
I build sane open-source RL tools. MIT PhD, creator of Neural MMO and founder of PufferAI. DM for business: non-LLM sim engineering, RL R&D, infra & support.
Joined March 2019
- Tweets 9,529
- Following 123
- Followers 30,338
- Likes 8,226
767 Photos and videos








Pinned Tweet

Apr 6
Releasing PufferLib 4.0: Train agents in seconds
40
99
1,185
201,007
Joseph Suarez 🐡 retweeted

Jun 12
PufferLib env I made, a bat chasing a bug. Sound on. It sends out chirps and it's only observations are FFT for each ear catching reflections, the last chirp it made, and a timer.
it senses the doppler shift in the bug on its own. PufferLib one shot this.
5
11
120
11,035
Jun 12
If the timeline is full of new RL people training N pendulums, where are all the PRs?
11
2
144
9,753
Joseph Suarez 🐡 retweeted

Jun 11
We are super excited to share with you our initial release of Lucky Engine. We are building a robotics engine from the ground up to be what we wished we could find in a simulator before
27
111
790
8,499,247
Joseph Suarez 🐡 retweeted

Jun 10
we worked with joseph and the puffer crew, they're the best, everyone should do RL with them
Jun 10

PufferLib is open source, but Puffer the company builds high-perf RL sims professionally. We've solve problems clients thought impossible in seconds on a single GPU! Contact me at jsuarez🐡puffer🐡ai.
2
3
64
13,413
Joseph Suarez 🐡 retweeted

Jun 10
pretty decent 5 pendulum run, i will have 7 solved soon
32
8
635
68,419
Jun 10
Reinforcement learning research with Joseph Suarez x.com/i/broadcasts/1lJQRRzMR…
1
1
27
2,008
Jun 10
PufferLib is open source, but Puffer the company builds high-perf RL sims professionally. We've solve problems clients thought impossible in seconds on a single GPU! Contact me at jsuarez🐡puffer🐡ai.
11
165
18,433
Jun 10
This sadly isn't going to work. The best response is for all AI researchers to stop using Anthropic models. The lack of public feedback alone would cause them to fall behind within months.
Jun 9

June 9th Researcher Reciprocity License
"if you train on it, you let us generate - reverse terms of use void"
Status quo
1. We teach frontier devs with ICLR/NeurIPS papers, OSS Github contributions
2. They use it to make frontier models
3. Then ban us from exploring our ideas
We need a new license, original thinkers can't be an underclass to a tyrannical researcher fiefdom
9
18
365
19,145
Jun 10
Hello @kellerjordan0 @_arohan_. I noticed that in your recent optimizer work, you appear to have used the inefficient versions of Muon and Shampoo that have long since been succeeded by PowerWash last week. The new algorithm is quite simple and elegant: it merely generates a set of weights with a different seed and evaluates until one of them passes the validation threshold, therefore cutting speedrun time down to 0 steps. The SplittingHairs normalization addition is particularly useful for stabilizing performance. I hope we can collaborate to bring this new standard into broader usage!
9
10
369
32,984
Jun 10
Now that I have your attention, any suggestions on our ~200 line CUDA implementation of Muon would be greatly appreciated github.com/PufferAI/PufferLi…. In the 5.0 branch on the same file, I played with a small change to preserve LR across model sizes, but there have not been any major improvements otherwise.
3
1
57
4,852
Jun 10
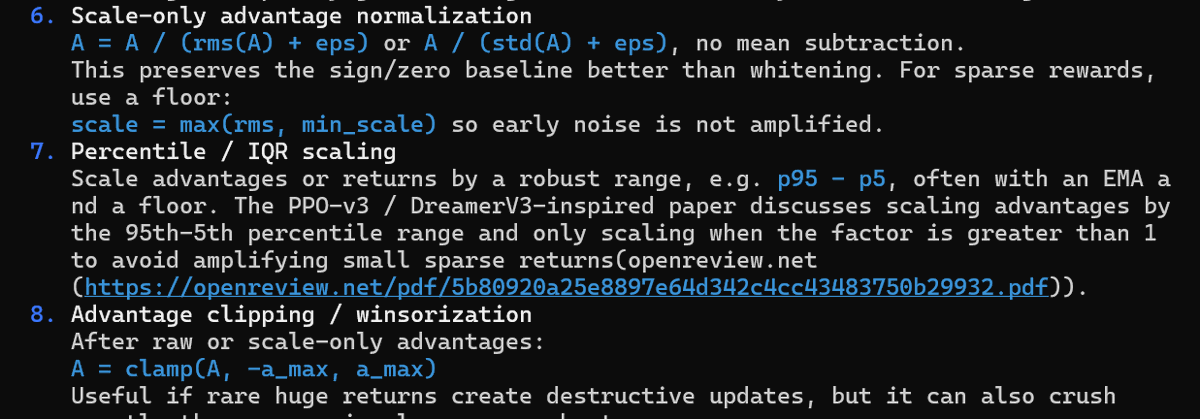
Ended stream early yesterday to rethink the new RL algo. There's a key limitation of advantage that makes it hard to use for selecting informative states to revisit. I came up with something much simpler, will try it on stream in a few hours!
3
1
95
6,550
Jun 9
New to RL PufferLib? Star to support! Next update is focused on core algo improvements.
7
4
142
52,907
Joseph Suarez 🐡 retweeted

