
Twitter account of the Vision, Language and Learning Lab, Computer Science @ Rice University.
Joined June 2020
- Tweets 94
- Following 1,202
- Followers 3,082
- Likes 1,124
14 Photos and videos














vislang.ai retweeted
The Rice Workshop on LLMs, organized by @hanjie_chen and @bluevincent, explored AI safety, interpretability & human-AI collaboration. Key takeaway: progress depends on reliability, transparency, and stronger human alignment. bit.ly/4s8Vgbw




3
9
1,493
vislang.ai retweeted
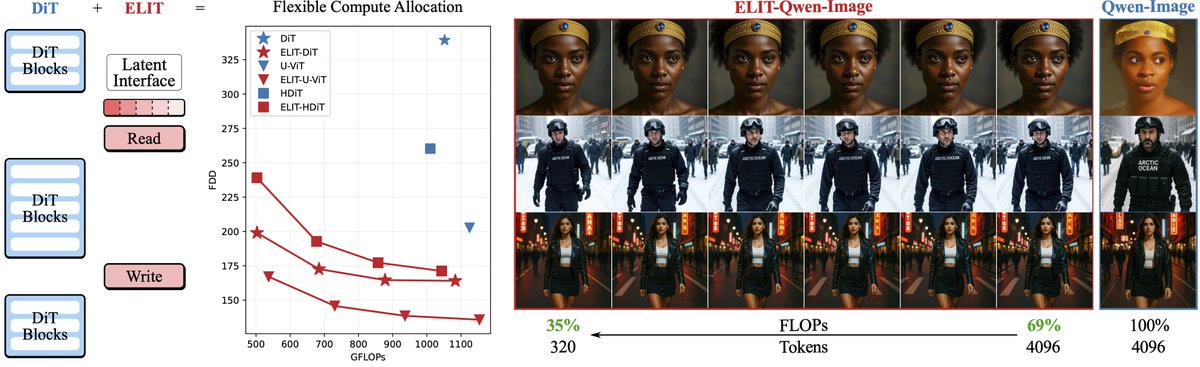
Not all pixels are equally hard, but DiTs still allocate compute uniformly across pixels, wasting efforts on easy regions. ELIT adds two lightweight cross-attention layers to focus compute where it matters, cutting FID by 53%.
ELIT: snap-research.github.io/elit

4
21
161
13,290
vislang.ai retweeted

Mar 15
Diffusion transformers waste compute by treating every pixel equally, regardless of content complexity. ELIT (Elastic Latent Interface Transformer) fixes this with a simple idea: insert a variable length set of latent tokens that learn where to spend computation.
Two lightweight cross attention layers (Read/Write) route information between spatial tokens and latents. The model learns importance ordering during training by randomly dropping tail latents, so earlier tokens capture global structure while later ones handle fine details.
Results on ImageNet 1K at 512px: 35.3% better FID, 39.6% better FDD scores, ~33% cheaper classifier free guidance. Works across DiT, UViT, HDiT, and MMDiT architectures with no changes to the training objective.
By Moayed Haji Ali, @vislang (Rice University), @SergeyTulyakov, Aliaksandr Siarohin, Willi Menapace, Ivan Skorokhodov and team at @Snap.
Accepted at CVPR 2026.
1
2
5
311
vislang.ai retweeted

Feb 6
🚀 Two papers accepted to #ICLR2026 on test-time scaling for vision-language systems (retrieval reasoning)!
1) MetaEmbed (Oral Presentation): Meta Tokens Matryoshka multi-vector training → flexible late interaction, choose #vectors at test time for accuracy↔efficiency.
Paper: arxiv.org/abs/2509.18095
Work done at @AIatMeta with amazing collaborators: Qi Ma, @Mengting_Gu, Jason Chen, Xintao Chen, @vislang and @MohanVijaimohan!
2) ProxyThinker: training-free test-time guidance from small “slow-thinking” visual reasoners → self-verification / self-correction via distribution-level guidance.
Paper: arxiv.org/abs/2505.24872
Work done with @JaywonK17250, @Siru_Ouyang, @jefehern, @yumeng0818 and @vislang!
While I won't be able to travel to Brazil🇧🇷, please say Hi to the team :-)
#MultimodalRetrieval #VisualReasoning #VisionLanguage #TestTimeCompute #Embeddings
4
20
90
20,149


vislang.ai retweeted

23 Sep 2025
Meta Superintelligence Labs presents MetaEmbed: Scalable multimodal retrieval
• Flexible late interaction via Meta Tokens
• Test-time scaling: trade off retrieval accuracy vs efficiency
• SOTA on MMEB ViDoRe, robust up to 32B models
• Matryoshka training → coarse-to-fine multi-vector embeddings

