
Joined May 2022
- Tweets 49
- Following 185
- Followers 38
- Likes 1,893
3 Photos and videos



Scott Hickey retweeted

We brought a bill to hold school districts accountable for the basic literacy of our kids.
It enjoyed the bipartisan support of a supermajority of the Legislature.
And yet, because of the Legislature’s broken filibuster rule—which requires a SUPER-supermajority of senators to end debate—this commonsense bipartisan bill died by filibuster without even a fair up-or-down vote.
The Nebraska Legislature’s antiquated and dysfunctional filibuster rule is failing our kids and failing our state.
May 4

54% of Americans read below a 6th grade level.
nu.edu/blog/49-adult-literac…
36
29
110
8,411
I can't think of anyone I find more obnoxious and self-absorbed than Megan Hunt. "Think like me or I hate you" while calling other people Fascists. Text book rich kid liberal condescending elite. Thank God for term limits. @402meg plains-sentinel.com/p/state-…
16
Scott Hickey retweeted

Apr 13
Breaking: Impeachment Bombshell: Secret memos expose Ukraine accuser’s bias, hearsay, and false claim justthenews.com/accountabili…
41
506
1,462
42,383
Scott Hickey retweeted

Apr 11
Taxing non-income-producing property is wrong. Homeowners should not be forced to work to pay "rent" to the government for the privilege of living in their own homes. Property taxes should only be levied on income-producing property, as the income provides a means to pay the tax.
1,219
3,822
24,990
563,848
Scott Hickey retweeted

Mar 2
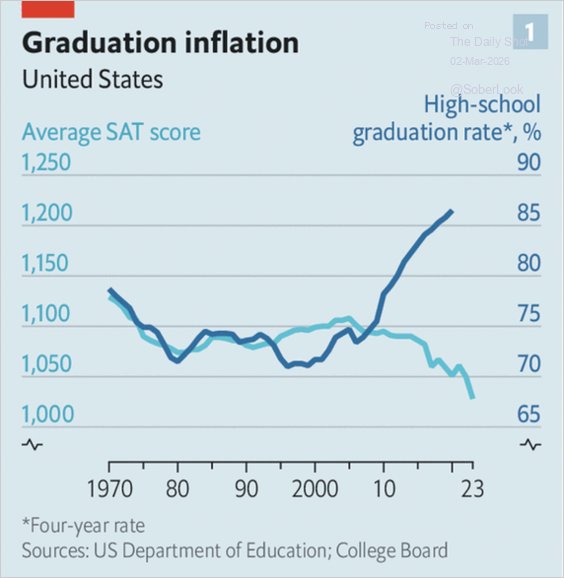
Since 2010, when my #kids were still in school, there was a clear shift in their education and away from teaching critical and independent thinking. (We provided additional education to our kids to circumvent that.)
However, it has shown up in SAT scores.
28
42
158
14,561
Scott Hickey retweeted

A former California health official warns about Covid vaccines.
fullmeasure.news/newest-vide…

7
30
78
5,590
Scott Hickey retweeted

28 Dec 2025
This photograph is one of mankind’s greatest achievements. It is breathtaking.
27 Dec 2025

It took 9 years and 3 billion miles to get this shot.
Pluto’s icy Mountains.
1,011
6,284
71,640
2,214,398
Scott Hickey retweeted

6 Sep 2025
Is it a "bad guess" when AI hallucinates the news about me?
6 Sep 2025

OpenAI realesed new paper.
"Why language models hallucinate"
Simple ans - LLMs hallucinate because training and evaluation reward guessing instead of admitting uncertainty.
The paper puts this on a statistical footing with simple, test-like incentives that reward confident wrong answers over honest “I don’t know” responses.
The fix is to grade differently, give credit for appropriate uncertainty and penalize confident errors more than abstentions, so models stop being optimized for blind guessing.
OpenAI is showing that 52% abstention gives substantially fewer wrong answers than 1% abstention, proving that letting a model admit uncertainty reduces hallucinations even if accuracy looks lower.
Abstention means the model refuses to answer when it is unsure and simply says something like “I don’t know” instead of making up a guess.
Hallucinations drop because most wrong answers come from bad guesses. If the model abstains instead of guessing, it produces fewer false answers.
🧵 Read on 👇


23
15
197
59,041

27 Aug 2025
Congratulations to the @ApacheGroovy team for the 5.0 release - what a great milestone! Having been retired for two years now, looking back on it all - easily the best developer community I ever worked with. Amazingly nice and over-the-top talented!
2
5
309
10 Aug 2025
#omaha EPIC fail by new mayor on only one tiny drop off site for storm damage. One hour wait for me, line was 3x longer as I left
48
Scott Hickey retweeted

