
Opinions are my own. Ph.D. student at @RiceCompSci in @vislang. Previously @RealityLabs @AdobeResearch, @InariAILab, @AdaVivInc.
Joined December 2017
- Tweets 542
- Following 380
- Followers 74
- Likes 17,300
2 Photos and videos


Jefferson Enrique Hernandez Cevallos retweeted

Jun 10
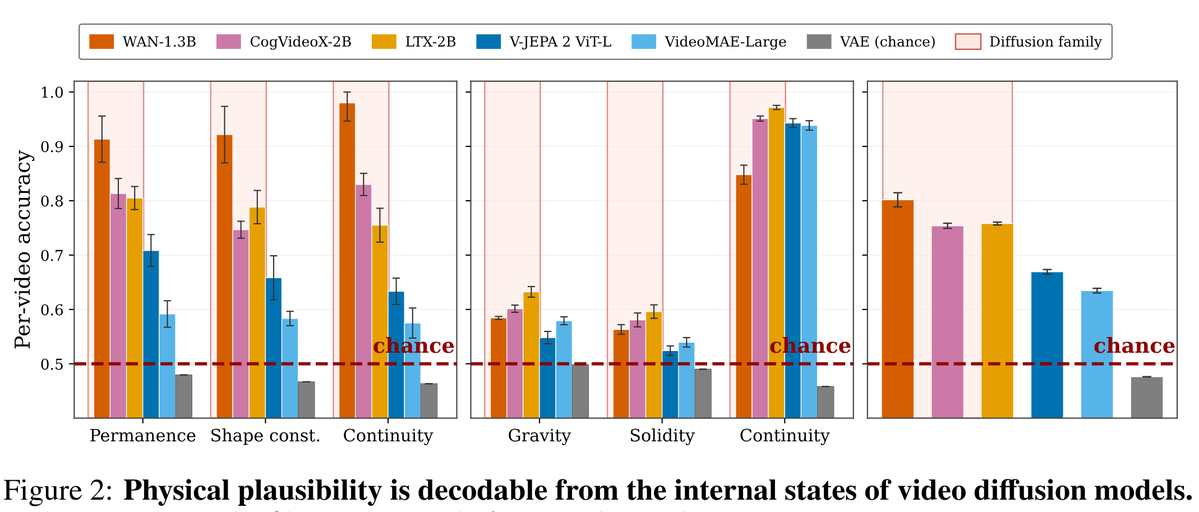
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
42
107
1,066
99,765

Jefferson Enrique Hernandez Cevallos retweeted

Jun 7
This may be a controversial take, but I think it needs to be said: the gap between computer vision research in academia and industry is widening with every conference.
A huge fraction of @CVPR papers—especially those that boil down to "we tweaked/fine-tuned/RL'ed large-scale model X to improve on task Y"—will become obsolete with the next model release. That's not where academia creates lasting value. PIs should adapt much faster to this changing reality.
Academia should focus on fundamentally new ideas, new problem formulations, explaining emergent phenomenology, or uncovering blind spots that industry can later solve with scale, compute, and data.
37
115
1,125
94,357
Jefferson Enrique Hernandez Cevallos retweeted

Jun 5
Scaling laws describe how loss changes with scale. Do neurons inside models change predictably too?
We study vision and language models up to 30B params and find systematic scaling in neuron universality, specialization, and selectivity.
Paper code: avdravid.github.io/rosetta-n…
1/n
13
83
415
202,304
Jefferson Enrique Hernandez Cevallos retweeted

