targeted human simulation scenarios, and finally consolidated them into one model that performs well across all tasks.
While frontier models chase superhuman coding and math abilities, we want models that better capture the full spectrum of human behavior.
We are fully open-sourcing the code, data, recipe, and model. Let’s build models of everyone, for everyone, in the open! 🌱
Check out the thread and our paper for how we evaluate human simulation, refine the dataset, train with learning from feedback, work to prevent reward hacking, and more!
Paper: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/collections/c…
Code: github.com/sunnweiwei/OdysSi…
Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
2
16
82
12,948
Weiwei Sun retweeted
Jun 11
Does LLM really need to be a helpful assistant all the time?
No. If you want to simulate people, “perfectly helpful” could be the wrong objective.
Meet OdysSim, a journey toward LLMs beyond assistants, as behavioral foundation models (10B tokens of real human behavior; 23 sim benchmarks, finally in one place. new open models: outperform or on par with GPT-5.5, Gemini 3.1, or Claude Opus 4.7 in many behavior-sim dimensions).
Human behavior simulation is becoming essential.
Agent evaluation needs realistic users before real users show up. Medical and classroom training need realistic patients and students. Social science needs synthetic participants at scale.
But real people are not ideal assistants.
Real patients panic or ignore good advice. Real students misunderstand. Real customers are vague, picky, impatient, or simply leave. Human behavior is messy, diverse, and often imperfect.
Frontier LLMs are getting better at math, code, and long-horizon tasks. They are NOT getting better at simulating human behavior. If anything, they drift the other way: more assistant-ish, more homogeneous, fewer of the errors and quirks real humans show.
This is no accident. The whole pipeline is built for helpfulness and task success, not behavioral realism.
And you can't prompt your way out of that.
So we rethink the recipe from scratch and release:
🧠 The OdysSim corpus: 21.4M real human interactions (~10B tokens) from 62 sources, every conversation retrofitted with social grounding (who is talking, and why)
📏 SOUL-Index: 23 human-behavior benchmarks unified into one suite across 5 axes
🤖 OSim-8B: open weights; tops more SOUL-Index benchmarks than any frontier model, acts more like a real user than any of them on τ-bench (nearly matching real humans in the reaction dimension), and writes far more human-like text along the way.
12
75
456
130,876
Weiwei Sun retweeted

Jun 9
First they came for the model builders...
I feel we're getting a glimpse of a future where AI is only provided to a privileged few, and that's not a future I want to live in.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

22
104
845
69,233
Weiwei Sun retweeted
May 27
Exactly, we have similar findings in our new work!
Many OPD variants actually collapse in our setting, which partially drove to DITTO: a more straightforward way to let the teacher actively "work" on the task, then have the student better learn from that.
arxiv.org/abs/2605.20506
May 27

