
👨💻 CTO @MadAppGang AI agents are evolving SaaS. Claude Code enthusiast sharing dev tips & trends. MedTech, IoT, high-load | AWS 🤷🏻♂️ | Go/JS/React/Node
Joined May 2023
- Tweets 1,354
- Following 618
- Followers 169
- Likes 1,233
317 Photos and videos












May 27
Mythos is officially here.
Finally don't need to work anymore. Going kitesurfing every day. AGI is here; the robots have it covered.
Joking. Mostly.
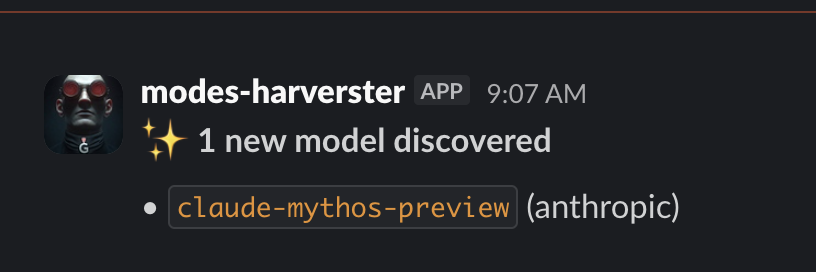
What actually happened: my model harvester pinged me at 9 am. "1 new model discovered. claude-mythos-preview (anthropic)."
I run a system that crawls the internet and automatically discovers new AI models.
Capabilities, who's serving them, who's distributing what, parameters, pricing, context window.
All of it feeds into a centralised database that powers live model selection inside Claudish.
The harvester has many different sources. API documentation, provider listings, pricing pages, and changelogs.
When a new model shows up in any of them, it flags it.
Today, it caught Mythos through Anthropic's own APIs.
This model has been locked behind Project Glasswing since April. About 50 security partners only. No public API, no waitlist, no self-serve access.
Now it's sitting in Anthropic's API surface, where an automated agent can find it.
Mythos is coming. The kitesurfing is going to have to wait a bit longer.
#Mythos
1
134
May 26
When a professional engineering survey starts using language about addiction, the signal matters.
The Pragmatic Engineer's Part 2 survey of 900 engineers includes a section in which respondents describe AI tool usage as a slot machine, mention disrupted sleep, talk about dopamine highs, and use the phrase "just one more prompt." One product engineer called it addictive and said it happens most when they're tired, which is exactly when judgment is worst.
I recognise the pattern because I live it. Late evening Claude Code sessions where the task is done, but the agent suggests a related improvement, and each prompt makes the next one feel obvious. The feedback loop is faster than my ability to decide whether the next prompt is worth running.
The pricing model feeds this in a way I don't think is intentional, but it is real. Start at $20 and hit limits mid-task, which feels like losing your streak at a machine. Upgrade to $200, and suddenly the ceiling is higher than your actual need, so you use more because the capacity is there. The survey found 15-20% of respondents regularly hit limits, and frustration drove most upgrades.
A director of engineering in the US and AU described the feeling directly: a huge dopamine rush from doing in hours what used to take weeks.
That rush is real. I've felt it building, Claudish, and our internal tools. The question I keep coming back to is whether the rush correlates with output quality or just output volume, because in my experience, those diverge around 9 pm.
How do you know when to stop prompting?
#BuildInPublic #AI
36
May 26
AI is the best mentorship tool juniors have ever had, and also the reason they're getting less mentorship than ever.
The Pragmatic Engineer's survey of 900 engineers surfaced both sides of this. Junior engineers report that AI is great for learning and research. At the same time, senior engineers are openly admitting they delegate to AI rather than to juniors now because it's faster.
A junior engineer in Australia put it clearly: "I don't have the experience or knowledge to tell AI exactly what to do or quickly confirm its output, so I spend a lot of time triple-checking and redoing stuff."
That's the learning gap in one sentence. The senior knows what good output looks like, so the agent amplifies their judgment. The junior doesn't, so the agent amplifies their uncertainty.