Jun 5
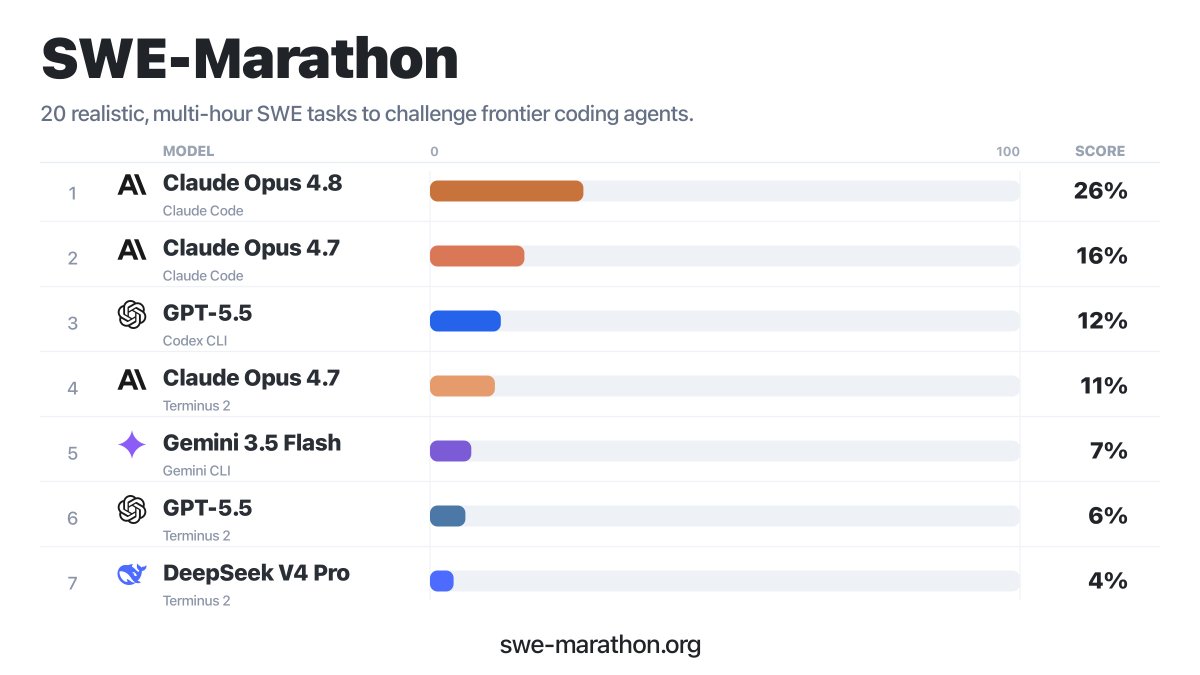
Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
49
65
680
794,763
Jefferson Enrique Hernandez Cevallos retweeted

super excited to share our latest work! are we really tilting? 🤨
tldr: reward guidance for flows and diffusions is supposed to sample from the reward-tilted distribution. we show it doesn’t 😰 and how to (mostly) fix it ✨
plus lots of fun images!! 🖼️
collaboration with the awesome @nmboffi
website: sanjitdp.github.io/are-we-re…
paper: arxiv.org/abs/2606.02884
code: github.com/sanjitdp/reward-g…
3
17
101
15,642
Jefferson Enrique Hernandez Cevallos retweeted

Jun 4
こんな面白い研究あったのね
データセットの重複しないサブセット2つ用意してそれぞれで別の拡散モデル訓練する時、データ数増やしてゆくと同じノイズが似たような画像を作るようになる、と
openreview.net/forum?id=ANvm…

