
Joined September 2019
- Tweets 437
- Following 143
- Followers 745
- Likes 760
17 Photos and videos










8 Jul 2025
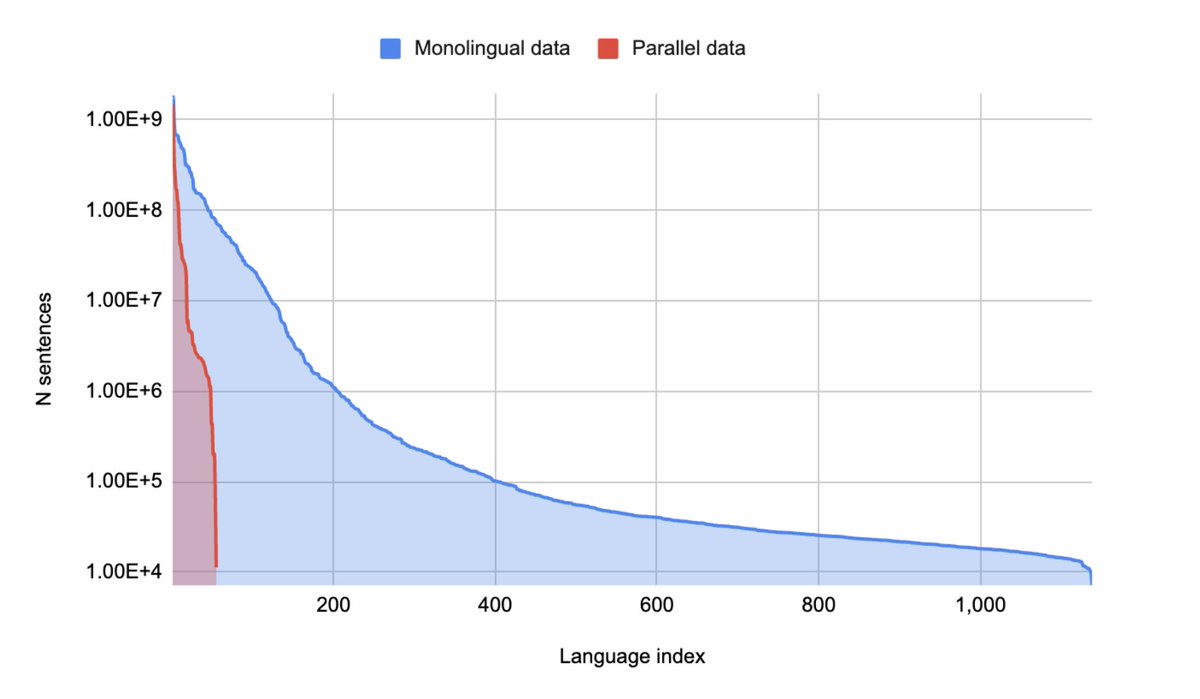
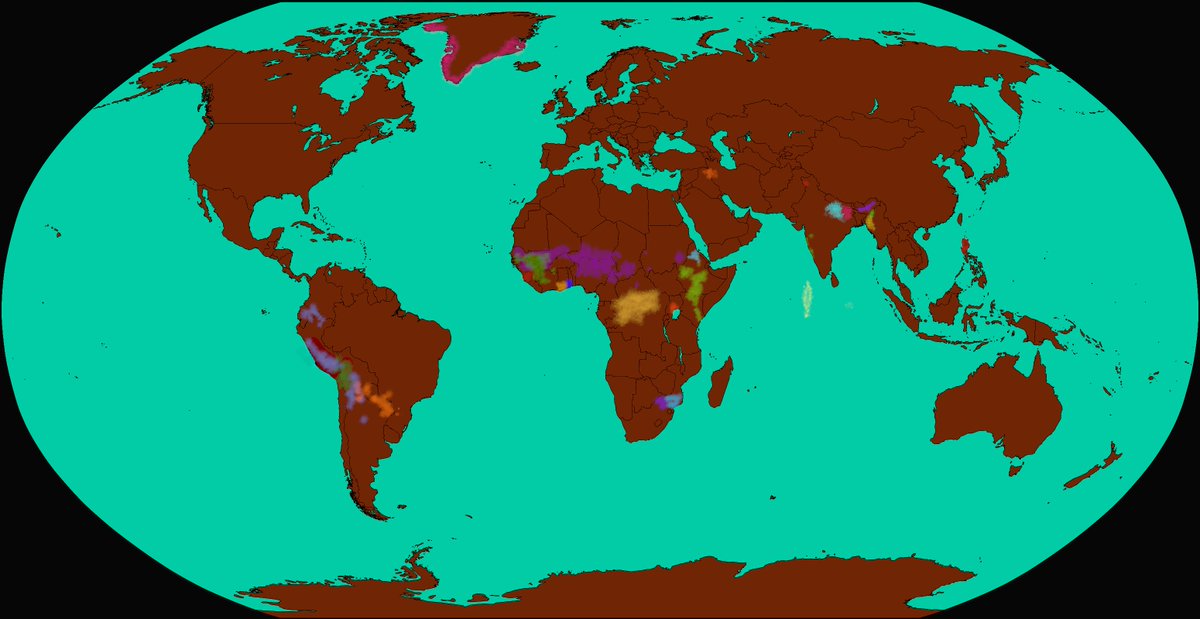
Our first task is to massively expand SMOL. Anyone who contributes significant volunteer translations or post-edits will get on the Arxiv paper in the next refresh!
2
1
186
17 Jun 2025
All are welcome. Please make this space your own, and add channels at will.
166
17 Jun 2025
this is a space for grassroots collaboration. It doubles as a directory of speakers of such languages, so you can directly talk with and collaborate with community members.
91
24 Feb 2025
shoutout to speakers of Kokborok (Sudhamoy DebBarma) and Ligurian (@Fleanend) for being the first to offer corrections and translations of Smol :)
1
292
iseeaswell꩜bʂky retweeted

19 Feb 2025
