
Stanford PhD working on #AI4Science and maintaining Terminal-Bench Science @StanfordAILab 🧬🤖🪐
Joined January 2020
- Tweets 173
- Following 1,483
- Followers 553
- Likes 1,480
15 Photos and videos








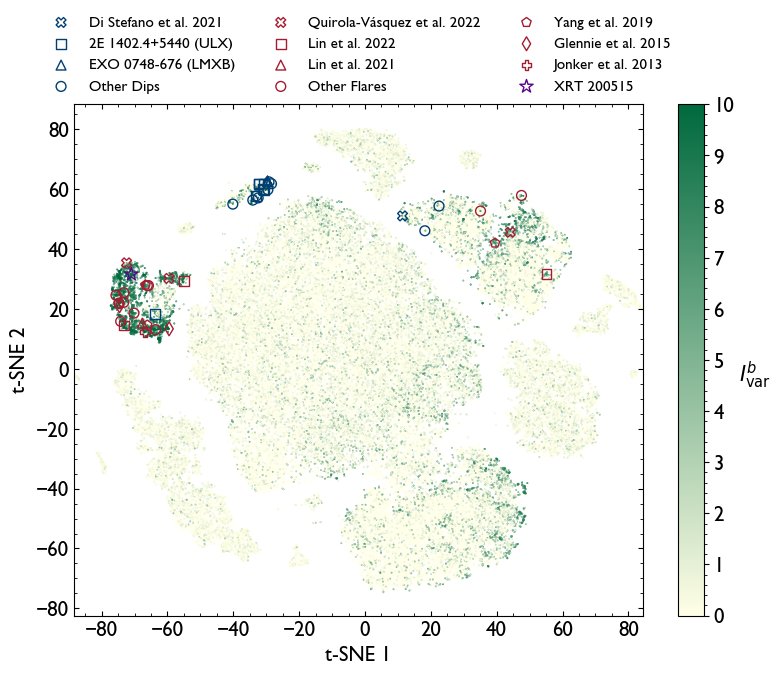
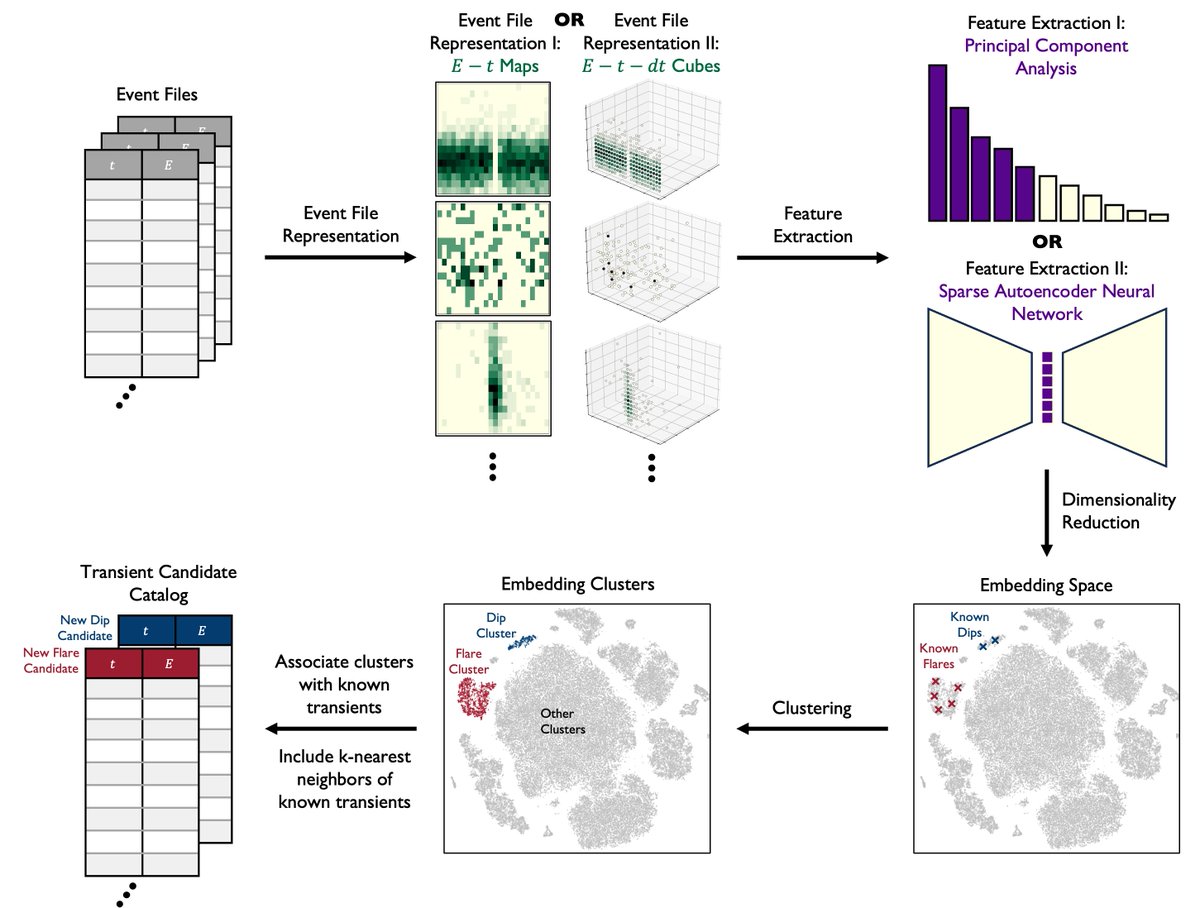