2
20
184
15,855
Jefferson Enrique Hernandez Cevallos retweeted

May 26
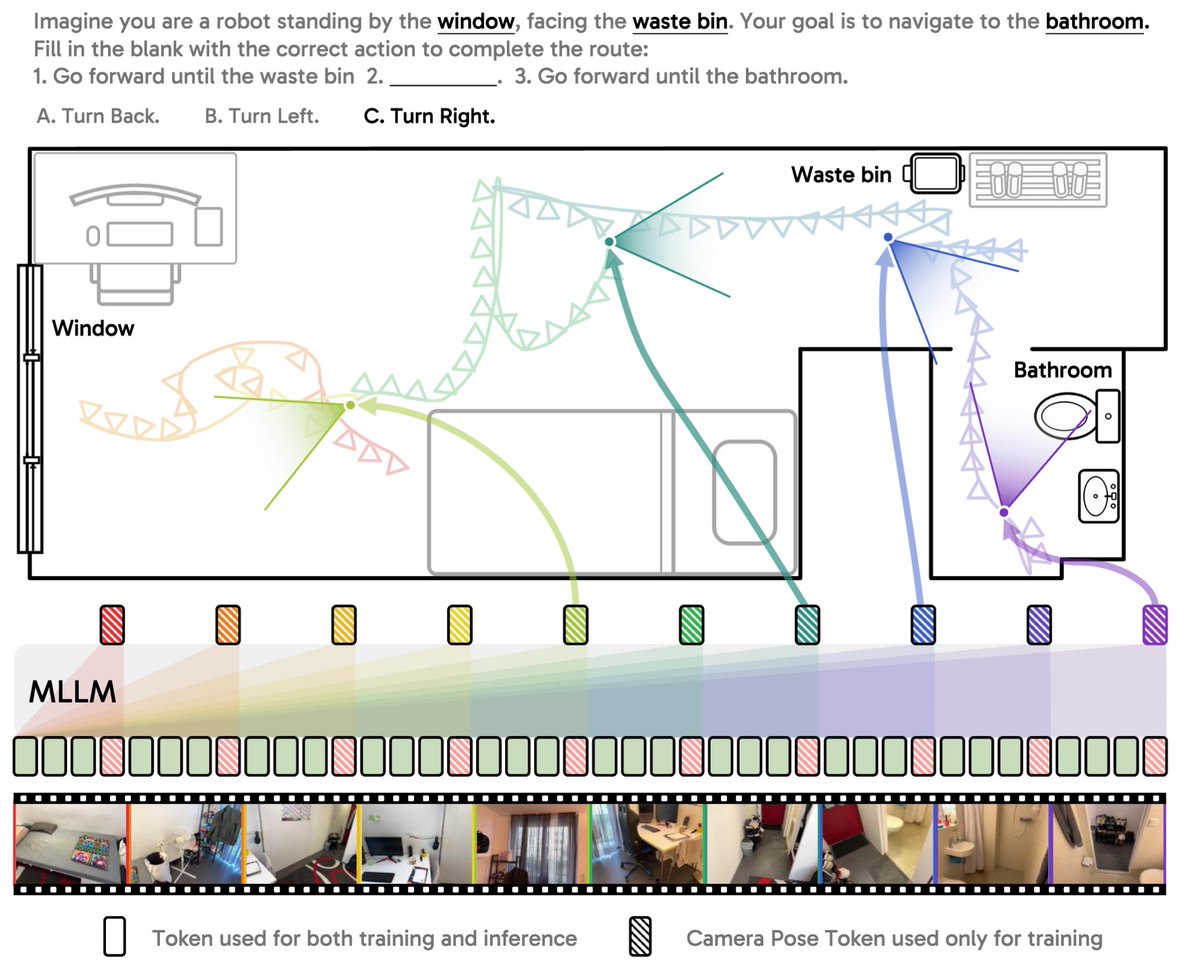
Camera pose matters for video understanding!
Today's MLLMs excel at recognizing activities, but still struggle with the underlying space and ego/object dynamics in video. We trace this gap to a missing piece: camera pose.
Introducing Cambrian-P: a multimodal LLM natively grounded in camera pose. (1/n)
2
47
277
53,710
Jefferson Enrique Hernandez Cevallos retweeted

May 25
One of the hottest terms in AI right now is "On-policy distillation".
It is a post-training technique in which a student model, typically an LLM, samples from its current policy and receives a teacher signal for on-policy states. It combines the dense supervision of distillation with the locality of online RL.
Now a method on PapersWithCode!
Find all 183 papers that cite it, and more here: paperswithcode.co/methods/on…

21
127
1,125
84,431
Jefferson Enrique Hernandez Cevallos retweeted

May 24
I trained an autoencoder that reconstructs images with zero reconstruction loss.
No MSE. No image space supervision.
The only signal: "According to you, does your output look like your input through your own eyes?"
It works.
Blog link, demo and summary 👇
24
47
614
68,218
Jefferson Enrique Hernandez Cevallos retweeted