6
42
315
54,430
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
abs: arxiv.org/abs/2112.07133
CLIP-Lite obtains a 15.4% mAP absolute gain in performance on Pascal VOC classification, and
a 22.1% top-1 accuracy gain on ImageNet

10
99
vislang.ai retweeted
11 Jun 2025
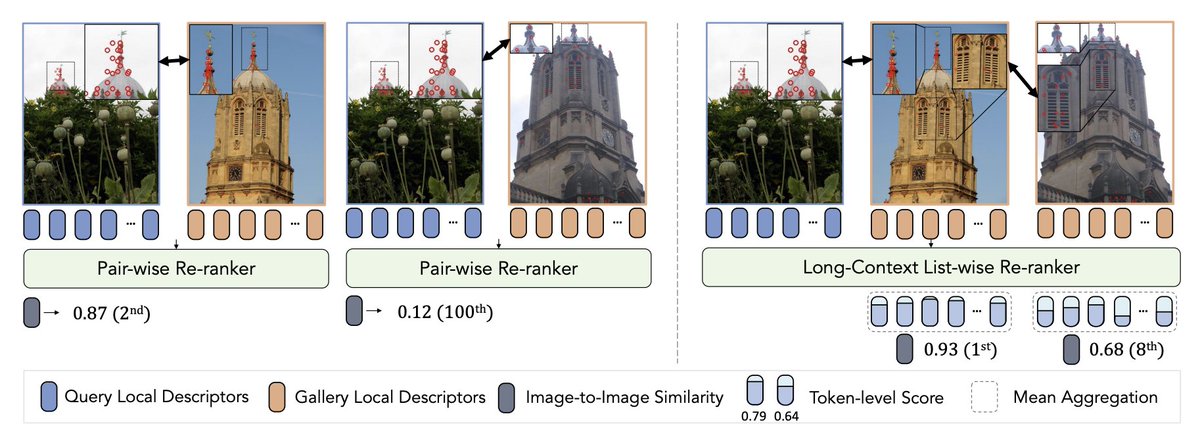
Looking for a new (image) re-ranking paradigm? Check this out! LoCoRe (Long-Context Reranker) is trained with a long-context sequence model and token-level supervision to achieve **one-pass** re-ranking for all image candidates.
Catch us at #CVPR Poster Session 2 #401 on Friday, 4pm-6pm!
1
3
12
764

14 Jan 2025
Check our new work on cross-modal audio-video generation. Our work produces audio with the best alignment we have seen with respect to actions happening on video. Particularly useful in the era of astounding progress in generative video models.
14 Jan 2025

Can pretrained diffusion models connect for cross-modal generation?
📢 Introducing AV-Link ♾
Bridging unimodal diffusion models in one framework to enable:
📽️ ➡️ 🔊 Video-to-Audio
🔊 ➡️ 📽️ Audio-to-Video
🌐: snap-research.github.io/AVLi…
📄: hf.co/papers/2412.15191
⤵️ Results
1
3
562
vislang.ai retweeted

14 Jan 2025
Can pretrained diffusion models connect for cross-modal generation?
📢 Introducing AV-Link ♾
Bridging unimodal diffusion models in one framework to enable:
📽️ ➡️ 🔊 Video-to-Audio
🔊 ➡️ 📽️ Audio-to-Video
🌐: snap-research.github.io/AVLi…
📄: hf.co/papers/2412.15191
⤵️ Results
2
12
23
6,008
vislang.ai retweeted

4 Oct 2024
Rice is shaping the future of AI! Our researchers are working on groundbreaking methods to eliminate the "weird" or distorted images that AI sometimes generates. This innovation could lead to more accurate and realistic visuals created by artificial intelligence. The future of AI-generated imagery is looking clearer and brighter thanks to our researchers! 🔍💡Read more about this fascinating research and its potential impact: bit.ly/4ezY37m #RiceU #FutureOfAI #Innovation

1
12
751
vislang.ai retweeted
28 Sep 2024
I am excited to share that two of our research works will be presented at ECCV 2024. #ECCV2024 They focus on augmenting language models with fine-grained visual recognition ability.
AutoVER made successful attempts at generative visual recognition. It was accepted to the ECCV 2024 main conference and was invited to the ILR Workshop as an oral presentation. Collaboration w/ @pcascanteb @vislang #Microsoft
Extractive Reranker was accepted to the ILR Workshop as a poster. We explored how the long-context sequence modeling ability of language models can benefit image retrieval, a fundamental computer vision problem.