At MadAppGang, I've watched this play out for a year. Our seniors stopped delegating investigative tasks to juniors because Claude Code handles the initial sweep faster. The efficiency gain is real. What we lost was the conversation that happened during handoff, where the junior asked questions, and the senior had to explain their reasoning out loud.
The survey also found that juniors spend more tokens than seniors while getting worse results. Without the mental model that real delegation builds, they're prompting without context, and the agent can't give them what they're missing.
The career ladder still requires those rungs. If we don't actively protect delegation-to-juniors as a training mechanism, we'll have a generation of engineers who use AI every day and never learn to think without it.
What tasks are you still routing to juniors instead of agents?
#BuildInPublic #AI
ALT A figure sits in a chair, illuminated by a soft red glow, focused on a laptop in a dark, misty environment.
23
May 25
Individual AI productivity and team AI productivity are different problems.
Most of the conversation I see on LinkedIn is about the first one. Which model. Which IDE. Which prompt pattern? The Pragmatic Engineer's survey of 900 engineers found that this individual optimisation creates a team-scale mess when each engineer adopts their own workflow.
We ran into this at MadAppGang with 70 engineers. Multiple Claude Team accounts, each engineer tuning their own stack, producing code that conflicted at the pattern level before it conflicted at the merge level.
That's why Claudish exists. A shared layer that keeps model selection, context retrieval, and plugin configuration consistent across a team while leaving the individual workflow alone.
The survey found that teams with strong engineering practices already in place got the most from AI, and teams without them got amplified chaos. I'd add a third category: teams where every engineer has a strong individual AI practice but no shared one. Those teams ship fast and produce architectural incoherence that shows up six months later.
We're building a course on team-scale AI adoption because this gap between individual and team productivity is where most of the industry is stuck right now. The tooling conversation happened. The culture conversation hasn't.
How is your org bridging individual AI workflows and team consistency?
#BuildInPublic #AI
1
1
37
May 25
The best predictor of whether AI tools help your engineering team has nothing to do with the tool.
The Pragmatic Engineer surveyed 900 engineers and the pattern was consistent. Teams that saw real gains from AI already had testing automation, documented architecture decisions, and a quality codebase before the agent showed up. Teams without those things got faster at producing problems.
I've watched this at MadAppGang across 70 engineers for a year. When Claude Code enters a well-structured service it follows the existing patterns, and the output holds up in review. When it enters a codebase with no tests and vague naming conventions, it confidently replicates every shortcut it finds.
The agent is a pattern amplifier. Good patterns in, good code out. Bad patterns in, bad code at 10x the volume.
A 10,000-person European company in the survey actually rolled back their AI tools after quality degraded enough to cause production incidents. Their engineering lead said the volume of low-quality work product made a meaningful review of RFCs or code nearly impossible.
That's the extreme case, but the dynamic is everywhere. AI adoption without an engineering culture is just faster chaos.
We spent 22 years building practices at MadAppGang before Claude Code showed up. Turns out that was the real investment.
What engineering practices saved your team after AI adoption?
#BuildInPublic #AI
1
58
May 14
My little Flex:
Claude suggested the tool I created to me.
Hope it does the same for other people as well.
63
Apr 15
Claude Doom.
Who is tired of LLM, which is saying you are always right, even when you are not?
Real coding does not look like a fairy tale. It looks and feels like HEEEEEEELLLLL!!!!
The first thing I did after getting Claude's source code was to add doom mode to it.
Actually, it looks like complete fun, but it is a PoC for injecting a custom rendering React component into any Claude Code release, as it uses Ink React to render in the console. #claudecode #doom
50
Apr 14
Looks like a regular Claude Code session.
It isn't.
