
PhD student @ CompVis Group, LMU Munich
Joined January 2021
- Tweets 62
- Following 547
- Followers 291
- Likes 469
26 Photos and videos








Pinned Tweet

Apr 27
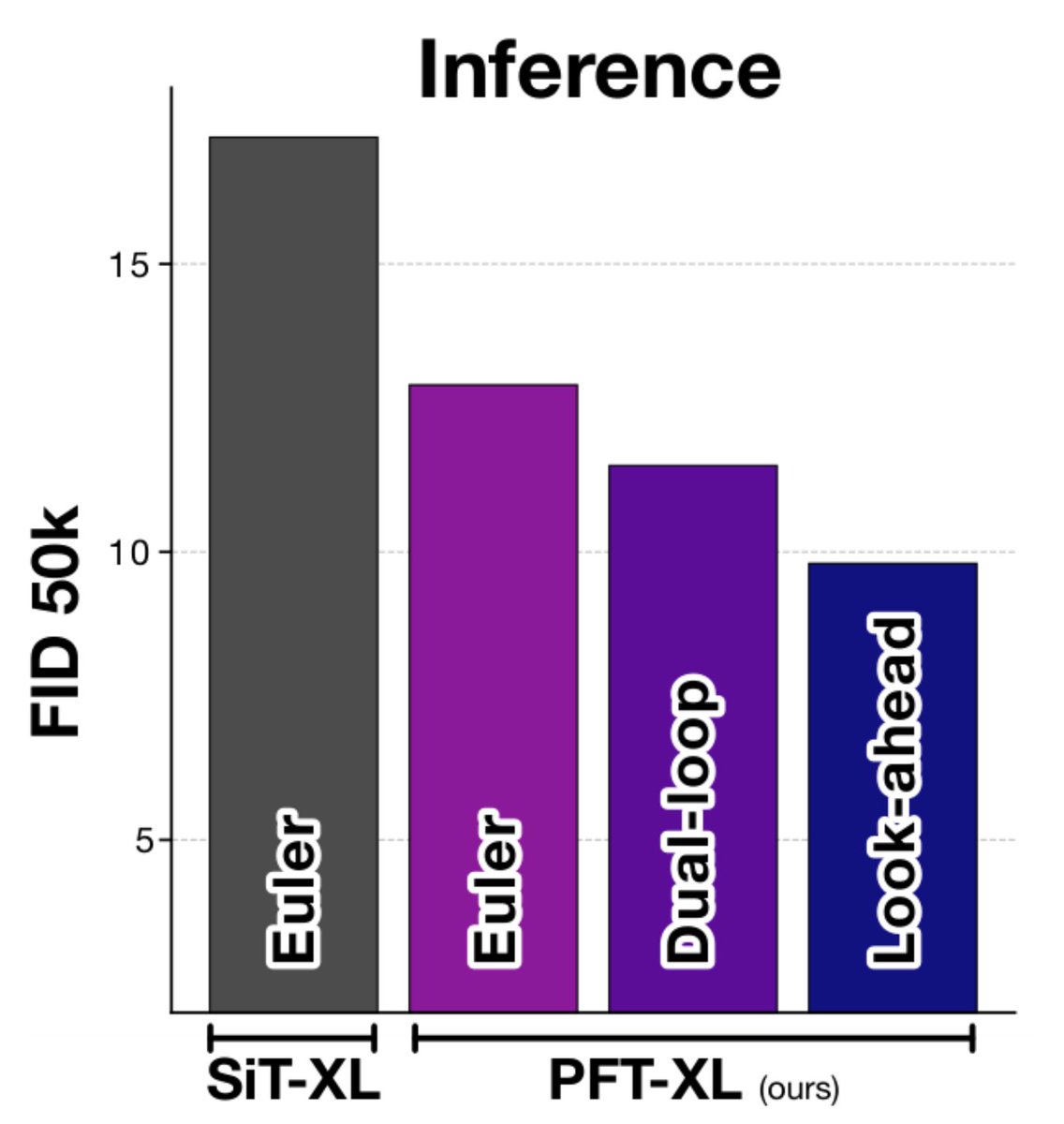
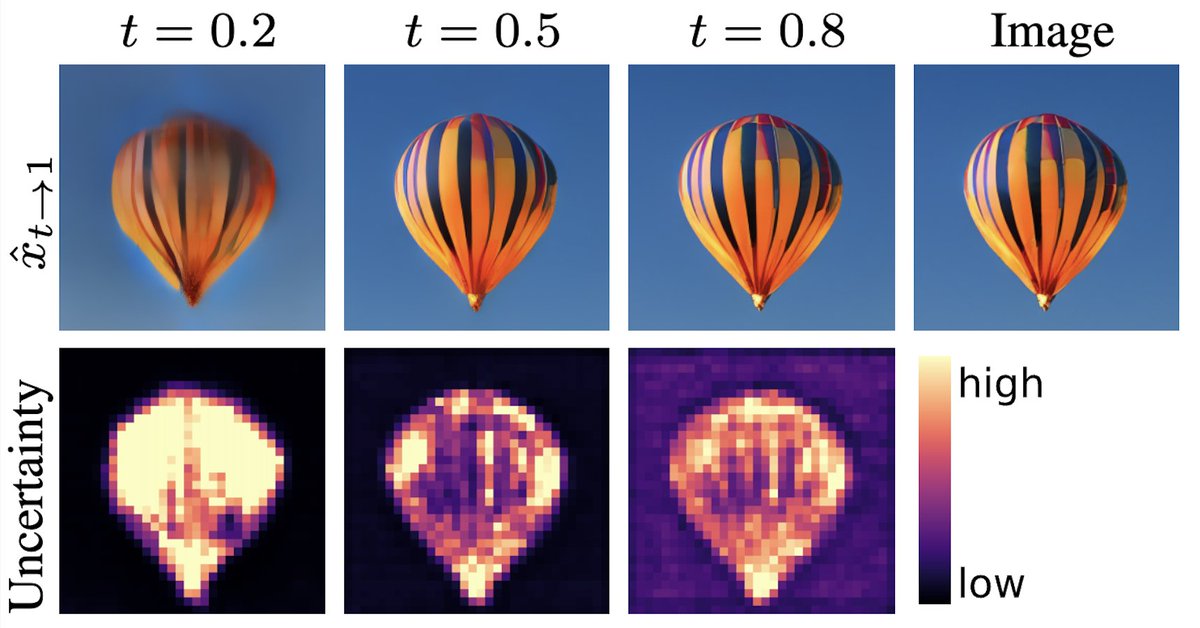
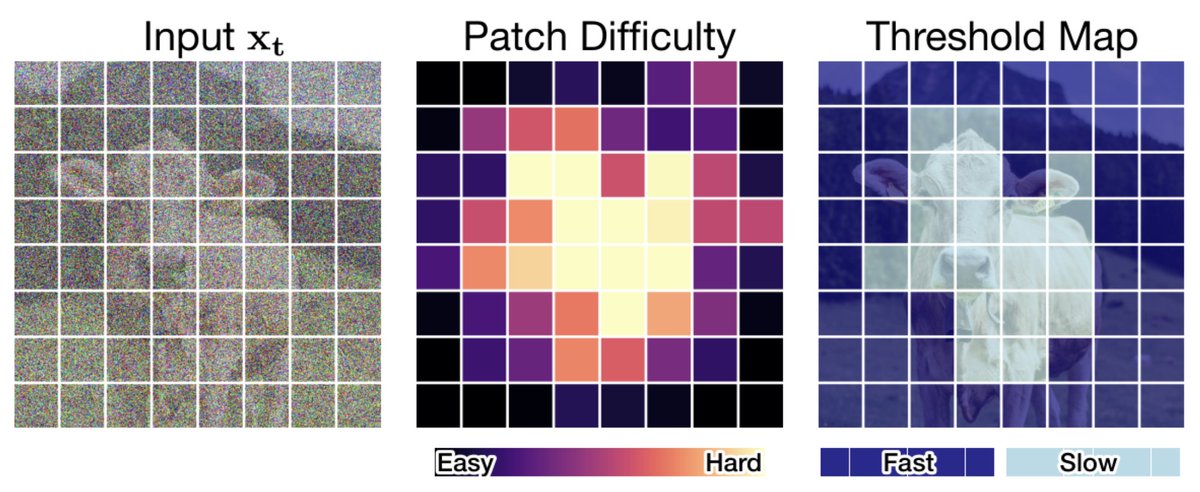
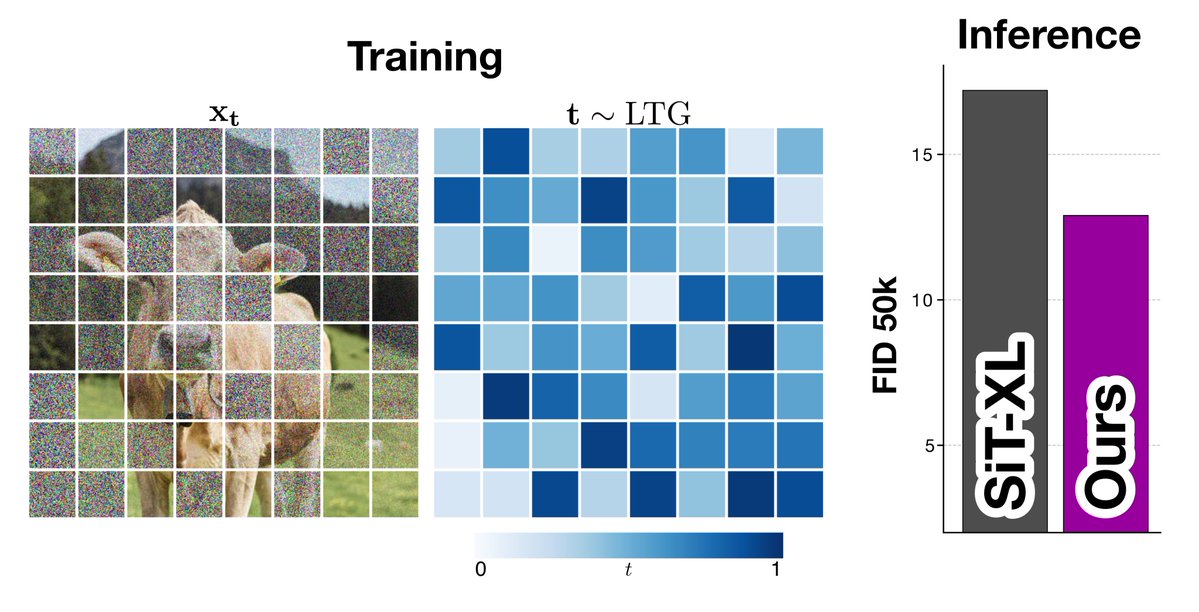
Diffusion models treat every part of an image equally.
→ Same number of steps. Same compute.
But images aren’t uniform. 🤔
Some regions are easy, others are hard.
So why force the model to treat them the same? 🧵
11
82
588
76,011
Jun 4
I am at @CVPR in Denver this week.
If you’re around and want to chat, feel free to send me a DM or stop by one of the two posters I’ll be presenting👇
1
5
445
Jun 4
Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation
🕐Sun 7th, 3:30 PM - 5:30 PM
📍ExHall A 658
x.com/jo_schb/status/2048765…
Apr 27

Diffusion models treat every part of an image equally.
→ Same number of steps. Same compute.
But images aren’t uniform. 🤔
Some regions are easy, others are hard.