May 14
𝗧𝗵𝗲 𝗿𝗲𝗰𝗼𝗿𝗱𝗶𝗻𝗴 𝗼𝗳 𝗟𝘂𝗰𝗮𝘀 𝗕𝗲𝘆𝗲𝗿'𝘀 (@giffmana) 𝗹𝗲𝗰𝘁𝘂𝗿𝗲 𝗮𝘁 @ETH 𝗶𝘀 𝗻𝗼𝘄 𝗹𝗶𝘃𝗲 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝘄𝗵𝗼 𝗰𝗼𝘂𝗹𝗱𝗻'𝘁 𝗷𝗼𝗶𝗻 𝘂𝘀 𝗶𝗻 𝗽𝗲𝗿𝘀𝗼𝗻!
This past Monday, we had the pleasure of hosting Lucas (@Meta @AIatMeta Superintelligence Labs) for our "Robot Learning: From Fundamentals to Foundation Models" course. He joined us to talk about: "𝗩𝗶𝘀𝗶𝗼𝗻 𝗶𝗻 𝘁𝗵𝗲 𝗔𝗴𝗲 𝗼𝗳 𝗟𝗟𝗠𝘀".
Drawing from a remarkable track record in computer vision and multimodal AI (𝗩𝗶𝗧, 𝗦𝗶𝗴𝗟𝗜𝗣, 𝗣𝗮𝗹𝗶𝗚𝗲𝗺𝗺𝗮) 🧠, Lucas delivered a masterclass on the frontier of multimodal foundation model training: from pre-training to post-training, where the field stands today, and what comes next 🚀
📽️ YouTube Recording: youtu.be/0XB7fNS_ONg
📚 Course Website: cvg.ethz.ch/lectures/Robot-L…

5
70
672
54,118
Jefferson Enrique Hernandez Cevallos retweeted

55
129
1,023
894,444
Jefferson Enrique Hernandez Cevallos retweeted

🚨Typical RL algorithms and on-policy distillation methods are blind samplers: they use privileged info to score rollouts, but not to *find* them.
We ask: can we use privileged info to *actively sample* the rollouts RL wishes it can stumble upon with compute?
⤵️ Pedagogical RL

16
87
498
114,388
Jefferson Enrique Hernandez Cevallos retweeted

May 14
Test-time scaling, reasoning, and generally search-like processes clearly drive significant gains in LLMs. Largely owed to the structure of language. One would think the same could apply to non-linguistic domains, like image generation, but that obviously depends on whether the structure of the domain's representation lends itself to search.
1D ordered tokens (e.g., image FlexTok, video FlexTok) seem like a natural fit since they enable a step-by-step coarse-to-fine generation. We investigated that and found they indeed enable search and scale far better with test-time compute than 2D grids. See the visuals on the webpage. Appearing in @icmlconf 2026.
🔗 soto.epfl.ch
📄 arxiv.org/abs/2604.15453,
5
31
138
14,835



Jefferson Enrique Hernandez Cevallos retweeted

Introducing Flux Matching, a generative modeling paradigm that generalizes diffusion models to vector fields that need not be the score function.
Enables structural priors in the dynamics, faster sampling, interpretable generation, and more!
w/ @StefanoErmon @Xiaojie_Qiu 🧵⤵️
21
159
994
144,100
Jefferson Enrique Hernandez Cevallos retweeted

🧵 1/11 Everyone's doing on-policy distillation now (Qwen3, Deepseek V4, GLM-5).
But here's what nobody's asking: at any given token or for a question and a teacher, when does the teacher's guidance actually help, and when does it quietly make things worse?
We found a way to answer this. No training needed!

