
Joined July 2024
- Tweets 65
- Following 336
- Followers 232
- Likes 212
12 Photos and videos








Pinned Tweet

Apr 14
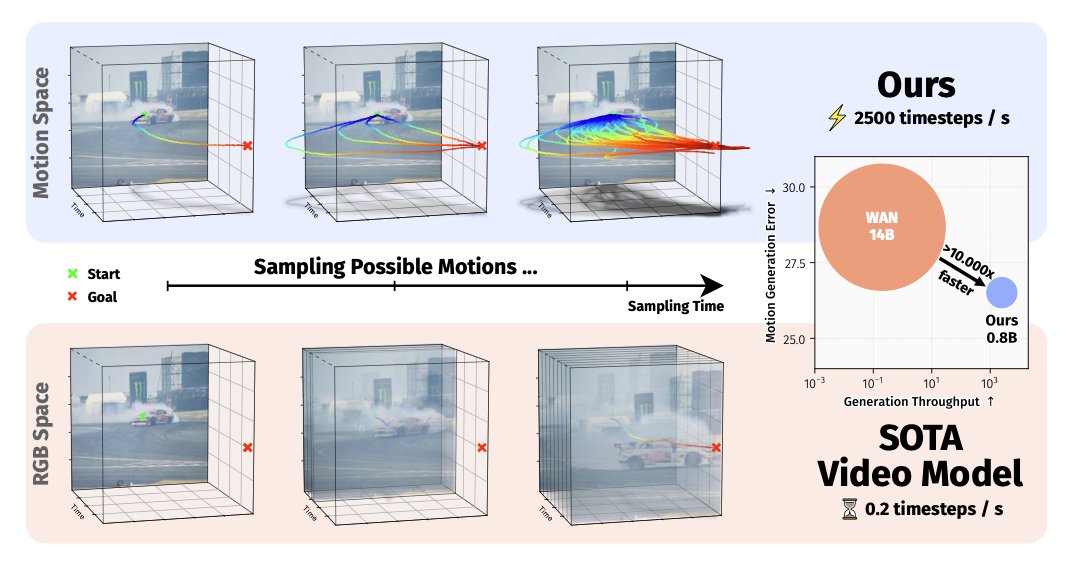
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
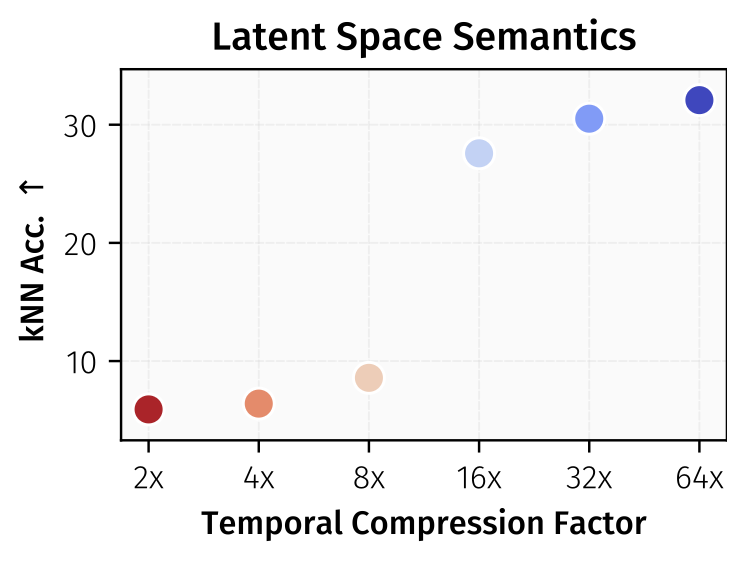
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
10
48
337
48,604
Nick Stracke retweeted

Another crazy CVPR 2026 world model result.
“Envisioning the Future” forecasts where points in a scene will move, step by step, from a single image. No dense video needed.
- 3,000x faster than video models, 10x fewer parameters, and 5x more accurate under a fixed compute budget.
- An autoregressive diffusion model rolls sparse point trajectories forward through short, predictable steps, modeling uncertainty as it grows.
- Why it matters: Rollouts get cheap enough to simulate thousands of futures and plan over them, hitting 78% billiard planning accuracy vs 16% for the best dense video baseline.

4
20
829
Nick Stracke retweeted

Jun 8
second runner up is a super cool paper from Björn Ommer’s group at LMU.
they first encode point trajectories into a latent using a VAE. then they learn to denoise future trajectories conditioned on past.
they do planning experiments on Libero by training a small decoder to convert denoised latents to robot action.
I joked that this is latent stable diffusion all over again by Björn but this time with point trajectories 😄

1
3
23
1,398
Nick Stracke retweeted

Jun 7
ZipMo hands a robot its plan by daydreaming how the scene should move.
No pixels, no rendering, no hour-long video to sit through.
10,000x faster than a top video model!
Just a fast read on where everything's headed, and the robot runs with it.
Give it a start frame and a goal in plain language.
It predicts how the arm and the objects around it should move to get there.
A thin policy head reads that motion plan and turns it into the next arm command.
The head never sees the task, only the predicted motion.
So all the reasoning lives in the motion model.
The head is pure inverse dynamics, motion in, action out.
On the LIBERO benchmark it replans on every new frame, and it beats the trajectory-based policy methods it lines up against: ATM, Tra-MoE, Amplify.
It pulls this off by never touching pixels.
It learns a compact motion space from tracked trajectories, then generates motion straight inside that space.
And stranger still, compressing that space 64x makes the motion sharper, not worse.
Congrats to the team, lovely work. @rmsnorm, @KoljaBauer, @StefanABaumann
Jun 7