So why force the model to treat them the same? 🧵
1
2
235
Jun 4
Probabilistic Precipitation Nowcasting with Rectified Flow Transformers
🕐Sat 6th, 4:45 - 6:45 PM
📍ExHall A & F 401
x.com/jo_schb/status/2062333…
Jun 4
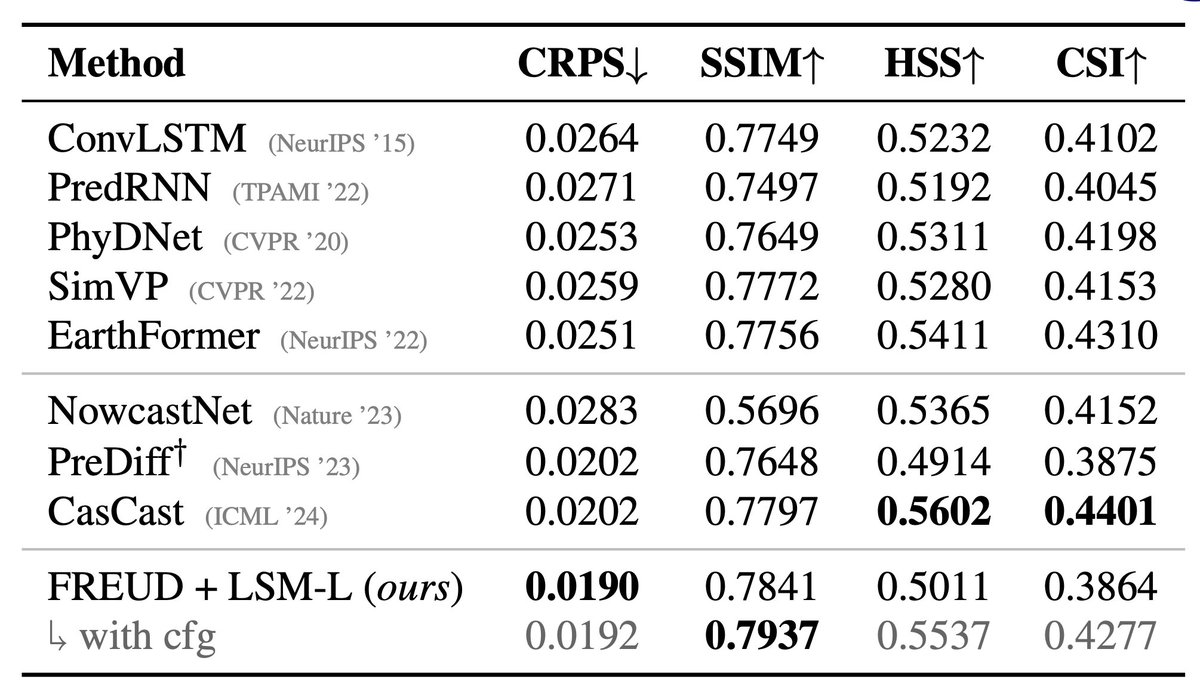
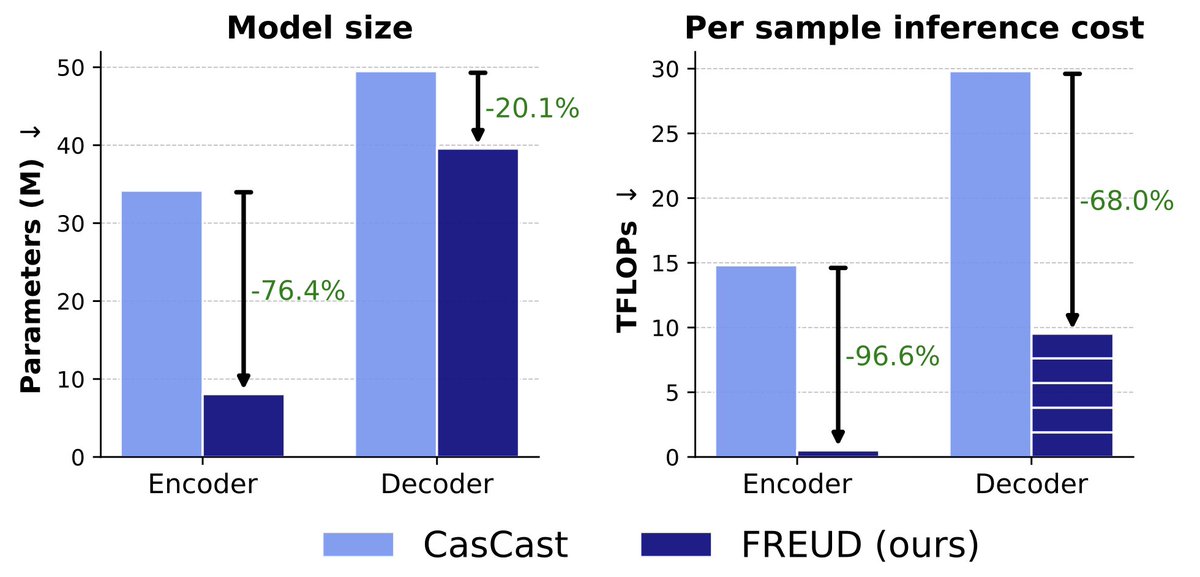
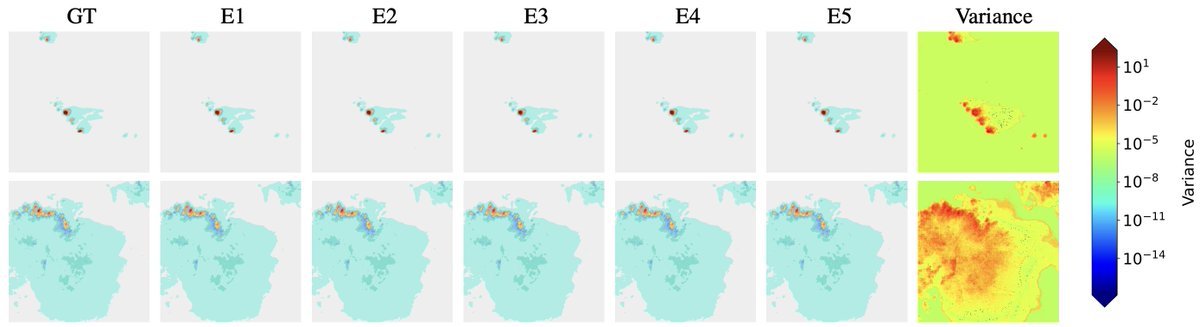
⚠️ Standard first stages are not sufficient for safety-critical applications!