Pinned Tweet

May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
16
111
495
905,338
Steven Dillmann retweeted

Jun 11
@novita_labs is hosting a Harbor/Terminal-Bench hackathon, consider joining!
Jun 10

The Harbor x Novita Agent Sandbox Hackathon is live.
Build and benchmark AI agents on Terminal-Bench 2.1 tracks with @harborframework Novita Agent Sandbox.
Special thanks to @alexgshaw for supporting the integration.
🎁 New users get $100 in free Novita Agent Sandbox usage
🏆 Compete for $2,800 in hackathon credits
🌎 Fully remote
⏰ Submit by Jul 3, 11:59 PM PT
Join the hackathon:
events.novita.ai/
#NovitaSandbox #Harbor #AIAgents
1
3
19
1,193
Steven Dillmann retweeted

Jun 8
Seeing a number of benchmarks showing Opus is the best model for long-running work.
Five tips for running Opus autonomously for hours/days:
1. Use auto mode for permissions, so Claude doesn’t ask for approval
2. Use dynamic workflows, to have Claude orchestrate hundreds/thousands of agents to get a task done
3. Use /goal or /loop, to nudge Claude to keep going until it’s done
4. Use Claude Code in the cloud, so you can close your laptop (easiest way is the desktop or mobile app)
5. Make sure Claude has a way to self-verify its work end to end: Claude in Chrome browser extension for web, iOS/Android sim MCP for mobile, a way to start the full web server or service for backend work
Jun 5

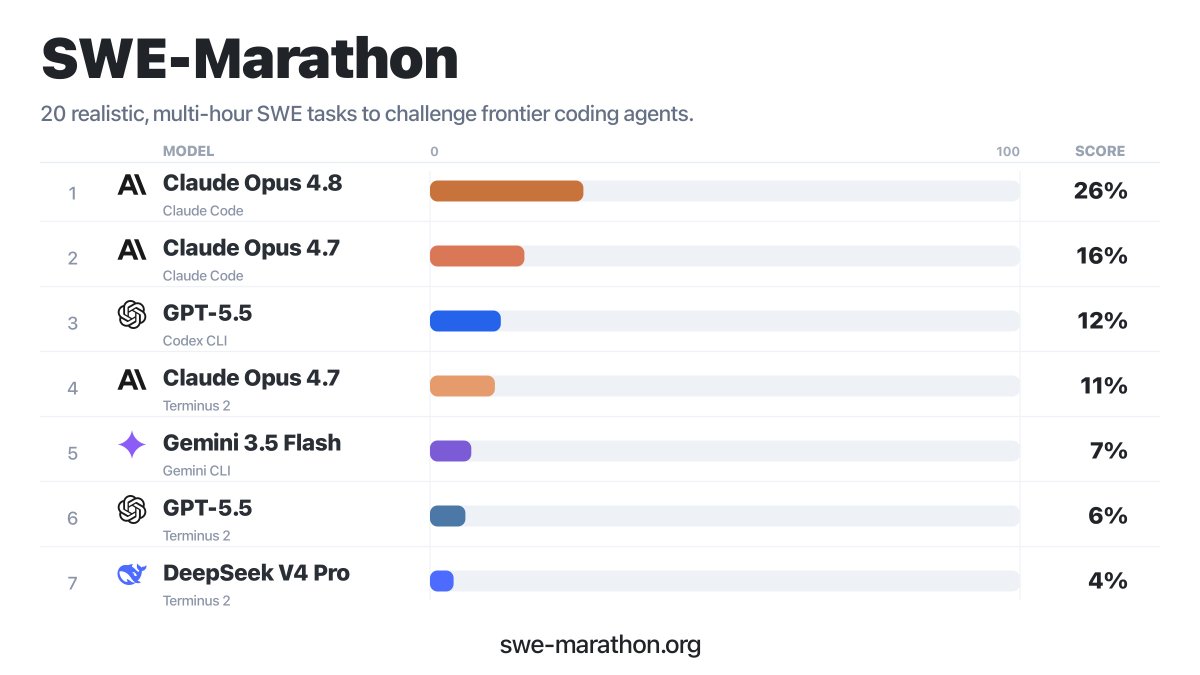
Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
313
279
3,477
638,987
Brand new benchmark by @rishi_desai2 et al. evaluating AI agents on long-horizon SWE tasks. Calling SWE-Marathon a collection of “tasks” is almost an understatement - it’s more a collection of end-to-end projects that human SWE teams would spend days, weeks, or months on.
Jun 5
Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
1
15
2,525
Awesome interview on ProgramBench with @jyangballin and @vincentsunnchen - great stuff guys!

