
27 Photos and videos









Pinned Tweet

19 Aug 2025
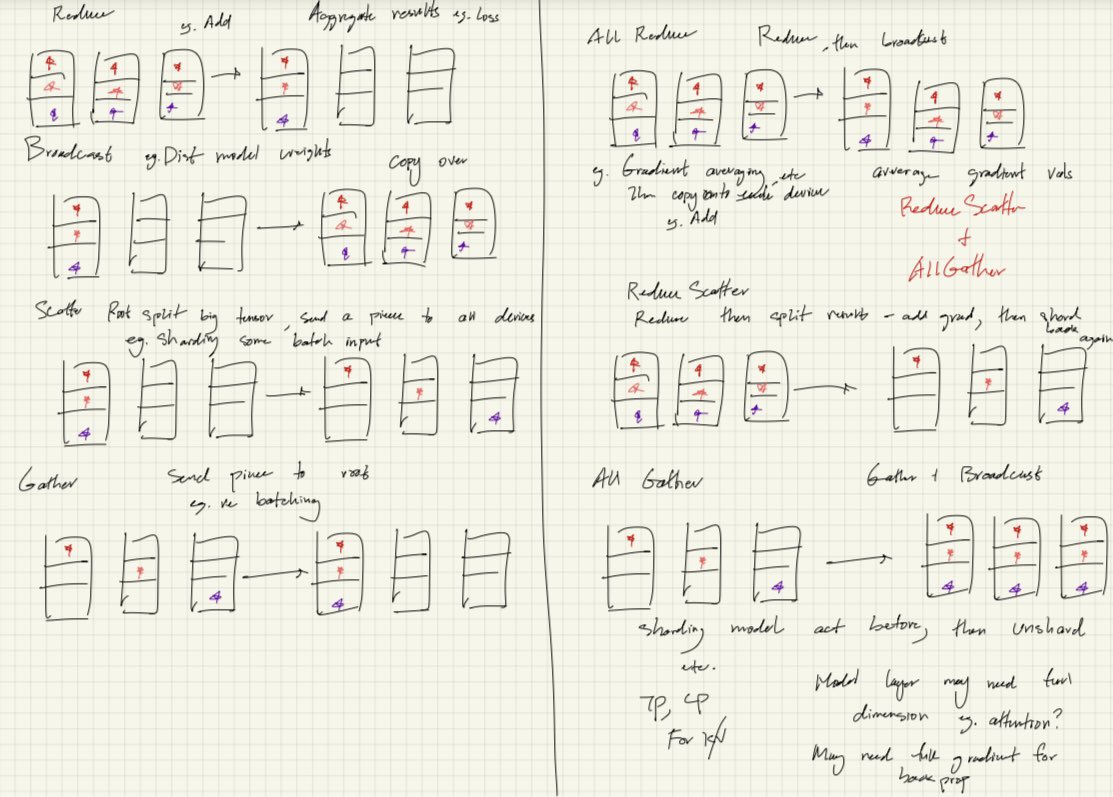
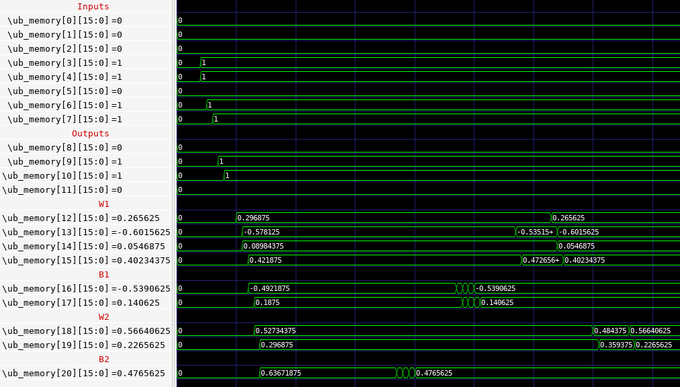
introducing tiny-tpu, a tiny TPU, supporting both training and inference, ENTIRELY on chip!
here is an overview of how I got started and how this was built:
4
11
94
9,970
Kenny Guo retweeted

Jun 5
I just spent months handwriting a 200 page guide on the entirety of ML foundations and math from scratch.
The guide features:
- Neural Nets (Backprop, Adam, SGD, Batch Norm)
- ML Algorithms (SVM, Grad Boosting, K-means, PCA)
- Hardware (Tensor Cores, Systolic Arrays, CUDA)
- Transformers (Multi-Head Attn, KV Cache, LoRA)
- Vision (ViT, Convolutions, MAE, IoU, NMS, VLM)
- Agents (OpenClaw, ReAct, Memory, Orchestration)
Everything I wish I had years ago, for free.
143
338
2,827
277,592
Kenny Guo retweeted