The most extreme weather events are often the hardest to decode.
One latent → many plausible reconstructions
Deterministic decoders hide that uncertainty.
Meet FREUD 🧵👇
1
2
214
Jun 4
⚠️ Standard first stages are not sufficient for safety-critical applications!
The most extreme weather events are often the hardest to decode.
One latent → many plausible reconstructions
Deterministic decoders hide that uncertainty.
Meet FREUD 🧵👇
2
7
10
1,271
Jun 4
For more information:
Project page: compvis.github.io/weather-rf
Paper: arxiv.org/abs/2605.31204
Code: github.com/CompVis/weather-r…
1
3
79
jo.schb ✈️CVPR retweeted

The internet is full of video. So why can't novel view synthesis just scale on it?
Real-world video is simultaneously unposed, messy, and dynamic, breaking self-supervised NVS.
We fixed that. RayDer learns static-scene NVS from dynamic internet video, scaling like an LLM. A🧵
7
35
153
14,181
Apr 27
Diffusion models treat every part of an image equally.
→ Same number of steps. Same compute.
But images aren’t uniform. 🤔
Some regions are easy, others are hard.
So why force the model to treat them the same? 🧵
11
82
588
76,011
Apr 27
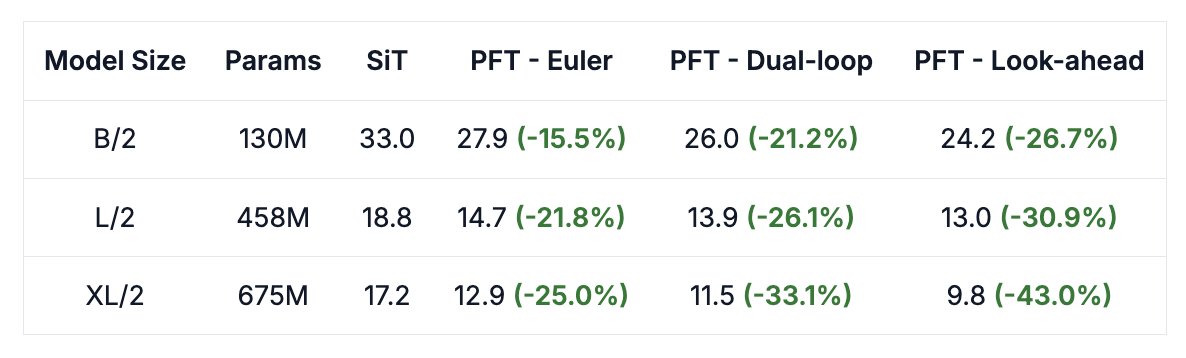
Takeaway 🚀
• Diffusion shouldn’t treat all regions equally
• Patch-wise timesteps improve performance, if done right
• Allocating compute where it matters gives further gains
Project Page: compvis.github.io/patch-forc…
arXiv: arxiv.org/abs/2604.19141
Code: github.com/CompVis/patch-for…
1
3
44
2,681
Apr 27
Joint work with @MingGui725184, @Yusong53080064 , @PingchuanMa4, @felix_m_krause, and Björn Ommer! 🫶
6
1,369