4
8
1,099
vislang.ai retweeted

17 Sep 2024
Rice CS welcomes Zhengzhong Tu, Texas A&M assistant professor, next Tuesday, 9/24 at 4pm in Duncan Hall 3076. Dr. Tu will discuss Democratizing Diffusion Models for Controllable & Efficient Computational Imaging.
PLEASE RSVP: bit.ly/4eraBh1
@_vztu @vislang

4
8
1,426
vislang.ai retweeted
13 Sep 2024
GenAI has struggled to create consistent images, but research from Rice CS' @vislang lab could make weird AI images a thing of the past. Moayed Haji Ali and Vicente Ordónez-Román have developed a way to improve the performance of AI diffusion models.
bit.ly/3BcIlQQ

1
3
380
vislang.ai retweeted
13 Aug 2024
Rice CS' @cathyrzhe presented her paper, Improved Visual Grounding through Self-Consistent Explanations, at @CVPR 2024. SelfEQ helps computers ‘see’ more accurately and consistently. She is advised by faculty member Vicente Ordóñez-Román. bit.ly/4dfe9CS @vislang

3
7
1,049
19 Jun 2024
Check out the work by @cathyrzhe who is representing our group at #CVPR2024 at the poster session tomorrow morning. Poster #334. #CVPR.
19 Jun 2024

(1/4) Excited to share our latest work at #CVPR2024 @CVPR!🔥
Join us tomorrow, Thursday, June 20, from 10:30am to noon at Poster Session 3, # 334, to learn about "Improved Visual Grounding through Self-Consistent Explanations" with @pcascanteb, Ziyan, @alexandercberg, @vislang.

2
736
vislang.ai retweeted

19 Jun 2024
(1/4) Excited to share our latest work at #CVPR2024 @CVPR!🔥
Join us tomorrow, Thursday, June 20, from 10:30am to noon at Poster Session 3, # 334, to learn about "Improved Visual Grounding through Self-Consistent Explanations" with @pcascanteb, Ziyan, @alexandercberg, @vislang.
1
2
5
1,694
vislang.ai retweeted

11 Jun 2024
Chatted with @cathyrzhe and @pcascanteb from @vislang at @RiceUniversity about the paper they had accepted to @CVPR
Their paper introduces Self-Consistency Equivalence Tuning (SelfEQ) to improve visual grounding in vision-and-language models using paraphrases.
The Problem: Models struggle with precise object localization when textual descriptions vary.
Current methods need detailed annotations and show inconsistency with varied texts.
The Solution: SelfEQ uses paraphrases generated by a large language model and finetunes the model with GradCAM for consistent visual explanations.
How It Works
1) Start with an existing method: Uses ALBEF model without object location annotations.
2) Improvements by SelfEQ: Generates paraphrases and ensures consistent visual attention maps.
Why It's Better
• Expanded Vocabulary: Handles more textual descriptions.
•Improved Localization: Precise and consistent without bounding box annotations.
•Efficiency: Reduces need for detailed annotations.
Key Contributions
• Introduces SelfEQ for better visual grounding.
• Uses large language models for paraphrases.
• Improves performance on benchmarks (Flickr30k, ReferIt, RefCOCO ).
#CVPR2024 #CVPR
2
6
8
1,040
vislang.ai retweeted

27 Feb 2024
Great news from #CVPR2024 🎉🎉🎉
Happy to share that our paper ElasticDiffusion: Training-free Arbitrary Size Image Generation was accepted @CVPR.
Big thanks to my collaborators @bluevincent and Guha Balakrishnan.
Checkout more details from here: elasticdiffusion.github.io/

2
5
21
2,311
vislang.ai retweeted

13 Dec 2023
How do biases change before and after finetuning large scale visual recognition models? Our @afciworkshop paper incorporates sets of canonical images to highlight changes in biases for an array of off-the-shelf pretrained models. #NeurIPS2023
Link: arxiv.org/abs/2303.07615

1
1
10
4,414