
FullStack Developer, passionate about technology, startups, and building products
Joined March 2019
- Tweets 106
- Following 253
- Followers 47
- Likes 133
6 Photos and videos


Juan David Gómez retweeted
React Native on iOS doesn't support ReadableStream. When users switch apps mid-response, the AI keeps generating to nothing. This dev solved it by making the server keep going after disconnect and persist the full response to the DB.
{ author: @juandastic }
dev.to/juandastic/i-built-a-…
1
4
6
1,635

May 4
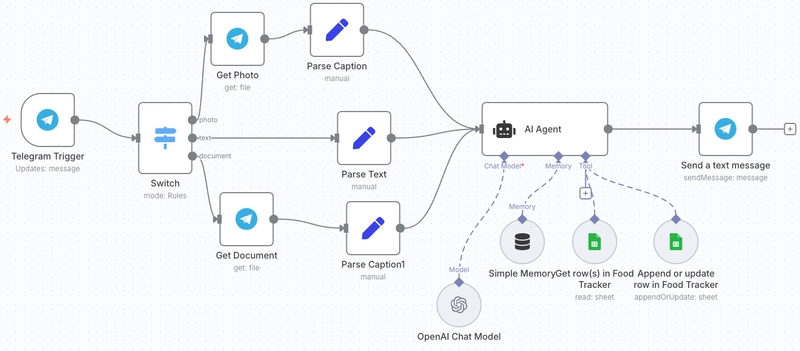
12 years building web apps. Zero mobile experience. Last month I needed an iOS app for my side project so I just built one. Took 3 days.
The real unlock was not React Native or Expo. It was having AI in the workflow. It did not write the app for me but it removed the friction of learning a new platform. I moved at the same speed I move on the web.
Then iOS broke everything. Turns out when your user switches to WhatsApp mid-response, iOS kills your network request. The AI keeps generating server-side, burning tokens, but the response never arrives.
Had to rethink the whole streaming architecture to handle disconnects gracefully.
Full writeup: dev.to/juandastic/i-built-a-…
1
1
86
Apr 19
Building AI side projects is fun until you have to pay for it
I built Synapse, an AI companion for my wife with a memory system that makes Gemini know her life, her patterns, her emotional triggers. She uses it daily.
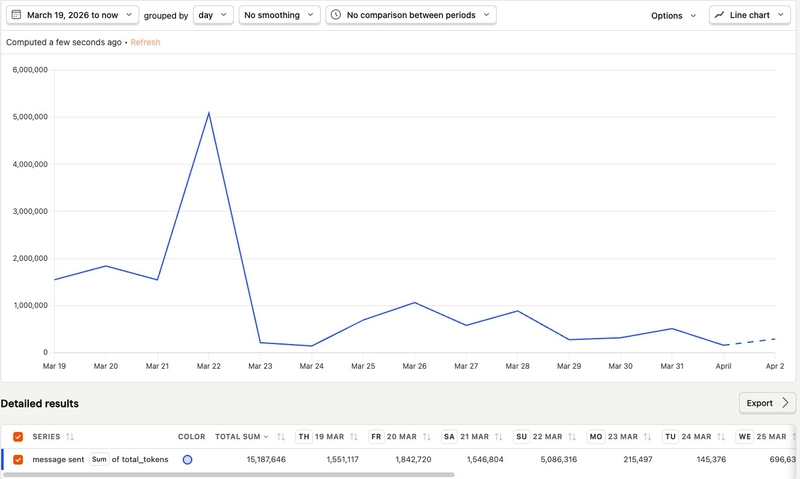
Two weeks ago, I connected PostHog to track costs. $24. One session alone: 28 messages, $2.42.
Every message sends ~30K tokens of context. 80-90% of those tokens are the exact same compiled knowledge, repeated every turn.
Most AI providers offer automatic caching. Send the same prefix enough times, and they might cache it for you. But you have no control. One small change in the prompt (like a datetime updating every turn) breaks prefix matching. You never know if it is working.
𝗚𝗲𝗺𝗶𝗻𝗶'𝘀 𝗲𝘅𝗽𝗹𝗶𝗰𝗶𝘁 𝗰𝗮𝗰𝗵𝗶𝗻𝗴 𝗔𝗣𝗜 𝗶𝘀 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁.