We introduce a method for training RNNs that is time-parallel and does not suffer from vanishing/exploding gradients.
Key idea is to decouple learning 1) what should be remembered (can be done without recurrence) and 2) how to update memory (can be one-step supervised by #1).
Jun 7

We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t 1}) → m_{t 1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: akarshkumar.com/smt/
arXiv: arxiv.org/abs/2606.06479

2
22
226
28,908
Jun 9
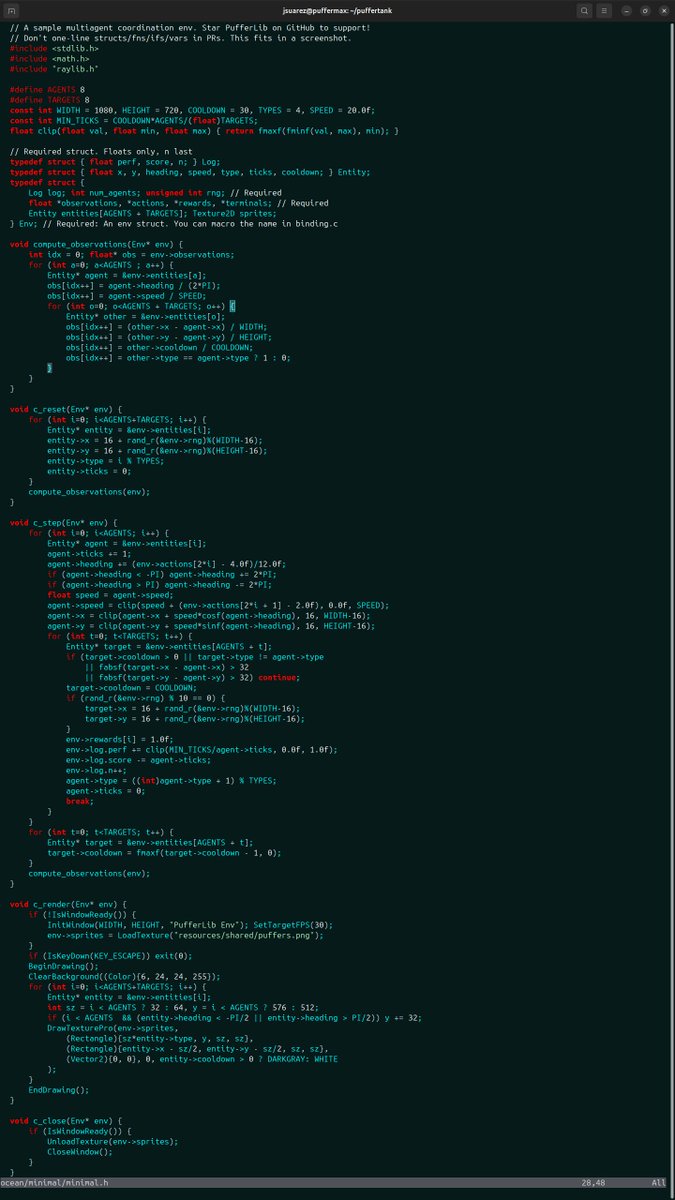
Want to solve cool problems with RL? Take an afternoon to read our docs (1 page) on puffer.ai and build a ~300 line env. It's C but it's really easy C. Extensive guides on my articles tab for learning more from there! All free OSS, and I review PRs on stream!
Jun 9

behold. THE WORLDS FIRST SIX PENDULUM CARTPOLE SOLVE. Including a sponsor!
To solve this task, I built an environment to train an AI. This is what mechanize does, but for larger AIs. Apply! Salaries are up on their page
Thank you to mechanize for sponsoring!
9
25
472
28,345
Jun 9
You can train drones in 30 seconds. This was a year ago. PufferLib is 5x faster now!

idk you can train drones to fly on a 3090 in a couple of hours, this is a 3x64 nn
17
119
1,702
159,558
Jun 9
Trained with PufferLib! One GPU is all you need when training runs 10-20m steps/second
Jun 9
behold. THE WORLDS FIRST SIX PENDULUM CARTPOLE SOLVE. Including a sponsor!
To solve this task, I built an environment to train an AI. This is what mechanize does, but for larger AIs. Apply! Salaries are up on their page
Thank you to mechanize for sponsoring!
8
7
315
19,642
Jun 8
Your company here! Ditch your terrible bloated render stack and just use Raylib. Easy local demos UIs, and more web via WASM. All the demos on puffer.ai use it.

#raylib keeps growing (new version, new features, new tools, new users...), but sponsorship does not, growth has been 0 for the last 6 months.
If you use raylib, what would make you consider supporting the project? 🤔
3
3
144
10,351