
Joined May 2019
- Tweets 13
- Following 190
- Followers 105
- Likes 14
Photos and videos
Jay DeYoung retweeted

25 May 2023
Sharing our #ACL2023NLP paper on evaluation for medical multi-document summarization! New human annotated dataset, new metrics, and an in-depth analysis, here: arxiv.org/abs/2305.13693
Joint w/ @YuliaOtmakhova @jaydepun @ththinh_ BaileyKuehl ErinBransom @allen_ai @byron_c_wallace
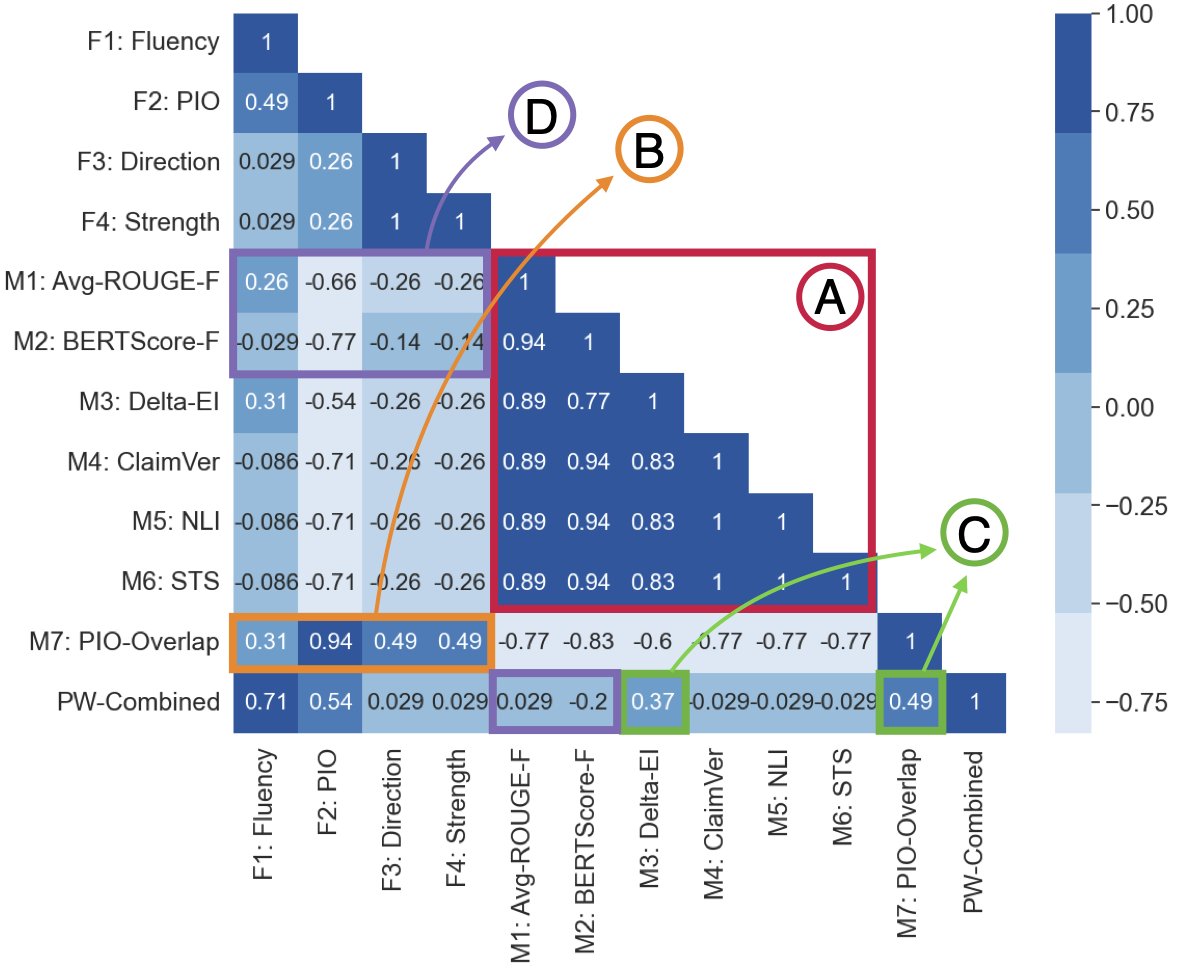
ALT Spearman correlations between rankings produced by human-assessed quality facets (F1-F4), automated metrics (M1-M7), and combined pairwise system rankings (PW-combined) on the Cochrane MSLR dataset. Rankings from automated metrics are highly correlated as a group except for PIO-Overlap (A). PIO-Overlap rankings are strongly correlated with rankings from human-assessed facets, especially PIO agreement (B). Metrics most strongly associated with PW-Combined rankings are Delta-EI and PIO-Overlap (C). Rankings from commonly reported automated metrics like ROUGE and BERTScore are not correlated or anti-correlated with human-assessed system rankings (D).
11
67
5,251

15 Apr 2021
Medical systematic reviews are costly and time-consuming to produce. We introduce a new dataset called MS^2 to help automate and assist in parts of the process: arxiv.org/abs/2104.06486 #NLProc @lucyluwang @i_beltagy @SemanticScholar @allen_ai 1/3
3
7
30
15 Apr 2021
MS^2 focuses on extraction and summarization in the review pipeline. We harvest 20K systematic reviews and 470K of their references from Semantic Scholar, identify summary targets, and experiment with multi-document summarization methods. 2/3
1
3
15 Apr 2021
AI safety will be an important part of any system performing these tasks in the wild. There’s a lot of work to do to ensure the quality and reliability of model outputs. We encourage the community to work on these challenging and important problems! 3/3
2
Jay DeYoung retweeted

13 Nov 2019
1/ New work by Alican (@alicanb_) and Babak (@BabakEsmaeili10): "Evaluating Combinatorial Generalization in Variational Autoencoders" (arxiv.org/abs/1911.04594)
In this paper we ask the question: "To what extent do VAEs generalize to unseen combinations of features?"(thread)
1
39
108

Happy to share our work on Amortized Population Gibbs Samplers! arXiv: arxiv.org/abs/1911.01382
5 Nov 2019

1/ New on arXiv: "Amortized Population Gibbs Samplers with Neural Sufficient Statistics" arxiv.org/abs/1911.01382.
Work by: Hao Wu (@Hao_Wu_), Heiko Zimmermann (@zmheiko), Eli Sennesh (@EliSennesh), and Tuan Anh Le (@tuananhle7).
(thread below)
2
4
Jay DeYoung retweeted

8 Nov 2019
#NLProc does not have a standard benchmark for interpretability. I am stoked to announce ERASER: the first-ever effort on unifying and standardizing NLP tasks with the goal of interpretability.
eraserbenchmark.com/
5
52
143
8 Nov 2019
We decided to try to measure it: blog.einstein.ai/eraser-a-be…
@byron_c_wallace @successar_nlp @nazneenrajani @RichardSocher
#NLProc #MachineLearning
8
6