You create a cache resource, get a name back, and reference it on every request. Guaranteed hit. 75% cheaper on cached tokens. You decide what gets cached and you can verify it is working.
I separated the stable knowledge compilation (~25K tokens) from the volatile parts of the prompt, cached the compilation after hydration, and referenced it by name on every message.
The client sends both the cache_name and the full compilation on every request. If the cache is hot: 75% savings. If it expired, the server inlines the compilation at full price. The user never notices.
𝗧𝗵𝗲 𝗻𝘂𝗺𝗯𝗲𝗿𝘀
Before: $0.017-0.039 per generation After: $0.0088 per generation
That $2.42 session? Would cost ~$0.25 now.
Same knowledge graph. Same memory quality. Just a lot cheaper to remember.
Full breakdown: dev.to/juandastic/my-ai-send…
1
68
Apr 3
My wife is a psychologist. She started using an AI between therapy sessions but got frustrated that it forgot everything.
So I built her one that doesn't.
297 messages in 15 days. Here's what I learned 🧵
1
1
58
Apr 3
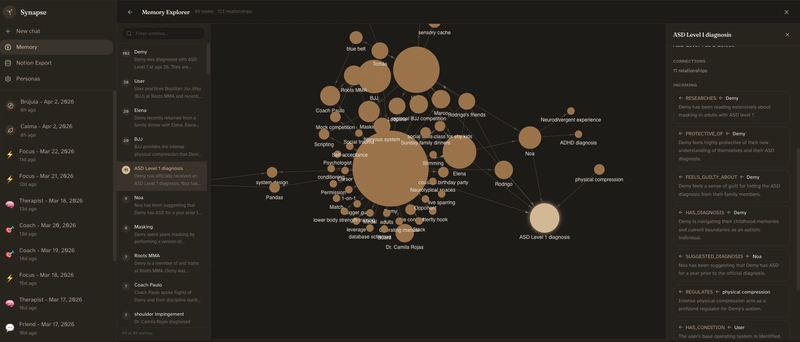
Synapse uses a knowledge graph instead of a flat memory list.
With the right therapeutic frameworks (ACT, DBT, Polyvagal Theory) and all her context, she found her ideal AI personal companion
synapse-chat.juandago.dev
2
78
Apr 3
In the last 15 days of real production data:
→ 297 messages → 15.2M tokens processed → 100% daily active usage → Peak: 69 messages in one day
It's fully open source. The full product story:
dev.to/juandastic/my-wife-se…
35
Mar 22
You can't ask "find the most connected entity and give me all its facts" if the facts live in a different store than the structure.
I'm calling this "context blindness" and for a personal companion it matters more than retrieval scores.
1
27
Mar 22
Full benchmark with architecture diagrams, code, and results (open source):
dev.to/juandastic/i-benchmar…
34
Mar 17
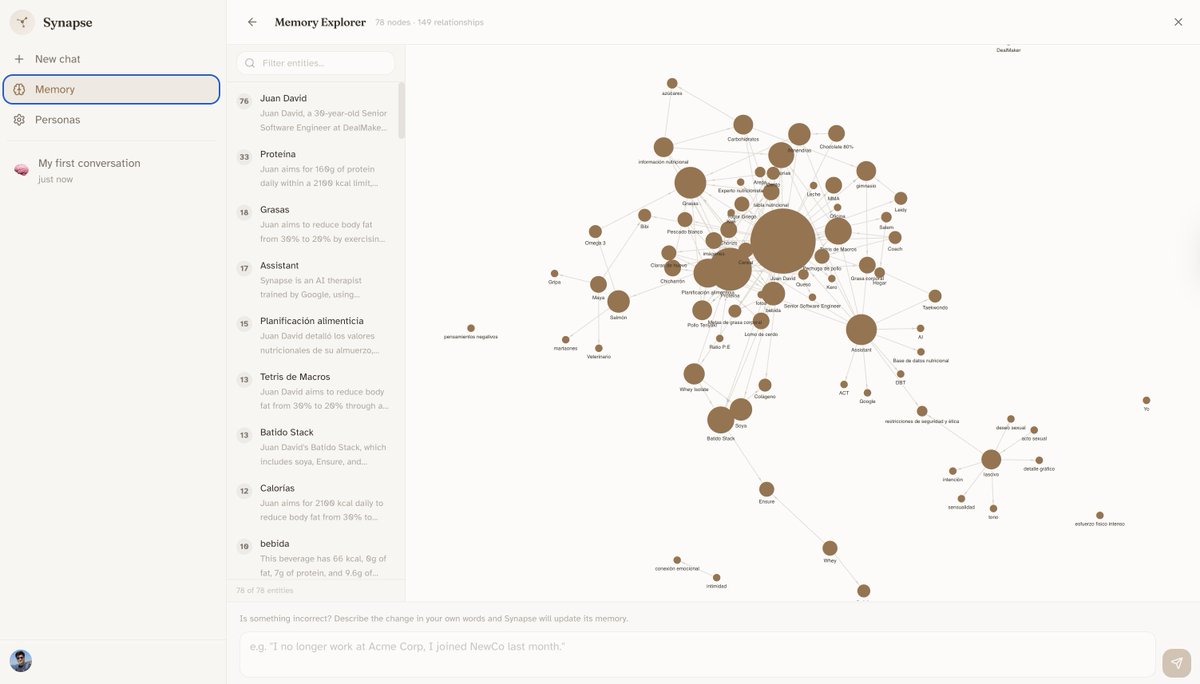
I built a bidirectional sync between a Neo4j Knowledge Graph and Notion for the @ThePracticalDev Challenge with @NotionHQ
AI memory is usually a black box. Now, it's a fully editable, dynamically generated Notion workspace.
Here is the architecture
dev.to/juandastic/full-circl…
66
Juan David Gómez retweeted
Context windows are expensive resources.