Jun 5
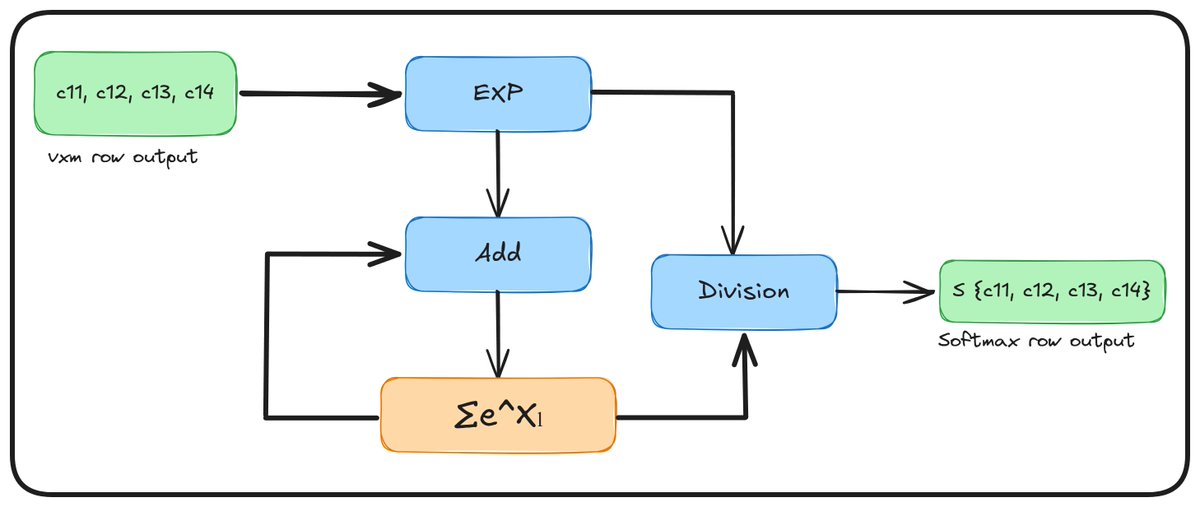
@sakshambatraa and I have now implemented Softmax on our toy LPU!
after overhauling the VXM pipeline, we set our sights on implementing the Softmax module in hardware 🧵
5
7
22
1,291
Kenny Guo retweeted
Jun 1
another progress update on reinventing Groq's LPU with @sakshambatraa:
we redesigned out vector execution module (VXM) to better support overlap on operations, and introduce compatibility to run self attention!
7
8
18
2,862
Kenny Guo retweeted

May 31
We brought Meraki to @TOtechweek and the demoers killed it. Toronto is a city full of people making incredible things 🫶
Special shoutout to @jai_mansukhanii & @generalmagic_ai, @PanacheVC, @cyborgowski for making this possible!




7
6
28
1,933
Kenny Guo retweeted

May 30
We presented Talos at the @merakiatuoft Toronto Tech Week showcase last night.
Special thanks to the hosts (@krupaad,@_smitsp11, @_richapandya,@kennykgguo, @achettimada, @ambiguousNull) for putting this event together 😊

10
6
36
3,022

Kenny Guo retweeted

May 18
@sentra_app just killed @GoogleResearch's TurboQuant.
Introducing SpectralQuant — 5.95× KV cache compression on Mistral 7B at 7.5% perplexity overhead.
TurboQuant at the same compression: 22%.
3× less degradation. 15-second calibration. One per-model, then drop-in for any HuggingFace LLM, ViT, ESM, AlphaFold Evoformer, or VideoMAE.
📰 Paper & results: github.com/Dynamis-Labs/spec…
Check out the findings and how the mechanism works below. ↓
21
25
111
16,407
Kenny Guo retweeted

May 8
A few months ago, I saw Karpathy build NanoChat in PyTorch, and it made me want to understand how these models work underneath the abstractions.
So I decided to try building one myself, but in a different framework: JAX.
Here’s how I did it: 🧵


