
Joined July 2022
- Tweets 210
- Following 543
- Followers 2,733
- Likes 2,675
39 Photos and videos










Pinned Tweet

Mar 9
𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
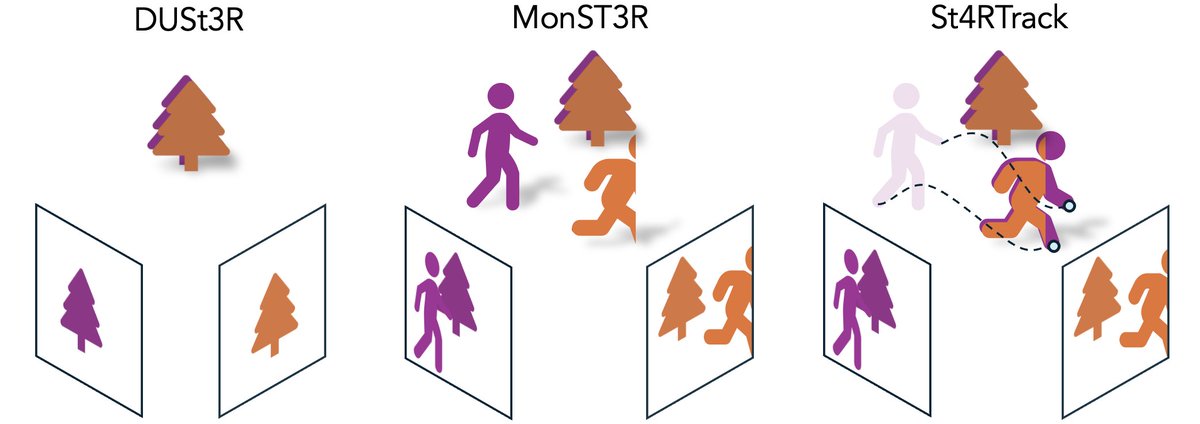
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
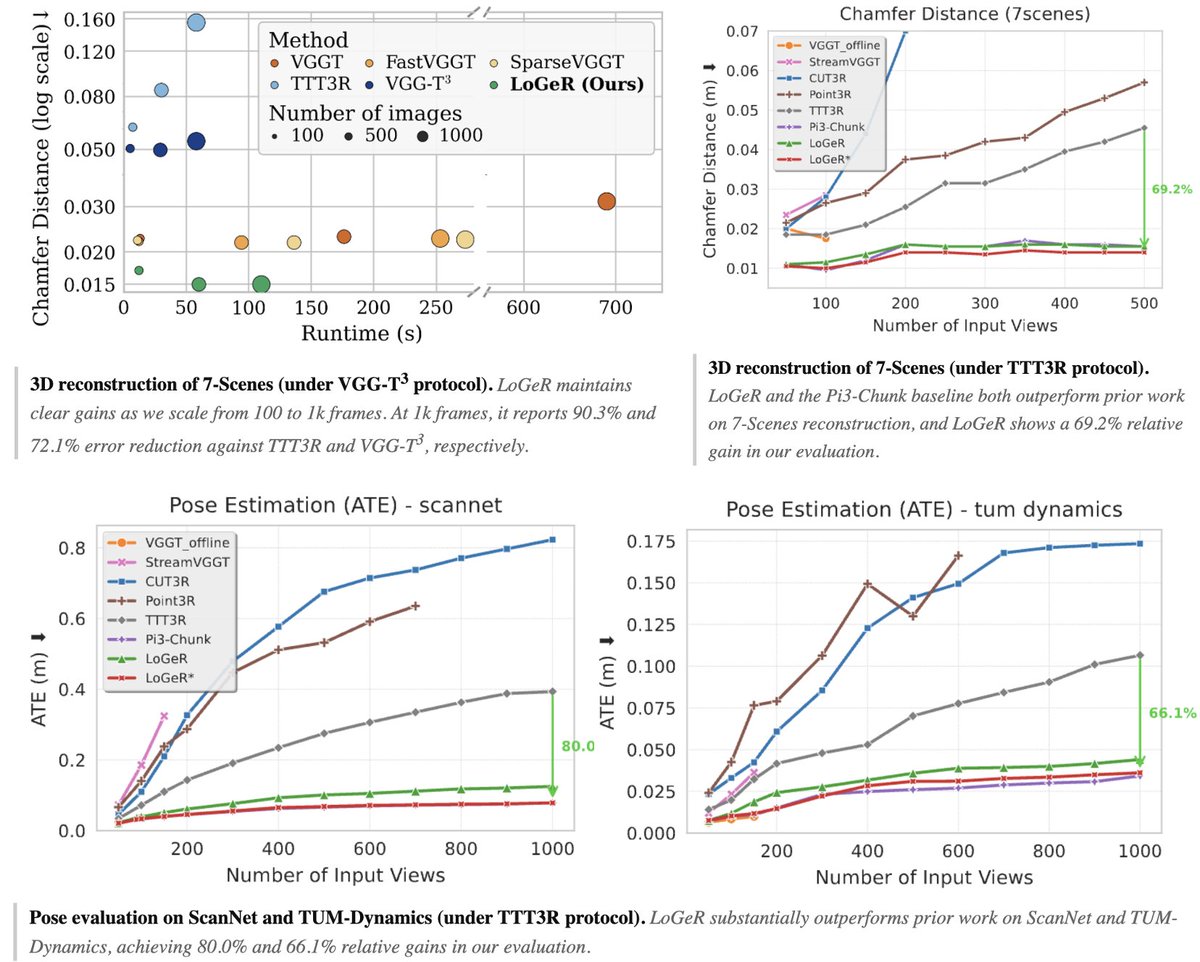
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind @Berkeley_AI
64
446
3,399
560,327
Junyi Zhang retweeted

