Founder of Data School
- Tweets 4,314
- Following 196
- Followers 22,066
- Likes 3,250














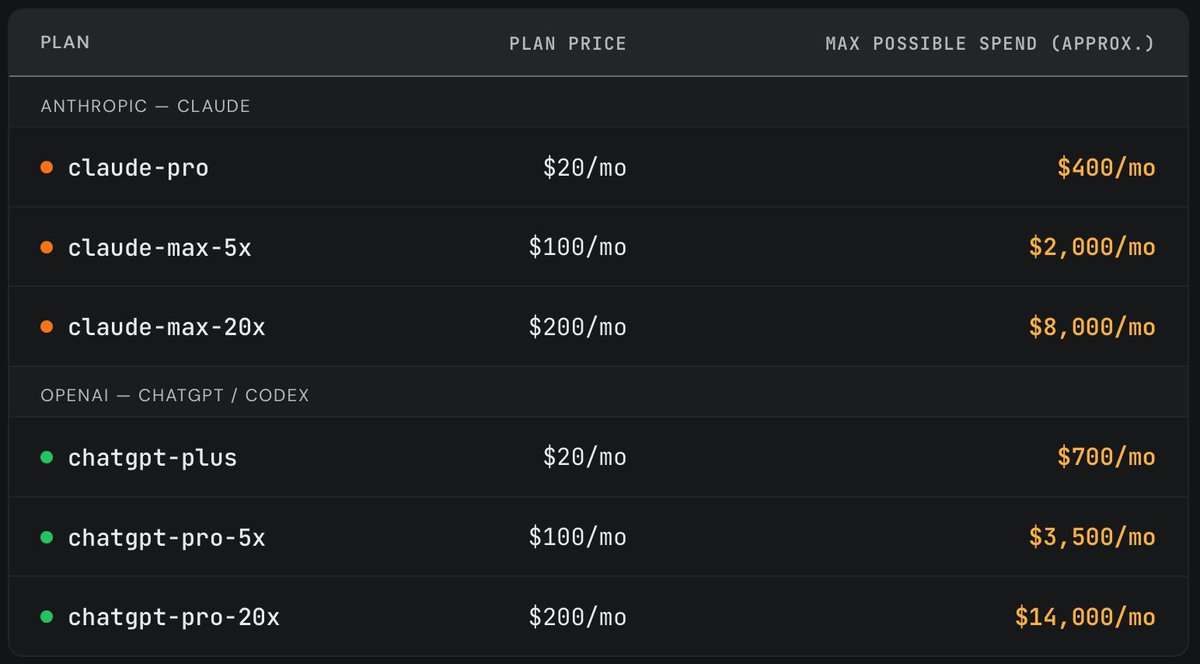





ALT The year of “reasoning” The year of agents The year of coding agents and Claude Code The year of LLMs on the command-line The year of YOLO and the Normalization of Deviance The year of $200/month subscriptions The year of top-ranked Chinese open weight models The year of long tasks The year of prompt-driven image editing The year models won gold in academic competitions The year that Llama lost its way The year that OpenAI lost their lead The year of Gemini The year of pelicans riding bicycles The year I built 110 tools The year of the snitch! The year of vibe coding The (only?) year of MCP The year of alarmingly AI-enabled browsers The year of the lethal trifecta The year of programming on my phone The year of conformance suites The year local models got good, but cloud models got even better The year of slop The year that data centers got extremely unpopular My own words of the year