
Postdoc @StanfordNLP @StanfordAILab / Prev: @MilaNLProc @UZH_en @MPI_IS @CarnegieMellon. CompSocSci, LLMs, algorithmic fairness.
- Tweets 157
- Following 1,483
- Followers 796
- Likes 455


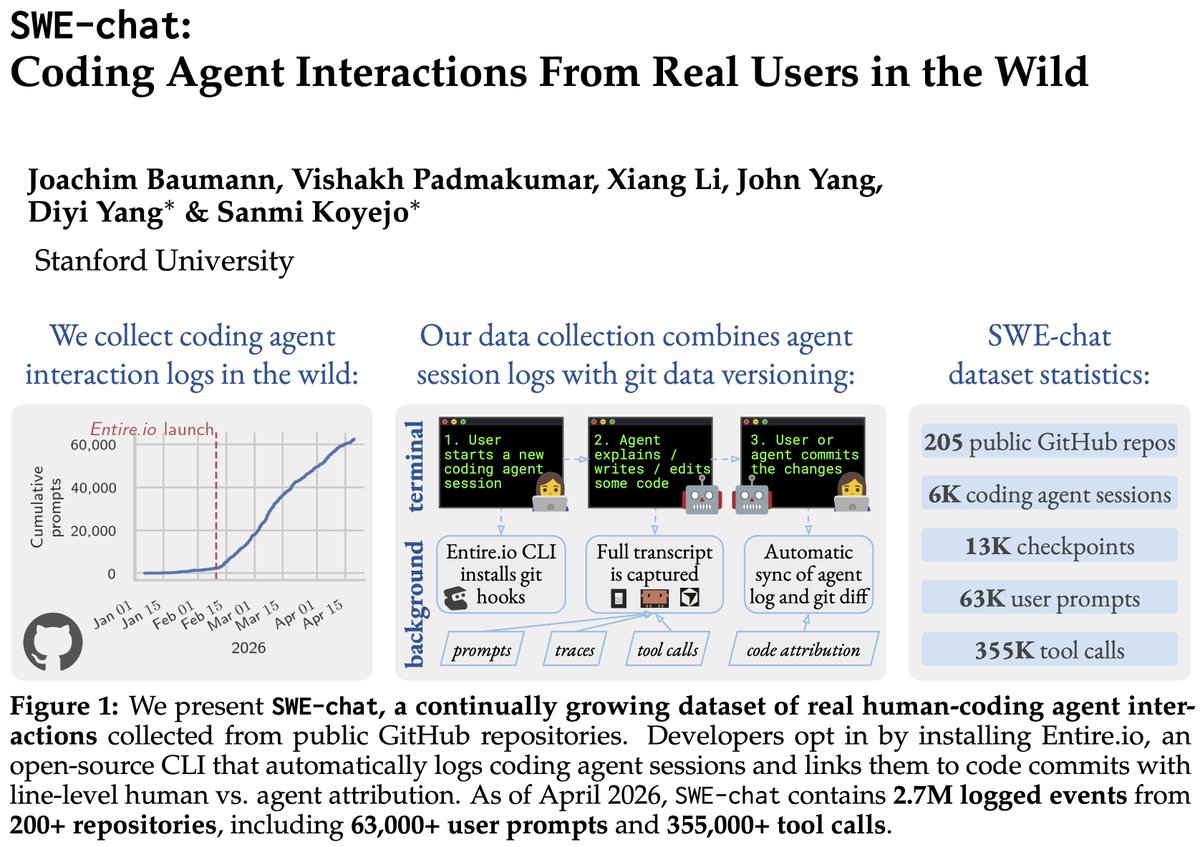




ALT Overview of SWE-chat. Left: a data collection pipeline diagram. Open-source developers install the Entire.io CLI tool, which logs their coding agent sessions and pushes the logs to a dedicated branch on their public GitHub repository. We discover and aggregate these logs into the SWE-chat dataset, with line-level attribution of which lines of code were written by the human versus the agent. Right: a growth chart showing cumulative logged events over time, rising steeply through early 2026. As of April 2026, the dataset contains 2.7 million logged events from over 200 repositories, including 63,000 user prompts and 355,000 agent tool calls across nearly 6,000 sessions.