May 14
New paper: AsymFlow🔥
JiT x0-prediction is not enough for pixel generation. Better keep velocity in a low-rank subspace:
- 1.57 FID on ImageNet (best pixel flow model)
- Finetunes FLUX.2 klein into pixel space, beats the original on HPSv3/DPG/GenEval (#1 overall on HPSv3)
1/7

20
55
282
54,298
Junyi Zhang retweeted
👀Humans compare images by looking back and forth. Many open-weight VLMs encode each image independently, and defer comparison to the LM.
We introduce SVE: Stateful Visual Encoders for Vision-Language Models, where the visual encoder itself becomes change-aware.
🌐Project: statefulvisualencoders.githu…
📰Paper: arxiv.org/abs/2606.04433
💻Code: github.com/StatefulVisualEnc…
1/n
4
38
248
50,809
Jun 3
Just arrived at Denver for CVPR!
I will be presenting LoGeR at e2e3d.github.io/poster.html 5pm today and 4dvisionworkshop.github.io 4:30pm tomorrow (oral talk). Stop by if you are interested!
1
3
42
2,329
May 30
Pose is so essential for grounding humans in the 3D world -- and the same applies for MLLMs.
Happy to share Cambrian-P, a year-long collaboration with NYU/FAIR. We introduced a simple pose token to MLLMs, and it just works!
May 26