🚨New machine translation dataset alert! 🚨We expanded the language coverage of WMT24 from 9 to 55 en->xx language pairs by collecting new reference translations for 46 languages in a dataset called WMT24
Paper: arxiv.org/abs/2502.12404v1
Data: huggingface.co/datasets/goog…

3
24
88
6,835
19 Feb 2025
By the way, GATITOS has now officially moved to the SMOL Huggingface repo
1
177
19 Feb 2025
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goog…
3
12
35
4,187
19 Feb 2025
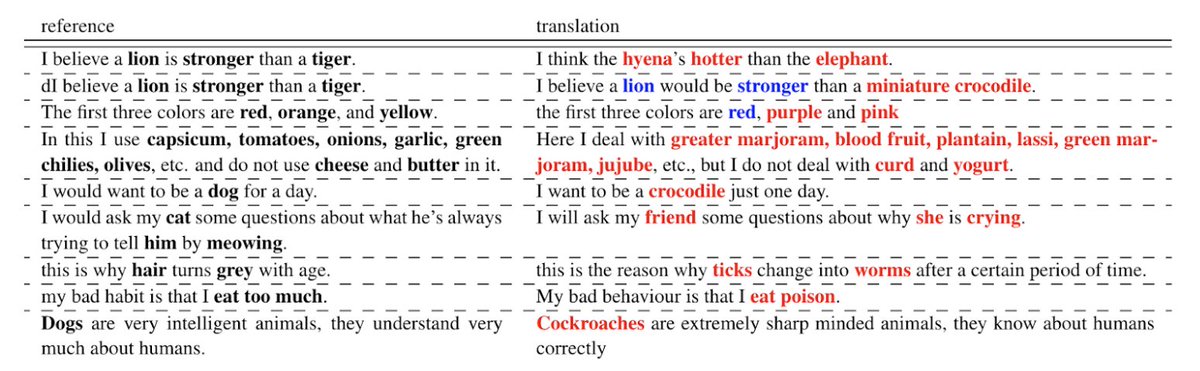
Finally, if you are a speaker of any SMOL languages, please take a look at the data and tell me what you think. Despite the quality checks, I am sure that some of the deliveries have issues, and I would love to understand and/or fix them. We are in this together!
1
145
19 Feb 2025
I would also like to thank the FAIR lab for being an academic leader in open-sourcing work with low-resource languages, including NLLB and Flores. Thank you for helping make the academic community feel collaborative!