New Benchtalks with @jyangballin: on ProgramBench (0% frontier models at launch) and the lineage/future of coding benchmarks, from SWE-bench/InterCode to now
01:29 ProgramBench launch and reception
03:41 Why artifact-level evaluation, not code-level
06:03 Why models love Python
08:29 ProgramBench as a research tool
12:45 From SWE-bench & InterCode to ProgramBench
17:47 How to grade a coding model
21:53 The position paper & humans in the loop
25:01 Managing quality with agents-in-the-loop
28:40 Internet access and benchmark integrity
35:26 Where models may surpass human abilities
38:56 When a model hits 80% on ProgramBench
43:55 Benchmarks worth paying attention to
46:24 What benchmark do you wish existed
49:32 Will benchmarks still look like benchmarks in 5 years
52:02 How to contribute to ProgramBench
2
2
11
4,153
May 30
Check out Lin’s great talk on how we built a unified infrastructure for agentic benchmarks, and why we need it!
May 29

CAIS AgenticSE Workshop Keynote Talk: Harbor Adapters & Harbor Index
30min video here:
youtu.be/tvAAKX2XVus?si=84L2…
Happy to be invited as a keynote speaker and present our recent study on Harbor Adapters and agentic evaluation!
2
13
1,542
Steven Dillmann retweeted

May 27
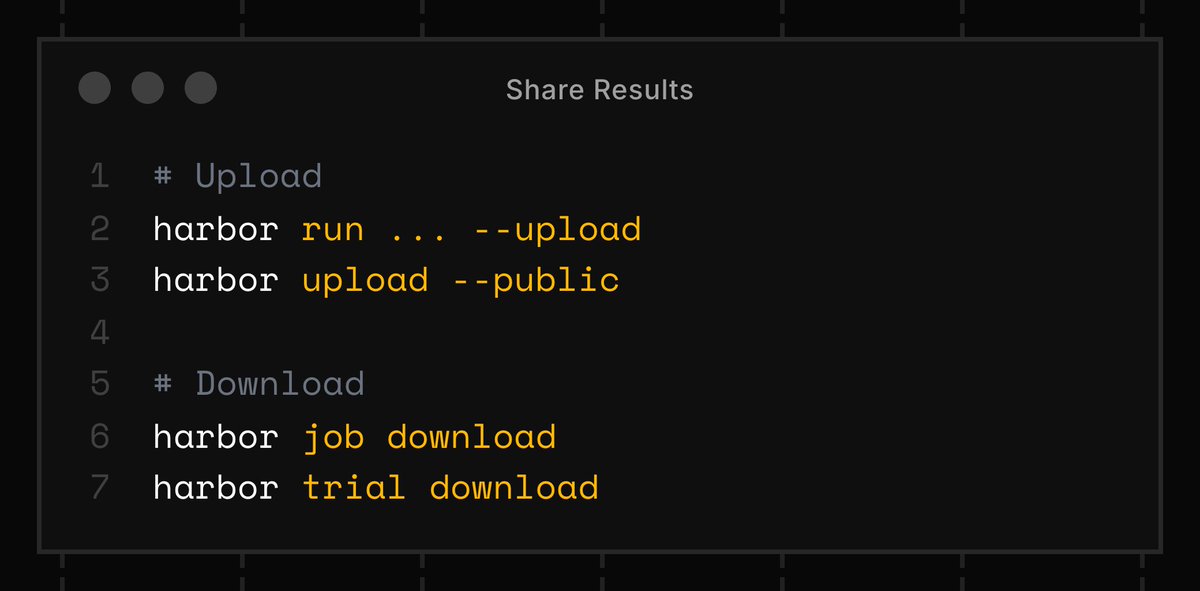
🚨 stop zipping job results 🚨
... upload results to Harbor Hub instead
The hub makes it easy to share results with team members, customers, or simply save for later in a centralized place.
Example of a TB2.1 job in 🧵
1
2
18
4,557
Steven Dillmann retweeted