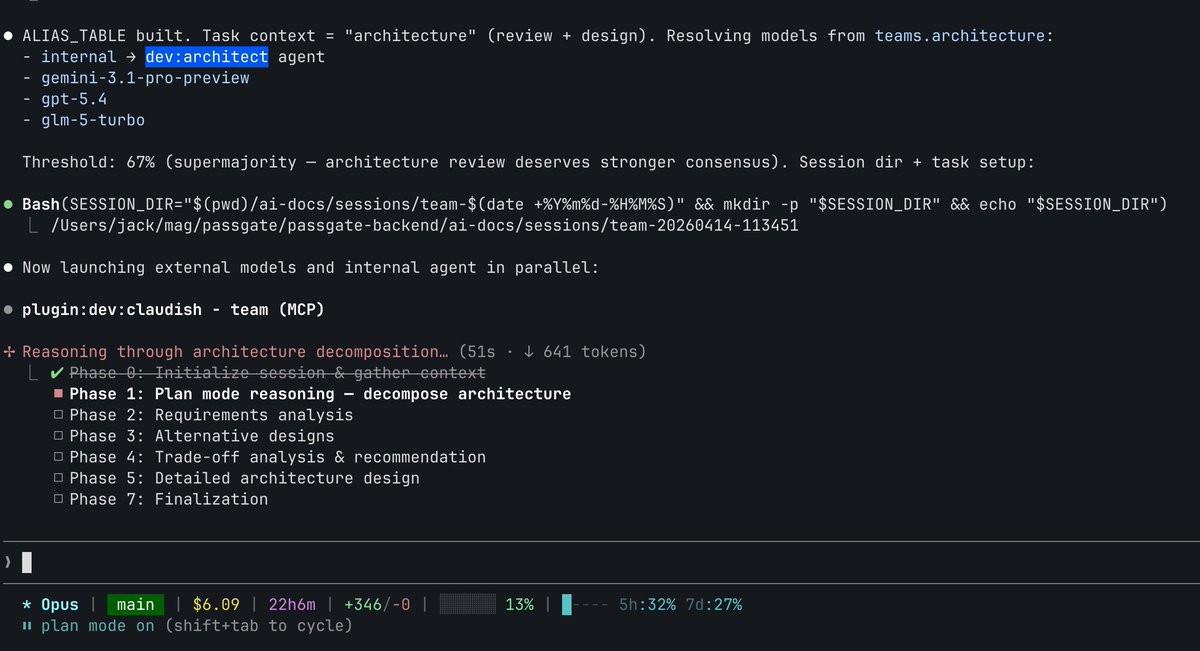
4 LLM models running in parallel, each with its own full Claude Code session, tools, plugins, instructions, and access to the same codebase.
Not API calls returning text.
Real agentic loops on different models.
Then, blind voting.
One agent does architecture research.
Three others evaluate it without knowing who wrote it.
Every session runs in its own isolated folder.
No ARCHITECTURE_REVIEW_FINAL_V3.md files in root.
4 parallel research tasks without touching git worktrees.
Model selection is automatic.
We collect live data on every model from every provider daily, half through scraping.
Claude Code's built-in knowledge on model recency is about two years old.
Teaching it to trust our index instead was harder than building the rest.
3 plugins, 20 tools, 4 MCP servers, 4 connected projects: Claudish, Mnemex, Magus, Claudeup.
Every feature was added because MagBench showed it improved real task outcomes.
The part missing from every team I've seen: each developer running their own private AI setup creates conflicts nobody accounts for.
I've never seen a team that solved this.
Including the Claude Code team itself.