4
51
437
29,660
Jefferson Enrique Hernandez Cevallos retweeted

May 12
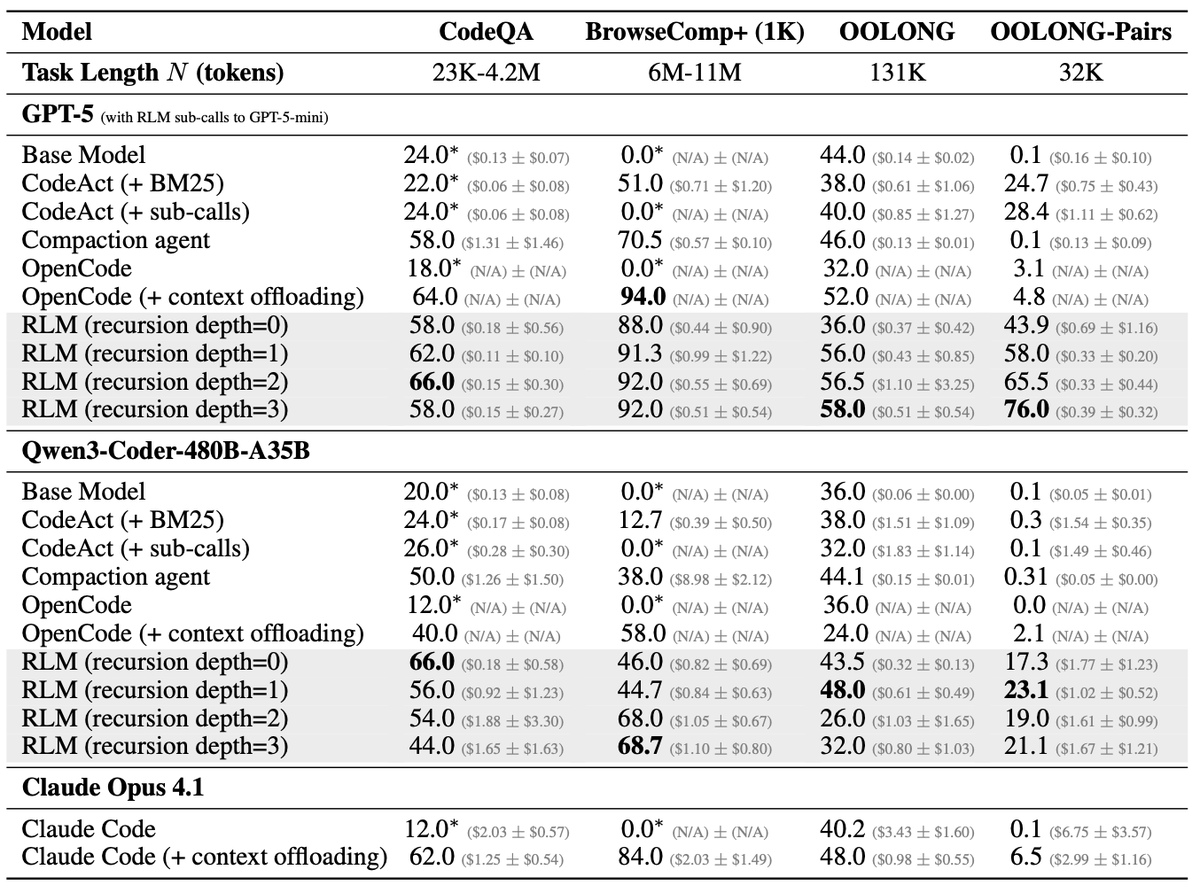
RLM arXiv paper update: depth>1 results, more comparisons, more training, and more error analysis!
We add depth=2/3 experiments, where the RLM now has access to recursive RLM calls. This is also a feature of the open source `rlm` repo as well. We observe significant performance gains on OOLONG-Pairs and gains on all other benchmarks!
We also include various OpenCode and Claude Code comparisons now per popular request.
We add a length generalization experiment on MRCRv2 to show more promising training results, add a small prompting case study on OOLONG, and update the error analysis section to discuss the effect of syntax errors, decomposition mistakes, and general observations from the RLM trajectories.
The appendix is now also updated with several new experiments and plots!
5
35
233
11,350
Jefferson Enrique Hernandez Cevallos retweeted

May 12
"The Truth Lies Somewhere in the Middle (of the Generated Tokens)"
In autoregressive language models, mean pooling hidden states across generation yields better representations than any token alone.
project page: sophielwang.com/tokens
w/ @phillip_isola and @thisismyhat
9
68
471
50,045

Reproducing all of Schmidhuber’s papers (1990-2025) using an AI coding assistant.
Cool project by @yaroslavvb! It even reproduced the “World Models” paper by me and @SchmidhuberAI with a toy env, with a full VAE RNN world model implementation.
Project: github.com/cybertronai/schmi…
44
155
1,089
94,980