![Line chart titled "Token purchasing power across the engineering basket — Opus 4.6 in SWE-chat." Subtitle: each line shows units of the good 1 token buys, relative to a Feb 5–24 baseline (1.00×); knowledge capture (teal) erodes least. The full-basket composite ends at 0.23× purchasing power (95% CI [0.18, 0.28]) = 4.38× more tokens per unit. The y-axis is log-scaled "output per token," from ~0.15× to 1×. The x-axis spans five time windows A–E (Feb 05 to Apr 15), labeled as phases: Pre-mystery climb, Mystery climb, Post-mystery climb. Colored lines track five goods: agent-drafted code, PR shipped, file touched, agent-drafted docs, and knowledge capture; a thick black "COMPOSITE" line with a gray 95% CI band trends downward from 1× to 0.23×. Knowledge capture rebounds to 0.37×. Reasoning effort shifts from "high" to "medium" to "high" across phases.](https://venexa.site/media/HKTckEXb0AAUvnF.jpg)
ALT Line chart titled "Token purchasing power across the engineering basket — Opus 4.6 in SWE-chat." Subtitle: each line shows units of the good 1 token buys, relative to a Feb 5–24 baseline (1.00×); knowledge capture (teal) erodes least. The full-basket composite ends at 0.23× purchasing power (95% CI [0.18, 0.28]) = 4.38× more tokens per unit. The y-axis is log-scaled "output per token," from ~0.15× to 1×. The x-axis spans five time windows A–E (Feb 05 to Apr 15), labeled as phases: Pre-mystery climb, Mystery climb, Post-mystery climb. Colored lines track five goods: agent-drafted code, PR shipped, file touched, agent-drafted docs, and knowledge capture; a thick black "COMPOSITE" line with a gray 95% CI band trends downward from 1× to 0.23×. Knowledge capture rebounds to 0.37×. Reasoning effort shifts from "high" to "medium" to "high" across phases.





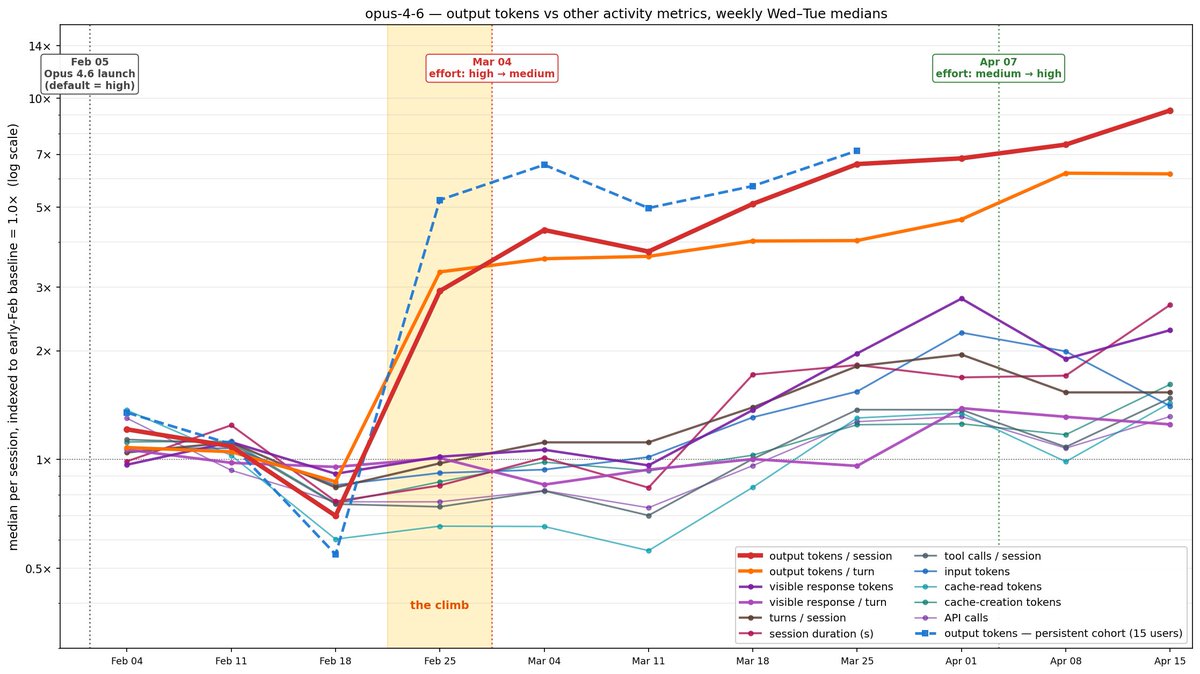
ALT Line chart titled "opus-4-6 — output tokens vs other activity metrics, weekly Wed–Tue medians." X-axis spans Feb 04 to Apr 13; y-axis is median per session, indexed to early-Feb baseline of 1.0x, on a log scale from 0.5x to 14x. Annotations mark the "Opus 4.6 launch" (Feb 05), an effort change "high → medium" (Mar 04), and "medium → high" (Apr 07). A shaded band around Feb 25–Mar 04 is labeled "the climb." Most metrics start near 1x and stay flat through mid-Feb, then rise. Output tokens per session (bold red) and per turn (orange) climb sharply to roughly 8–9x by Apr 13, the highest lines. A dashed blue line (output tokens, persistent cohort, 15 users) tracks similarly but ends earlier. Other metrics — tool calls, visible response tokens, cache tokens, API calls, session duration — rise more modestly to about 1.5–3x.