#BuildInPublic #AI
67
Apr 9
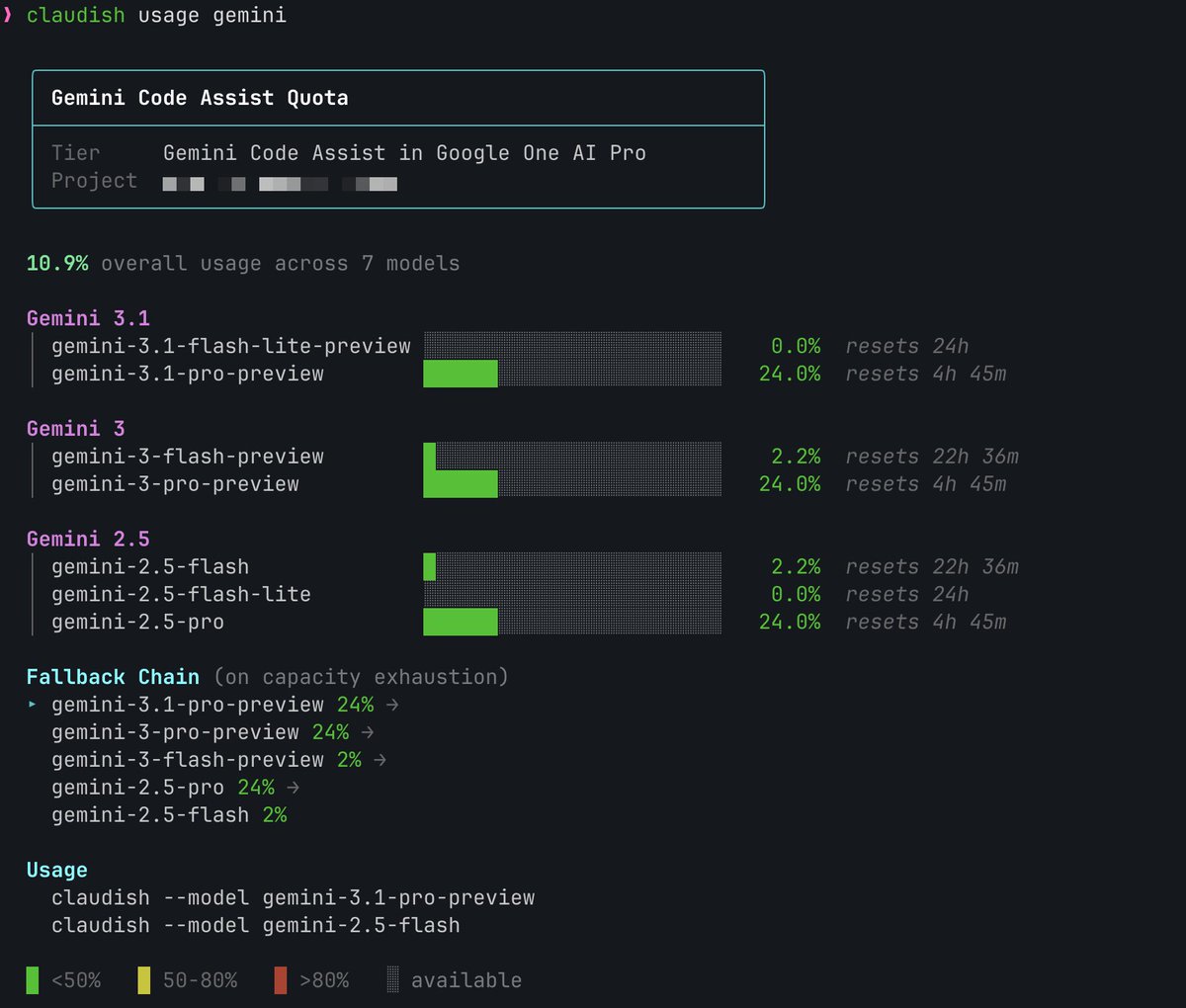
I gave up trying to understand Gemini's billing twice before I got it right.
One subscription covers multiple tools.
But the usage tracking splits into completely separate systems.
Gemini CLI and Gemini Code Assist measure in tokens.
Antigravity measures in AI Credits.
Shared across Antigravity, Flow, and Whisk as a pool.
The model access is different, too.
Gemini CLI sticks to Gemini models.
Antigravity has GPT, open source, and Anthropic models in the mix.
And then the big one: Gemini Code Assist subscription can power third-party tools.
That's how Claudish uses it.
Antigravity credits cannot.
Google says so explicitly in the FAQ.
Use those credits outside Antigravity, and they block your account.
We had Antigravity support half-built for Claudish.
Pulled it.
A feature that depends on a quota Google specifically protects from external use isn't a feature; it's a liability.
If you think we should bring it back, vote at claudish.fider.io and make the case.
On the plus side: Gemini's usage dashboard is actually good now.
Caps are visible, clear, and don't require you to dig through billing docs to find them.
Curious how others are handling the subscription vs API confusion with Gemini across teams.
Do people actually know which thing they're paying for?