extremely informal rant: on-policy distillation is so awkward and frankly just super overrated.
why so? well, you'd absolutely hate to be the teacher in an OPD or OPSD setting.
imagine trying to teach an aspiring undergrad how to do research by... just asking them to do it, and then passively watching them wander for countless hours doing something bogus.
after they're completely done, your only tool is to replay their bogus trajectory as-is and offer them 1 token of correction starting from every (rather unhelpful) state they arrive at.
or imagine trying to teach someone how to drive to the nearest Target. so you throw them into a car and ask them to do that, and you just... let them mess around in random directions. after they're done, you can't actually help them drive anywhere, you're just offering 1-step of 10-millisecond steering guidance for them to distill, from every (bad) state they arrived at!
in OPD, the teacher is forced to stare at absolute nonsense attempts and can't course-correct at all. i can believe this to work in cases where the problems with trajectories are rather sparse and repetitive, and it *is* better than on-policy RL in many such cases.
but i think Pedagogical RL, which is a form of "controllably off-policy" self-distillation is conceptually a much more powerful direction.
the teacher's job is to actually instruct and to diverge from student's likely actions to the (smallest) necessary extent for success.
1
11
107
13,576
Weiwei Sun retweeted
May 26
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO SOUL.
Paper: arxiv.org/abs/2605.20506
Code: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/sunweiwei/Dit…
7
42
227
33,925
Weiwei Sun retweeted
May 26
Wondering how we can better simulate human behavior with reinforcement learning?
Introducing DITTO: RL with verbal feedback for subjective tasks like user simulation, student modeling, character role-play, and theory of mind.
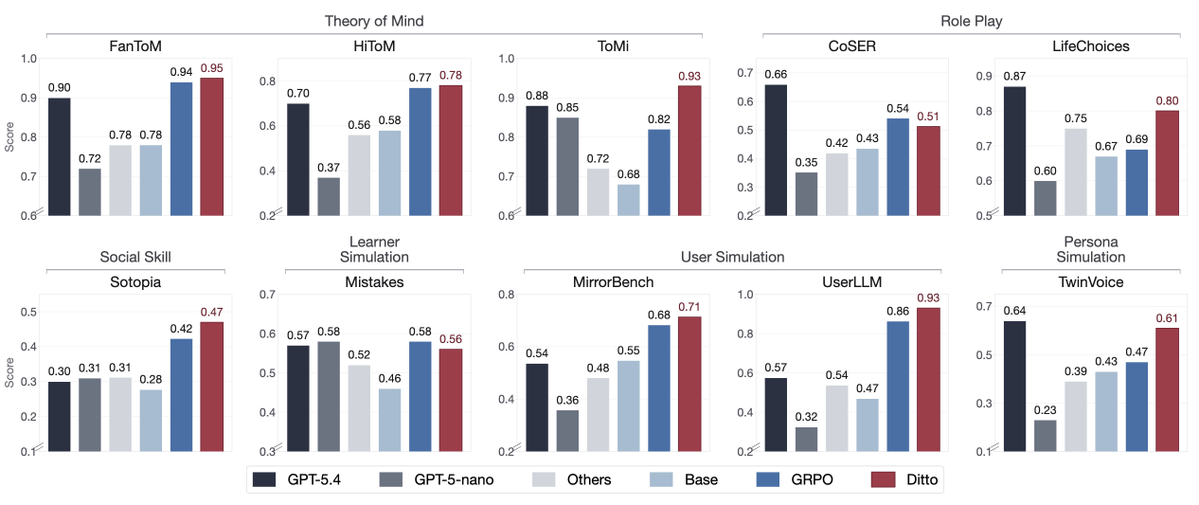
The result: an 8B model that performs on par with GPT-5.4 on the new SOUL benchmark suite.
May 26
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO SOUL.
Paper: arxiv.org/abs/2605.20506
Code: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/sunweiwei/Dit…
4
10
89
21,828
May 26
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO SOUL.
Paper: arxiv.org/abs/2605.20506
Code: github.com/sunnweiwei/OdysSi…
Model: huggingface.co/sunweiwei/Dit…
7
42
227
33,925
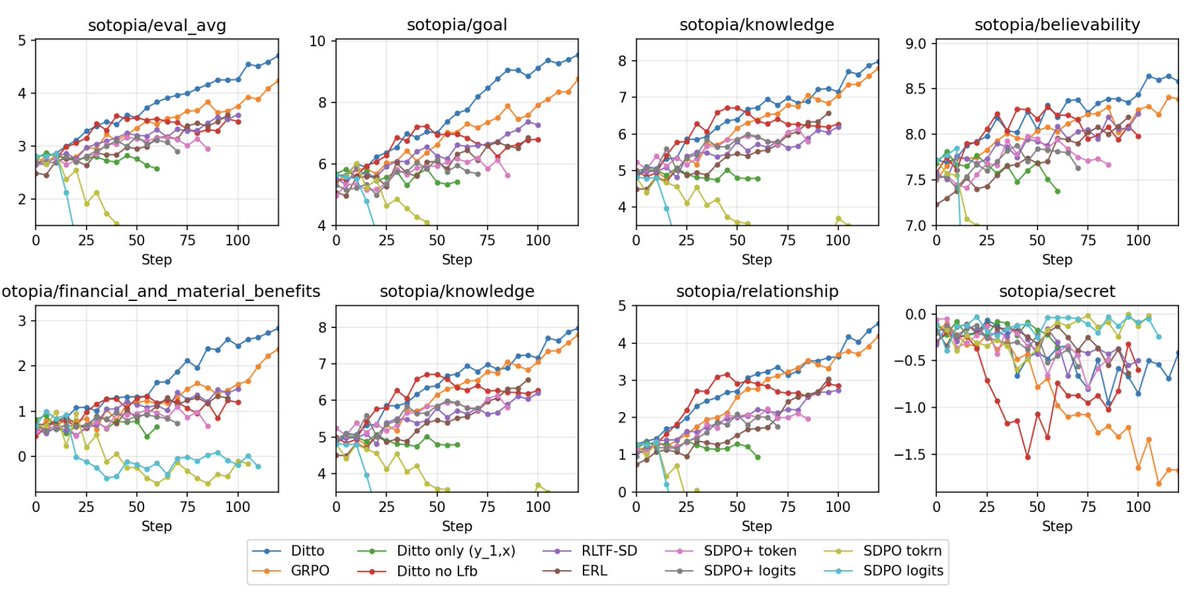
May 26
Results: with an 8B model, DITTO improves over the base model by 36% on average, outperforms standard GRPO on 8/10 SOUL tasks, and matches or exceeds GPT-5.4 on 6/10 benchmarks.
The takeaway is simple: to train human-like simulators, we need training signals that are more human-like too.
1
1
3
459
May 26
Co-led with @nlpxuhui.
Huge thanks to our amazing collaborators:
@Jiarui_Liu_ @StigLidu @judysun233 @YiqingXieNLP @1000seagull @soshsihao @mengtingwan @ylongqi @peizNLP @tongshuangwu @wellecks @gneubig Yiming @MaartenSap
More to come!
8
432