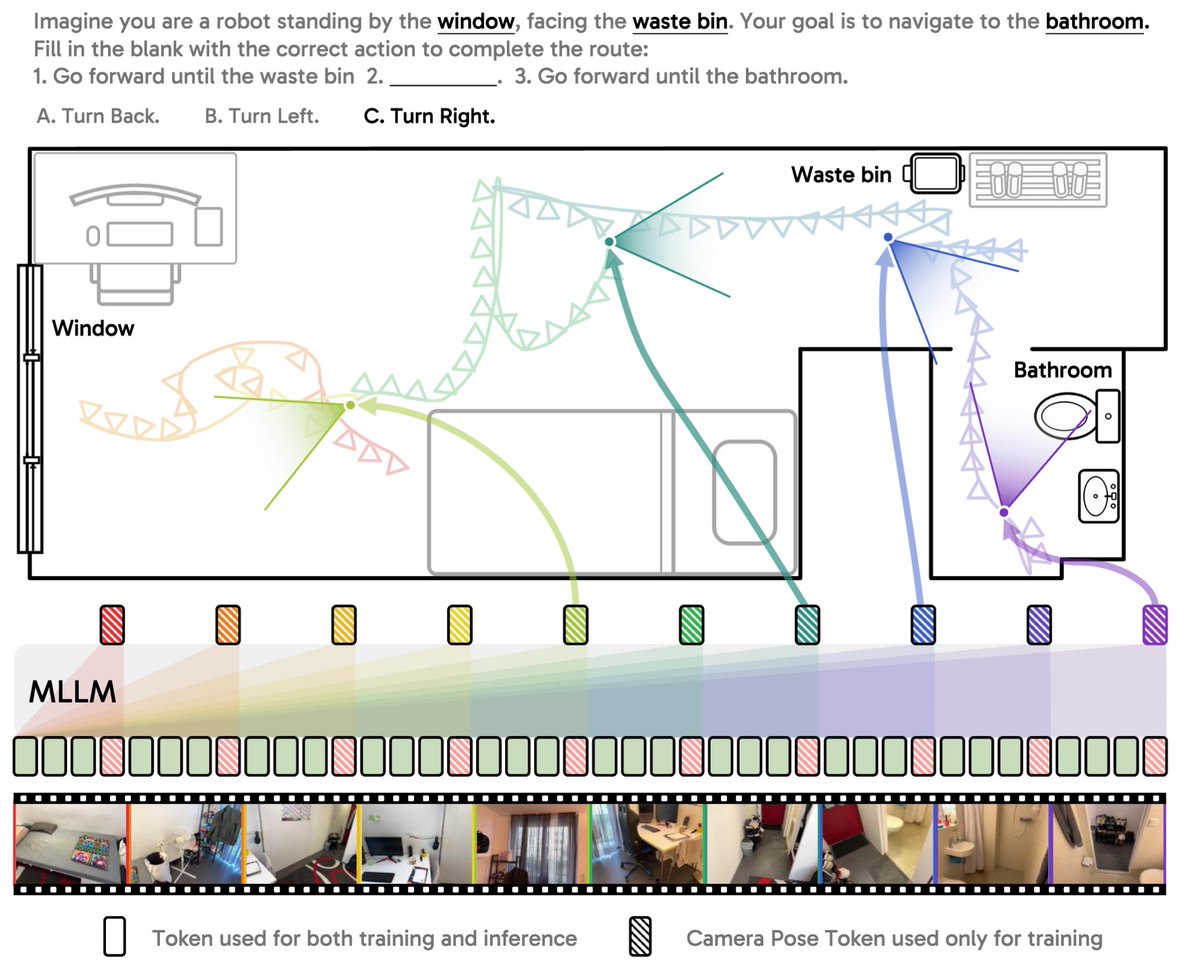
Camera pose matters for video understanding!
Today's MLLMs excel at recognizing activities, but still struggle with the underlying space and ego/object dynamics in video. We trace this gap to a missing piece: camera pose.
Introducing Cambrian-P: a multimodal LLM natively grounded in camera pose. (1/n)
7
55
6,306
Junyi Zhang retweeted

May 19
Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
14
142
851
776,952
Junyi Zhang retweeted

May 1
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.

56
157
954
229,251
Junyi Zhang retweeted

Apr 26
🏆 Our VisGym just got the ✨best paper award✨ at the multimodal intelligence workshop in ICLR :)

4
7
66
4,543
Apr 14
Context distillation for geometric models, very cool idea
Apr 14

4D vision is particularly challenging for 3D foundation models due to the scarcity of 4D data.
In SelfEvo, we ask: can a model learn purely from itself? It works remarkably well, even in scenarios where annotations are nearly impossible to obtain.
3
21
4,149
Junyi Zhang retweeted

Apr 9
Our paper was selected as an oral presentation in #CVPR2026
Feb 22

We present the SOTA feed-forward 3DGS pipeline Selfi, which was accepted by #CVPR2026
Project Page: denghilbert.github.io/selfi

5
14
139
10,330
Junyi Zhang retweeted

Apr 2
What’s the right representation for a world model? 3D, pixels, or something else?
Excited to release our new paper “Forecasting Motion in the Wild” where we propose point tracks as tokens for generating complex non-rigid motion and behavior
From @GoogleDeepmind @Berkeley_AI @TTIC_Connect
7
74
470
80,682
Junyi Zhang retweeted