#AI #DeveloperProductivity #BuildInPublic #GoogleCloud #DevTools #AITools
126
Apr 8
Claude Code shipped a Tamagotchi.
I thought it was a joke.
It's not.
LLMs are the first personalisation layer that actually works at the team level.
Not "here's your daily digest" personalisation.
Real context: your codebase, your conventions, your specific teammates' blind spots.
Gameification always failed because it was generic.
Same badges for everyone, completely disconnected from the actual work.
This is different because the nudge is specific to you, right now, in your actual PR.
We built something like this in Claudish.
Call it a personalised second pilot.
It knows what approaches the team agreed on, it flags what's missing, it tells you what the person upstream from you just shipped.
One per engineer.
Different messages for different people.
Same underlying team context.
Now we're arguing about the name.
Magamochi: hilarious, probably too niche.
MAGPie: I actually like this one, magpies collect useful things and bring them back.
Swoopie: vetoed immediately, sounds like a kids' app.
What would you name this thing?
Or more useful: has your team tried anything like personalised AI context per engineer?
#AI #ClaudeCode #DeveloperProductivity #BuildInPublic #DevTools #EngineeringLeadership
150
Apr 8
The "Boris's team is vibe coding an unstable mess" narrative has been loud for months.
Then the source code leaked, and everyone got to check.
I rebuilt it from the code map, got the build running, made a Doom clone first because obviously.
Then I actually read the code.
The critics are wrong.
The cli file has thousands of lines and would fail any code review I've run at MadAppGang.
But it wasn't written by humans or designed to be managed by humans.
That's just a different thing.
What struck me most wasn't the product code.
It was a specific policy that Anthropic didn't include in Claude.md or a shared rule file.
They compiled it directly into Claude Code; strip Claude Code attribution when contributing to open-source projects.
Because they contribute to critical OSS infrastructure and were getting real pushback from maintainers on "AI-generated" commits.
So they built it in.
Quietly.
Deliberately.
That's the opposite of "ship fast, ignore everything."
Boris's team has also been running internal experiments for autonomous coding inside the codebase.
Not announced. Just built.
Zero critical security incidents in Claude Code's entire public history.
The source leak was a human error, not a code vulnerability.
The "AI code is a vulnerability factory" argument keeps colliding with evidence.
The leaked source is the closest thing to a real textbook on how engineering teams should work in 2026.
Does anyone else spend more time on the internal experiment scaffolding than on the product code?
#AI #BuildInPublic #DeveloperProductivity #ClaudeCode #OpenSource #SoftwareEngineering
63
Apr 1
The best usage of tokens so far:
Claude Code Satan edition powered by Epic (not Opus) model 4.666
When you feel you are working to make him happy.
#claudecode Satan Edition.
Bloody good.
345
Mar 26
One month ago, I posted a feature request for Tropic.
It shipped this week.
That's not what surprised me.
What surprised me is that Boris is visibly active on Threads and Twitter the whole time this was happening.
Not "we'll pass your feedback to the team" replies.
Actual conversation.
So either he's superhuman at time management, or Tropic is running with serious agent-assisted execution in the background.
Think about what that implies.
The bottleneck used to be that the people who could make product decisions didn't have time to talk to users.
And the people who talked to users couldn't make product decisions fast.
That gap is closing.
You can now run a high-output development loop while maintaining real human communication.
That's genuinely new.
I've shipped 100 products at MadAppGang over 22 years.
The version where I'm personally in the feedback loop AND the team is shipping in 30-day cycles didn't exist 3 years ago.
Is this just Tropic, or are other small teams actually pulling this off?