ALT Line chart titled "opus-4-6 output_tokens by week, with Anthropic's postmortem events overlaid." X-axis: week start (Wed), Feb 1–Apr 15, 2026. Y-axis: median output_tokens per session (log scale), 10³ to ~30,000. Two lines: red solid ("all opus-4-6, 3,917 sessions") and blue dashed ("persistent cohort, 15 users/943 sess."). Both start ~2,500–3,000 tokens early Feb, dip to a low ~1,000–1,800 around Feb 22, then climb sharply, ending near 25,000–30,000 by mid-April. Annotations: "Opus 4.6 launches with reasoning effort high" (early Feb); orange "What happened here?" near the dip; vertical lines mark "effort default high→medium" (Mar 4, red), "thinking-clearing bug ships" and "bug fixed" (purple), "effort default medium→high" (green). Shaded band marks medium-effort default (Mar 4–Apr 7).


ALT Line chart titled "opus-4-6 output_tokens by week, with Anthropic's postmortem events overlaid." X-axis: week start (Wed), Feb 1–Apr 15, 2026. Y-axis: median output_tokens per session (log scale), 10³ to ~30,000. Two lines: red solid ("all opus-4-6, 3,917 sessions") and blue dashed ("persistent cohort, 15 users/943 sess."). Both start ~2,500–3,000 tokens early Feb, dip to a low ~1,000–1,800 around Feb 22, then climb sharply, ending near 25,000–30,000 by mid-April. Annotations: "Opus 4.6 launches with reasoning effort high" (early Feb); orange "What happened here?" near the dip; vertical lines mark "effort default high→medium" (Mar 4, red), "thinking-clearing bug ships" and "bug fixed" (purple), "effort default medium→high" (green). Shaded band marks medium-effort default (Mar 4–Apr 7).











ALT Overview of SWE-chat. Left: a data collection pipeline diagram. Open-source developers install the Entire.io CLI tool, which logs their coding agent sessions and pushes the logs to a dedicated branch on their public GitHub repository. We discover and aggregate these logs into the SWE-chat dataset, with line-level attribution of which lines of code were written by the human versus the agent. Right: a growth chart showing cumulative logged events over time, rising steeply through early 2026. As of April 2026, the dataset contains 2.7 million logged events from over 200 repositories, including 63,000 user prompts and 355,000 agent tool calls across nearly 6,000 sessions.