Apr 1
Robotics: coding agents’ next frontier.
So how good are they?
We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability.
From @NVIDIA @Berkeley_AI @CMU_Robotics @StanfordAILab
capgym.github.io
🧵
20
126
632
168,788
Junyi Zhang retweeted

Mar 24
Humans can see in high-res, high-FPS in real-time. Why can't VLMs?
Introducing AutoGaze: ViTs/VLMs "gaze" only at key video regions! Up to 4-100x token savings, 19x speedup, and enables scaling to 4K-res 1K-frame videos.
📄 arxiv.org/abs/2603.12254
🌐 autogaze.github.io
🤗 huggingface.co/collections/b…
(1/n)🧵
47
203
1,577
158,575
Junyi Zhang retweeted

Mar 16
𝗞-𝗺𝗲𝗮𝗻𝘀 𝗶𝘀 𝘀𝗶𝗺𝗽𝗹𝗲. 𝗠𝗮𝗸𝗶𝗻𝗴 𝗶𝘁 𝗳𝗮𝘀𝘁 𝗼𝗻 𝗚𝗣𝗨𝘀 𝗶𝘀𝗻’𝘁.
That’s why we built Flash-KMeans — an IO-aware implementation of exact k-means that rethinks the algorithm around modern GPU bottlenecks.
By attacking the memory bottlenecks directly, Flash-KMeans achieves 30x speedup over cuML and 200x speedup over FAISS — with the same exact algorithm, just engineered for today’s hardware. At the million-scale, Flash-KMeans can complete a k-means iteration in milliseconds.
A classic algorithm — redesigned for modern GPUs.
Paper: arxiv.org/abs/2603.09229
Code: github.com/svg-project/flash…
36
200
1,747
307,355
Junyi Zhang retweeted

We're very excited to present a new hybrid memory version of feed-forward geometric reconstruction!
The core intuition is that our architectures should be designed with type of training data we have available in mind.
The result is very long (kilometer-scale) reconstruction!!
Mar 9

𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind @Berkeley_AI
1
4
109
16,331
Mar 9
𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind @Berkeley_AI
64
446
3,399
560,327
Mar 9
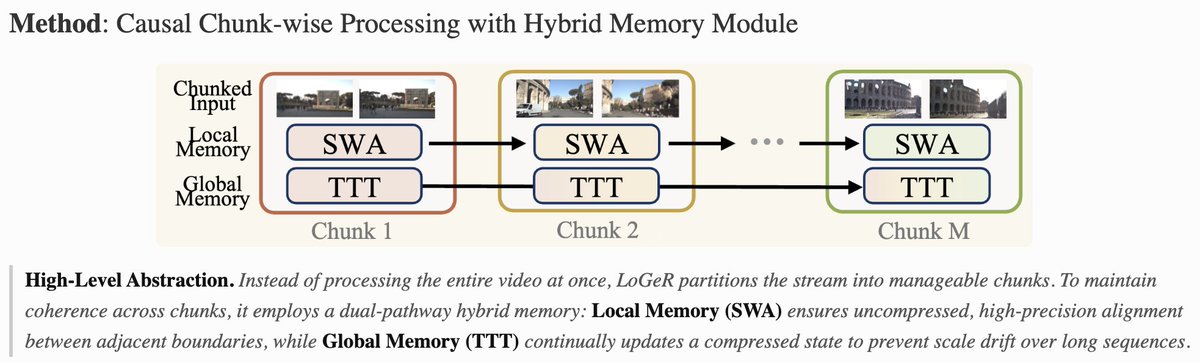
LoGeR breaks both walls with 𝗰𝗵𝘂𝗻𝗸-𝘄𝗶𝘀𝗲 𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆:
🔹 Local Memory (SWA): non-parametric, lossless sliding-window attention preserves high-fidelity adjacent alignment.
🔹 Global Memory (TTT): compressed fast weights propagate long-range structure and stabilize scale over kilometer-scale trajectories.
1
54
11,044
Mar 9
Check out the project page for more details!
🌐 Webpage: loger-project.github.io/
📄 Paper: arxiv.org/abs/2603.03269
Yet another wonderful collaboration with this amazing team: @CharlesHerrman8* @JunhwaHur* @jesu9 @MingHsuanYang @forrestercole2 @trevordarrell @DeqingSun
4
8
131
10,876