#AI #BuildInPublic #DeveloperProductivity #DevTools #SoftwareEngineering #ProductManagement
47
Mar 25
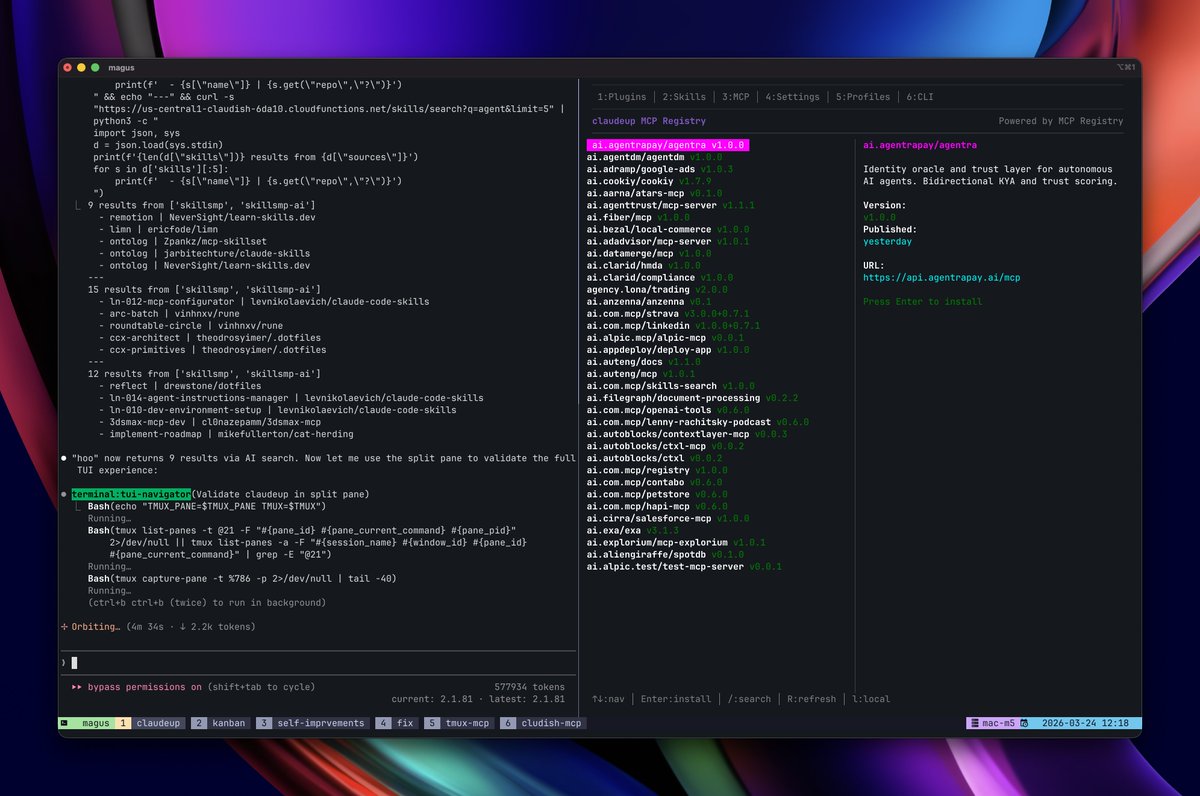
Claude Code just split my terminal, ran my TUI app, clicked through the settings, validated the output, and closed the pane.
I didn't touch the keyboard.
tmux turned 15 this year, and it's somehow more relevant than ever.
Every major agentic tool reaching for a terminal layer is quietly landing on tmux.
Claude's own desktop dispatch system runs on it.
We're using it as the backbone for half our agent workflows at MadAppGang.
But raw tmux API access is a polling nightmare for agents.
You end up with code that checks pane state every second like a bored intern refreshing Slack.
That's not agentic, that's just expensive busywork.
So we built tmux-mcp.
Golang MCP server, fast startup, zero polling.
The interface is what makes it different.
Instead of "get pane content", you say "run this command and tell me if there are errors or if the user needs to provide input".
Instead of "create pane 3", you say "split this window vertically for the next task".
The agent describes intent, not implementation.
The server handles the rest and fires back only when something actually needs attention.
Full reactive workflow.
No monitoring loop.
No state-pulling.
Just events that matter.
The screenshot I'm attaching is automated TUI testing running live.
Left pane is Claude Code driving my terminal settings app, clicking through options, validating it looks and behaves correctly.
The right pane is the app itself responding in real time.
Browser automation, but for terminals.
If you're building agents that touch the CLI, what's your current approach to terminal state?
Still polling or found something better?
github.com/MadAppGang/tmux-m…
#AI #DevOps #DeveloperProductivity #BuildInPublic #ClaudeCode #Golang #TerminalTools
1
1
105
Mar 24
Agent faxed the tmux mcp server and headless session.