Come visit our poster today (Sunday) 3:30 pm at CVPR poster 595! We'll also show some new results on translating the generated motion embeddings back to video 👇
1
6
11
1,459
Jun 7
Come visit our poster today (Sunday) 3:30 pm at CVPR poster 595! We'll also show some new results on translating the generated motion embeddings back to video 👇
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
2
4
26
5,271
Jun 7
Here using LTX 2! This allows us to efficiently explore many possible futures and render only the most relevant ones back into video.
2
167
Nick Stracke retweeted

You don't need a video model to predict motion. We'll talk about how to be 3000× faster at CVPR Poster 634, this morning at 10:45. Drop by and check it out!
Apr 13

You don't imagine the future by mentally rendering a movie. You trace how things move -- abstractly, sparsely, step by step.
We built a model that does exactly this. It predicts motion, not pixels -- and it's 3,000× faster than video world models.
Myriad, accepted at @CVPR 2026

1
6
43
5,109
Nick Stracke retweeted

Jun 4
⚠️ Standard first stages are not sufficient for safety-critical applications!
The most extreme weather events are often the hardest to decode.
One latent → many plausible reconstructions
Deterministic decoders hide that uncertainty.
Meet FREUD 🧵👇
2
7
10
1,269
Jun 1
Check out our work on how to scale NVS on internet-scale data! We provide fixes to the unsupervised NVS pipeline (RayZer) and also obtain more interpretable pose estimations while simplifying the overall setup.
The internet is full of video. So why can't novel view synthesis just scale on it?
Real-world video is simultaneously unposed, messy, and dynamic, breaking self-supervised NVS.
We fixed that. RayDer learns static-scene NVS from dynamic internet video, scaling like an LLM. A🧵
1
8
730
Apr 27
💡 Training with differently noised patches increases overall image gen performance, as the model learns a better underlying representation.
This holds even for plain Euler sampling, but their sampler increases the gap even more!
Apr 27

Diffusion models treat every part of an image equally.
→ Same number of steps. Same compute.
But images aren’t uniform. 🤔
Some regions are easy, others are hard.
So why force the model to treat them the same? 🧵
29
4,379
Nick Stracke retweeted

Apr 15
Cool stuff
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
5
36
7,716
Nick Stracke retweeted
Apr 14
Stop predicting motion step-by-step. Model the whole motion in a compact representation for efficient planning.
📄 Paper: arxiv.org/abs/2604.11737
💻 Models: compvis.github.io/long-term-…
Joint work with @KoljaBauer, @StefanABaumann, @itsbautistam, Josh Susskind, and Björn Ommer.
1
6
30
2,731
Nick Stracke retweeted

Amazing work led by @rmsnorm @KoljaBauer and our collaborators at LMU, to be presented at @CVPR! Personally, I find this question of "what's the right level of abstraction for planning in physical space?" to be very intriguing. Pixels over time are very low SNR (ie. the argument behind JEPA) but motion/trajectories carries a lot on information while being extremely compressible. I believe there's a lot more to uncover from this direction. Very glad to be part of this one!
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
1
3
14
1,881
Nick Stracke retweeted

Apr 14
A massive step forward for AI video!
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
3
27
5,144

I have been saying
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
1
22
5,297
Nick Stracke retweeted
Apr 14
1️⃣x.com/neerjathakkar/status/2…
Also, shoutout to two other recent works that explore how to use point tracks for world modeling.
👇...
Apr 2

What’s the right representation for a world model? 3D, pixels, or something else?
Excited to release our new paper “Forecasting Motion in the Wild” where we propose point tracks as tokens for generating complex non-rigid motion and behavior
From @GoogleDeepmind @Berkeley_AI @TTIC_Connect
1
4
20
2,185
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
10
48
337
48,604
Apr 14
1️⃣x.com/neerjathakkar/status/2…
Also, shoutout to two other recent works that explore how to use point tracks for world modeling.
👇...
Apr 2
What’s the right representation for a world model? 3D, pixels, or something else?
Excited to release our new paper “Forecasting Motion in the Wild” where we propose point tracks as tokens for generating complex non-rigid motion and behavior
From @GoogleDeepmind @Berkeley_AI @TTIC_Connect
1
4
20
2,185
Apr 14
Apr 13
You don't imagine the future by mentally rendering a movie. You trace how things move -- abstractly, sparsely, step by step.
We built a model that does exactly this. It predicts motion, not pixels -- and it's 3,000× faster than video world models.
Myriad, accepted at @CVPR 2026
2
15
1,056
Nick Stracke retweeted

Apr 14
Do we really need pixel generation to model motion? 🤔
We show how directly representing motion in a compact space enables efficient, scalable planning.
10,000× faster than video models, enabling planning and reasoning in open-world and robotics settings.
Check it out ⬇️
Apr 14
Video diffusion models learn motion indirectly through pixels.
But motion itself is much lower-dimensional.
We introduce 64× temporally compressed motion embeddings that directly capture scene dynamics.
This enables efficient planning -> 10,000× faster than video models.
🧵👇
1
4
30
3,657