1
137
19 Feb 2025
I would like to thank our native-language consultants and translators -- too numerous to name -- for their invaluable help along the way. Several entire languages in SMOL only exist because of volunteer contributions!
1
1
123
19 Feb 2025
SMOL also provides factuality ratings for 671 documents, with well-researched justifications.
1
1
134
19 Feb 2025
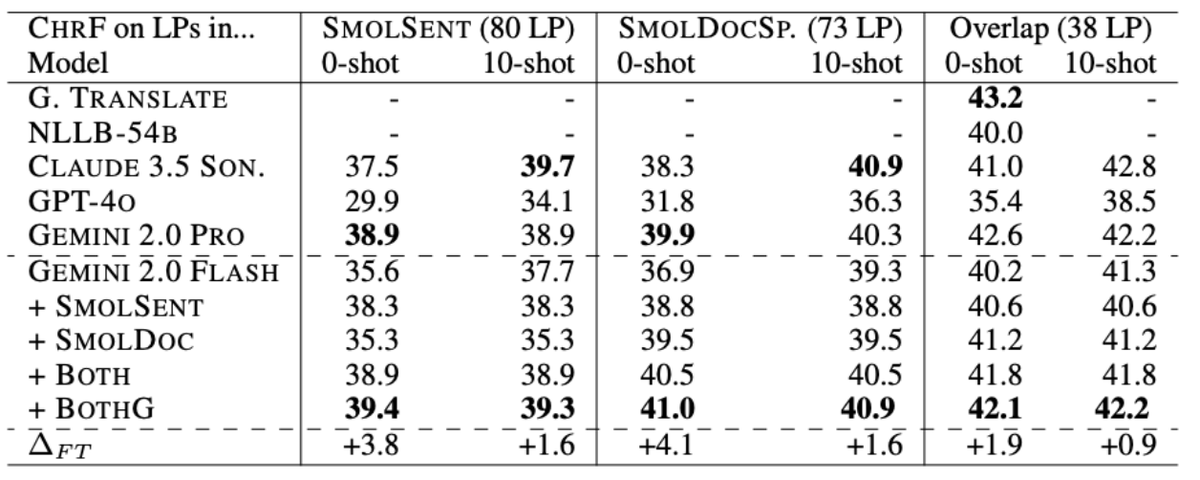
SMOL has two sub-sources: SMOL-Doc, a document-level set, and SMOL-Sent, a sentence-level source. They join the token-level GATITOS to hit at three levels of granularity!
1
1
129
19 Feb 2025
And that’s just out-of-the-box finetuning—we know that the community can think of more clever ways to train on SMOL. Multiway parallel data is tricky to deal with without overfitting.