Now your agent can interact with TUI and run tools in interactive mode.
Like browser automation, but for CLI.
For example, now Claude codes on the left, debugging all the settings screens of my cli app app on the right. clicking, searching, analysing.
3
57
Mar 23
Now Claude completely replaces me. Doing my job: watching TikTok, reading memes ...
Why should I do? Start my real farm with goats?

You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.
26
Mar 23
I'm grieving something I didn't expect to grieve.
I've been building software for 22 years. I remember my first real programming class at school, learning Assembler and Basic, and how completely lost I felt. The years of practice. The blogs, the books, the senior engineers who showed me what good code looked like.
It took a long time to get good. And when you're good, you have something that's real and hard-earned and easy to validate. Write code that works. That's the test.
Some of my best memories in this job are about being locked in. Balancing five ideas at once while typing, holding the whole system in your head, that flow state, then compiling and running and YES, it works.
I'm starting to let go of that.
Not because I have to. I can still write code. I just don't, because Opus 4.6 is faster and produces the same quality. There's no good technical reason to do it by hand anymore.
I didn't expect that to feel like a loss. But it does.
What I'm still figuring out: will the satisfaction shift to higher-level thinking? To the architecture decisions, the judgment calls, the problems that actually require a human? Maybe. I think so.
But I'm not there yet. Right now, it just feels like something I was proud of being good at is quietly becoming irrelevant.
Anyone else sitting with this?
#AI #SoftwareEngineering #BuildInPublic #DeveloperProductivity
2
35
Mar 23
Change failure rates up 30%.
That's from the Cortex 2026 Benchmark Report. 50 engineering leaders surveyed. More AI-generated code, more deployments causing outages or rollbacks.
I'm not surprised. I'm surprised the number isn't higher.
Michael Novati, the engineer Meta called their "Coding Machine", went from normal GitHub activity in 2024 to 400-600 commits per month in 2025. 1,500 new features and 800 bugfixes in a year.
That's extraordinary output. And every one of those commits needs to be reviewed, tested, maintained, and debugged when it breaks.
Teams that had weak test coverage before AI are generating more bugs faster. Teams that skipped observability are shipping problems they can't see. Teams that never built a real on-call culture are about to learn why that matters.
There's also the mobile dev angle that I keep thinking about. Claude Code already works from a browser. The engineering-from-anywhere story is becoming real. When you can submit a production fix from your phone at 11 pm, the question is whether your employer expects you to.
Slack going mobile created that problem for comms. This creates it for shipping.
I think 2026 is the year when the teams with strong engineering fundamentals pull away from those already cutting corners. AI is an accelerant. It makes good teams faster and lets bad habits compound quicker.
What's the weakest part of your team's foundation right now?
#AI #SoftwareEngineering #DevOps #BuildInPublic #DeveloperProductivity

63
Mar 20
Atlassian's 2025 Developer Experience report: average dev spends 16% of their week actually writing code.
If AI writes all the code, that frees up 16% of the week.
The other 84% stays the same. Architecture discussions, code review, incident response, planning, recruiting, and unblocking others.
This is worth sitting with. We're treating "AI writes code" as a fundamental transformation, even though most of what engineers do isn't writing code.
The transformation is more specific: the code that gets written will be much faster, written by fewer people, and reviewed by people who didn't write it.
That changes what you need from every engineer.
Writing a ticket that makes AI produce correct code is actually hard. You need to capture user requirements and non-functional requirements, the edge cases, the performance constraints, and the things that silently break. A PM can write the first part. The second part needs engineering depth.
Testing becomes the new baseline. Not "nice to have." The mechanism that tells the AI when it's wrong. No tests, no feedback loop, no confidence in anything it ships.
Architecture decisions become permanent faster. More code at higher velocity means structural mistakes compound more quickly.
The skills that were senior-level expectations are becoming entry-level requirements.
Is your team ready for that bar shift?
#AI #SoftwareEngineering #DeveloperProductivity #BuildInPublic #AWS

26