5
7
25
1,709
Kenny Guo retweeted
May 7
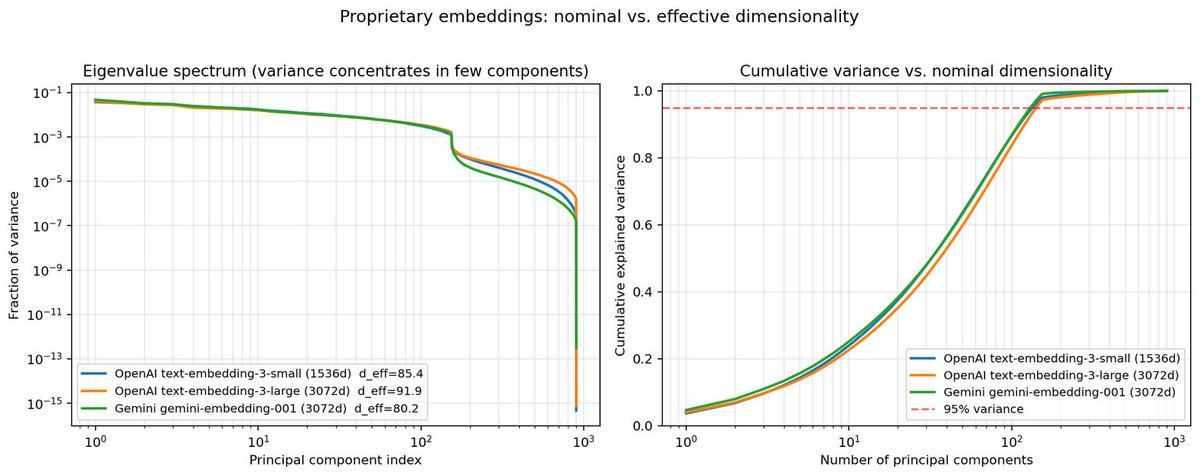
We finally know why LLMs hallucinate. It's not the model. It's the geometry.
@OpenAI text-embedding-3-large: 91/3072 dimensions do real work.
@GeminiApp gemini-embedding-001: 80/3072 dimensions do real work.
~97% of your vector database is mathematically empty. Your RAG system is retrieving from noise.
@ashwingop and I present "The Geometry of Consolidation" - a proof that RAG compression has a hard floor no algorithm can beat, set by a single spectral number your embedding model cannot escape.
Every hallucination your RAG pipeline produces? This is why.
Paper results: github.com/niashwin/geometry…

148
458
3,725
273,701
Kenny Guo retweeted

May 6
reinventing Groq's LPU with @michael_trbo
we got instruction driven data movement working between SRAM memory blocks and MXM compute!!
11
18
77
6,538
Kenny Guo retweeted
May 4
Featured on @AlphaSignalAI, thanks everyone for all the support!

3
3
36
1,650
Kenny Guo retweeted

May 3
Introducing CTRL!
We just turned any digital task into a single shareable link that runs itself on anyone’s device, automatically.
No more docs.
No more Loom videos.
No more “can you just screen-share real quick?”
One click. Done. On any computer.
15
17
45
4,532
Kenny Guo retweeted
May 2
Full writeup: v2.talos.wtf/
Contributions welcome if you want to push the RTL path further (maybe a leaderboard👀?).
Repo: github.com/Luthiraa/TALOS-V2
12
20
242
21,036
Kenny Guo retweeted
May 2
Attention was the most interesting part.
In Python, it is one clean equation.
In RTL, it becomes a schedule: generate Q/K/V, scan dot products, track max, approximate exp, accumulate, divide, mix V, then project back.
2
5
175
22,239
Kenny Guo retweeted
May 2
The core design uses Q4.12 fixed-point math and ROM-backed weights.
Most of the model becomes one repeated operation: matrix-vector multiply. So we built a reusable 16-lane streamed MatVec tile and time-multiplexed it across Q/K/V, MLP, and LM head.
2
7
176
23,842
Kenny Guo retweeted
May 2
The goal was not to make the largest model possible.
The goal was to make the entire transformer inference path readable as hardware: memories, counters, FSM states, accumulators, lookup tables, and multicycle arithmetic engines.
2
8
174
25,301
Kenny Guo retweeted
May 2
Another super fun experiment with @krish_chhajer.
Huge thanks to @xgawtham for letting us borrow the FPGA that made this possible.
3
2
123
27,114
Kenny Guo retweeted
May 2
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000 tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
266
696
7,506
851,237
Kenny Guo retweeted

Apr 25
Launching pyptx — a Python DSL for writing NVIDIA PTX kernels.
One PTX instruction = one Python call. Write pure PTX in Python.
Direct Hopper Blackwell support: wgmma, TMA, tcgen05, mbarriers. JAX PyTorch integration.
Includes GEMM, grouped GEMM, RMSNorm, SwiGLU, and a PTX→Python transpiler
pip install pyptx[torch]
pip install pyptx[jax]
github.com/patrick-toulme/py…
34
135
1,116
181,017