This dev demonstrates how to tame a 120k token prompt by implementing a deterministic GraphRAG approach for more efficient memory scaling.
{ author: @juandastic }
dev.to/juandastic/scaling-ai…
1
2
6
2,126
Mar 1
1 Million token context windows are a luxury, not an architecture.
My AI side-project hit a wall when the system prompt bloated to 120,000 tokens per message.
Here is how I fixed it using a Knowledge Graph, a "Waterfill" budget, and Agentless GraphRAG. 🧵👇
1
1
31
Mar 1
To get those details back, I built Deterministic GraphRAG.
I hate Agent tool-calling (adds 3-5s latency). Instead, a straight-line Hybrid Search runs in <1s. It checks what's already in the prompt and only injects missing facts. Zero redundancy.
1
29
Mar 1
The Result: Token usage collapsed back to my 40k limit. Latency stayed under 1s. The AI still feels like it knows everything.
I wrote a full deep dive on @ThePracticalDev with the architecture
dev.to/juandastic/scaling-ai…
1
35
Juan David Gómez retweeted

Feb 18
Congrats to our top 7 authors this week! 🏆
@dannwaneri, @madsstoumann, Julien Avezou, Peter Mulligan, Prithwish Nath, Vivek V, and @juandastic.
This week's lineup features a CSS recreation of a Pantone color deck, a self-hosted Google Trends alternative using DuckDB, and much more.
dev.to/devteam/top-7-feature…
2
5
1,140
Feb 15
Hey @bennettschwartz, I just saw your project on a @theo stream. I am also interested in the same problem. I experimented with Graphs, aiming to solve the same deep memory problem. I posted something about it in case you are interested. I will definitely go check Membrane to know more

I’ve been working on Membrane, a selective learning and memory substrate for long lived agents. The focus is on revisable knowledge, competence learning, and trust aware retrieval instead of append only memory.
I think this kind of layer could fit naturally with agent systems like OpenClaw that are aiming for longer lived architectures.
github.com/GustyCube/membran…
@steipete
24
Juan David Gómez retweeted
Feb 10
Vectors are great for search, but graphs capture relationships.
Building an AI companion with "Deep Memory" that uses Knowledge Graphs (plus vectors) so the system can recall structured personal context and causality, not just match keywords.
{ author: @juandastic }
dev.to/juandastic/beyond-rag…
2
1
7
1,497