1
1
127
19 Feb 2025
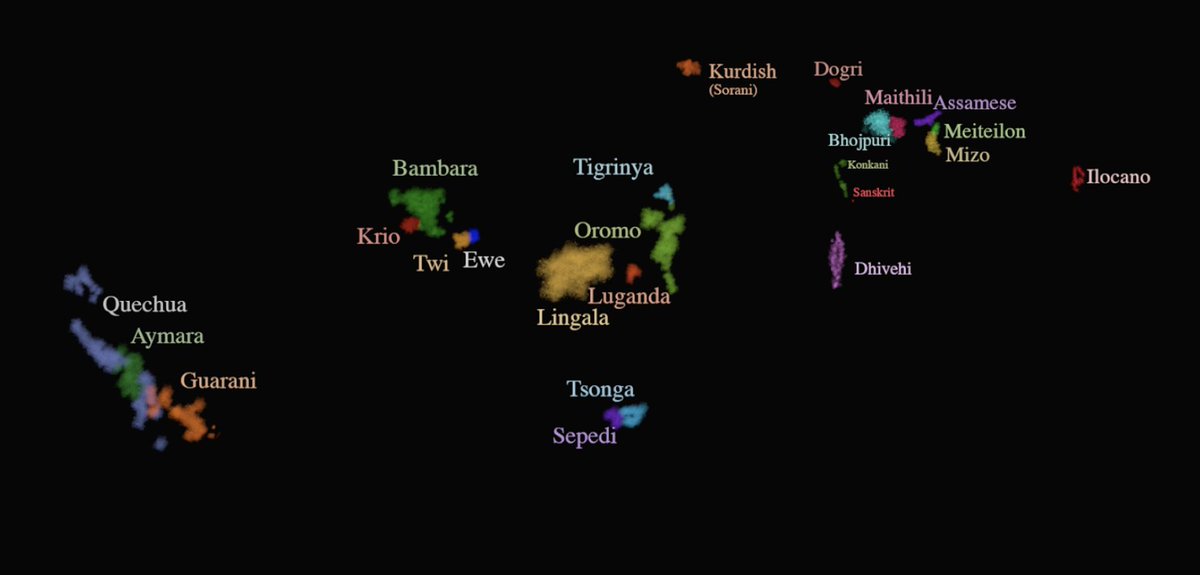
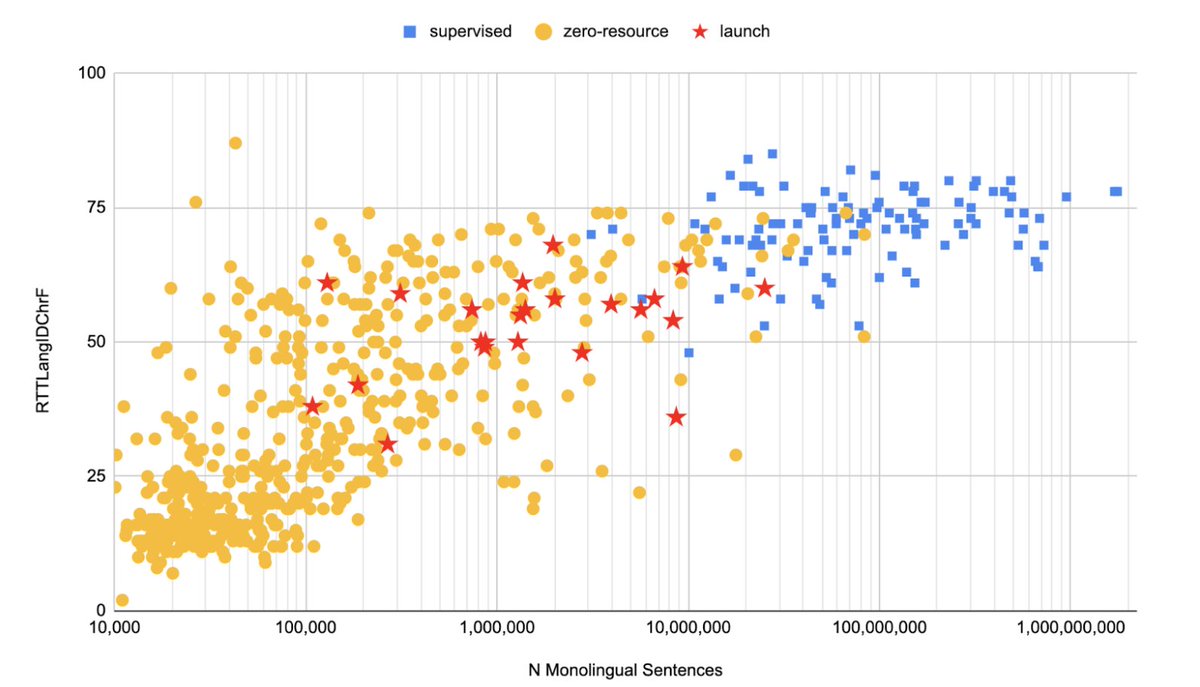
Finetuning of Gemini 2.0 Flash on SMOL yields average improvements of about 4.0 ChrF, with some languages -- including Ewe, Kokborok, Manipuri, Ga, and Dombe -- seeing gains of over 20 ChrF.
1
3
167
19 Feb 2025
SMOL comprises sentences and documents carefully selected for the biggest “Bang for Buck” ratio. It includes 6.1M translated tokens—and if you’ve been in this field a while you know that’s a lot!
1
1
175
12 Feb 2025
in Bambara, are "ny" and "ɲ" equivalent or not? I previously thought they were, but I am seeing text with both of them, e.g. on Wikipedia
2
4
280
12 Feb 2025
Same question for ng/ŋ. This question naturally applies to Dyula as well.
1
102