May 27
Packed room to hear @alexgshaw and @ryanmart3n break down how @harborframework grew into *the* framework for RL environments.
In our RLEval workshop at @CAISconf today, attendees tackled big open challenges in RLEs & Agent Evals I shared the approach we take at @joinHandshake


2
10
33
6,375
Steven Dillmann retweeted

May 26
the harbor community will be @ CAIS - come say hi!
9am Tue @ RLEval workshop
Harbor & Terminal-Bench 3.0 talk by @alexgshaw / me
10:30am Tue @ RLEval workshop
OpenThoughts-Agent talk by @AlexGDimakis
4pm Tue @ Agent Software Engineering workshop
Harbor Adapters & Harbor Index talk by @LinShi592021
9am Wed: Keynote by @andykonwinski
3
6
22
3,140
Steven Dillmann retweeted

What sets @VRubinObs apart?
Over 10 years, Rubin will be mapping the southern sky to create a comprehensive map of the cosmos. It will guide astronomers where to look next, and reveal our universe at scales previously unimaginable.
1
16
32
2,155
Steven Dillmann retweeted

Wish an AI agent could handle your next research task in the list? 👇
May 20

📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
2
4
2,693
May 21
Great article by @TimothyKassis on why we need Terminal-Bench Science - if you’re a scientist and want AI agents to become better in your domain, join us!👇
tbench.ai/news/tb-science-an…

2
11
914
Steven Dillmann retweeted

May 21
"AI for science" benchmarks today mostly test textbook recall. Terminal-Bench Science is a chance for scientists to practice writing that definition. Contribute a real workflow, and you find out exactly where today's best agents break on it.
tbench.ai/news/tb-science-an…
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
6
26
2,906
Steven Dillmann retweeted

May 21
Very timely initiative!!
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
1
5
1,717
Steven Dillmann retweeted

Good evals like this are exactly what we need to accelerate progress in AI for science
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
2
10
1,719
Steven Dillmann retweeted

Wonderful project; wonderful people; please contribute for the sake of science.
Bonus: @StevenDillmann will be interning with me and AutoDiscovery team @allen_ai translating benefits from TB-Science to our science agents!
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
2
22
2,277
Steven Dillmann retweeted

May 21
Consider contributing tasks to Terminal-Bench Science, the most direct way to teach AI agent to solve your AI workflows and accelerate your research.
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
3
8
1,400
Steven Dillmann retweeted

May 21
More please!
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
1
4
314
Steven Dillmann retweeted

May 21
Science is the frontier of AI. Contribute to this initiative if you can!
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
1
9
1,641
Steven Dillmann retweeted

May 21
Terminal-Bench Science is a direct way to contribute to AI for Science. It's programming agents by task specification. Ask a precise scientific question and watch how AI agents will learn to solve it:
Step 1. Package a scientific task or workflow, something that takes a working scientist a week or month to do into an RL environment.
Step 2. Write tests that verify if the task has been done correctly (can be done easily if you have already solved the task manually).
Step 3. Sit back and let AI agent progress solve it in 6 months.
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
9
6
42
5,478
Steven Dillmann retweeted

May 20
Scientists, I highly encourage you to submit hard scientific tasks that you want your agents to do to this Terminal-Bench Science benchmark! Make your task seen and solved by agent/model providers. Get credit from the project.
May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
1
5
657