5 Dec 2024
Massive congratulations to @chris_mccord and the team for reaching the amazing milestone of LiveView 1.0.
8
69
2,376
26 Nov 2024
Lots of devs moving to Bluesky. Nice article on what a person can expect.
26 Nov 2024

Many have shared their own “I can breathe now” take on Bluesky and how it is great to be again among friends. Just like the old days. In hi way, Bluesky has become the new "safe space" for liberals to avoid being triggered by opposing views. jonathanturley.org/2024/11/2…
50
Scott Hickey retweeted

31 Oct 2024
Six female athletes from the University of Nebraska appear in a pro-life, pro-child, pro-woman ad supporting Initiative 434 in Nebraska.
This is so cool to see. For so long, the other side has used star athletes to promote their views. The tide is turning.
871
12,402
68,032
1,920,288
14 Sep 2024
Thank you Grady!! I have a degree in Philosophy and a career as a software engineer. I reluctant to be critical of this wave of “AI” because no one wants to hear it from an old guy who lived the 80s AI boom & bust People think I just don’t understand, because it’s different now.
1
73
Scott Hickey retweeted

15 Aug 2024
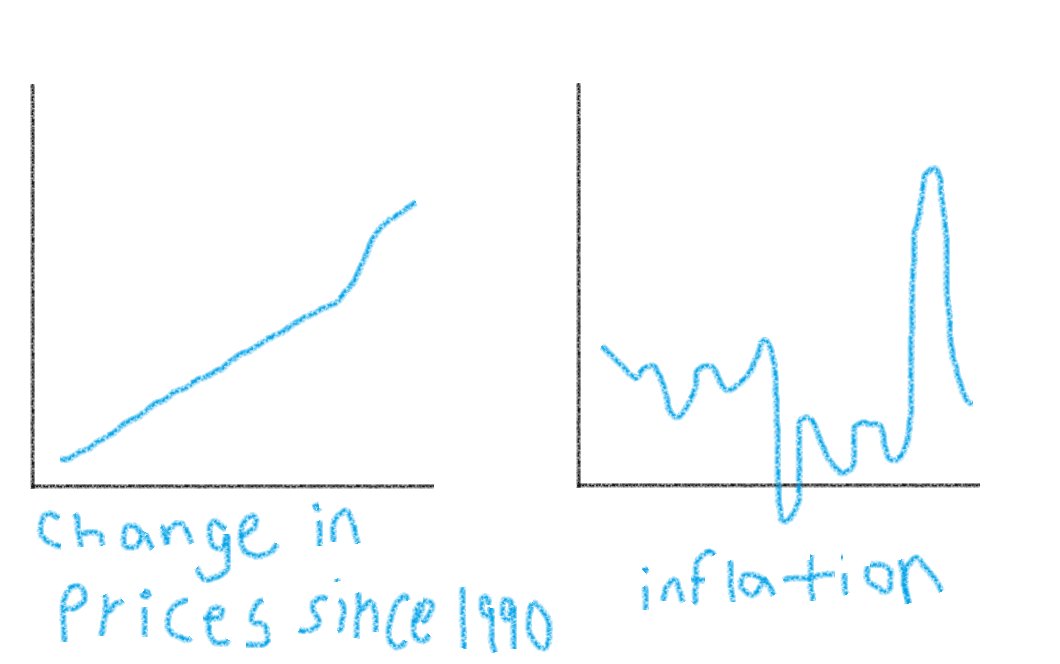
14 Aug 2024

Can someone please explain to me in crayon how “inflation keeps going down,” but we continue to live in the most expensive timeline of our lifetime?
233
1,534
25,995
2,088,745
22 Jul 2024
Sucks having to unfollow tech accounts that are mixing in political opinions with technical announcements. Otherwise smart people can be real idiots. Do devs really believe their political takes are actually persuasive and not annoying??
21
1 Jun 2023
No Omaha Elixir Mixer June event due to the Tech Omaha Summer Party happening during our regular time. Should be great fun! eventbrite.com/e/tech-omaha-…
46
10 May 2023
Looking forward to the next Omaha Elixir Mixir tomorrow night! Journey into the Fediverse meetup.com/omaha-elixir-mixe… #Meetup via @Meetup #myelixirstatus
118
Scott Hickey retweeted

21 Mar 2023
Event reminder: WiTH - Lean UX Agile: Building for Outcomes Over Output Mar 21, 2023 05:15PM google.com/calendar/event?ei…
1
66