




kni retweeted

14 Feb 2025
iPhone users can relate

93
798
20,194
437,656
kni retweeted

13 Feb 2025
NEW: NYC comptroller Brad Lander whines after Elon Musk took back $80 million that the city was going to use on illegal immigrants, says the money just disappeared from their accounts.
Great!
The Trump admin issued a clawback after FEMA officials sent tens of millions of dollars to the city for illegal immigrants.
"This is highway robbery. This is the federal government having already allocated, authorized, awarded, invoiced, and paid $80M to the city of New York, and then Elon Musk with no legal authority seizing it back."
8,276
12,689
71,177
2,194,514
kni retweeted

10 Feb 2025
This "pastor" needs to be investigated as soon as Kash Patel is confirmed.
10 Feb 2025

Pastor Steve Caudle calls for "conflict" and "violence" against Elon Musk and D.O.G.E.
"When Elon Musk forces his way into the United States Treasury and threatens to steal your personal information and your Social Security check, there is a possibility of violence."
336
1,086
3,823
94,166
kni retweeted

6 Feb 2025
🚨BREAKING: Alex Jones Predicts A Globalist Cyber Attack On Government Payment Systems To Be Blamed On Musk
Watch/Share Alex Jones Cover What Happens Next!
x.com/i/broadcasts/1zqKVjQzg…
424
3,003
10,779
868,953
kni retweeted

1 Feb 2025
I was the lead market maker at Jump.
I'm no longer under NDA so I can say this,
Typically when you see down moves during the weekends like this, it is pure market manipulation.
It was one of the tactics I invented during the low volume moments.
We would load up and pay attention to Crypto Twitter as a source of sentiment, with specific accounts organized in specific categories.
One thing I used to like doing was purposely "nuking" a new 4H candle on BTC and/or ETH, which was an easy trap.
"Smart" traders know we'll eventually revisit those wickless candles, so it was good bait for me to set with eager buyers stepping in and the candle continuing lower.
They end up capitulating before we reverse.
Bottom shorters get comfortable here too.
Anyway, I can't give away too much but just know,
Most of thos "bad" price action you're seeing is a group of "whales" sitting in a chatroom together and merely oil painting on charts.
My alias in Jump was "Vincent van Gogh."
And that isn't because I lost my mind [well - that too],
But because I painted some of the best looking bear traps.
I know an influenced painter copying my work when I see one.
Stay safe.
Retar Dio.
1,018
2,235
20,093
4,966,034
kni retweeted

31 Jan 2025
Most interesting reply to this thread thus far from @MichaelEMcNeil

1
28
418
176,226
kni retweeted

27 Jan 2025
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed in AI. You may not always be utilizing it fully but I would never bet against compute as the upper bound for achievable intelligence in the long run. Not just for an individual final training run, but also for the entire innovation / experimentation engine that silently underlies all the algorithmic innovations.
Data has historically been seen as a separate category from compute, but even data is downstream of compute to a large extent - you can spend compute to create data. Tons of it. You've heard this called synthetic data generation, but less obviously, there is a very deep connection (equivalence even) between "synthetic data generation" and "reinforcement learning". In the trial-and-error learning process in RL, the "trial" is model generating (synthetic) data, which it then learns from based on the "error" (/reward). Conversely, when you generate synthetic data and then rank or filter it in any way, your filter is straight up equivalent to a 0-1 advantage function - congrats you're doing crappy RL.
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
(Last last thought/reference this time for real is that RL is powerful but RLHF is not. RLHF is not RL. I have a separate rant on that in an earlier tweet
x.com/karpathy/status/182127…)
26 Dec 2024

DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
Does this mean you don't need large GPU clusters for frontier LLMs? No but you have to ensure that you're not wasteful with what you have, and this looks like a nice demonstration that there's still a lot to get through with both data and algorithms.
Very nice & detailed tech report too, reading through.
360
2,118
14,275
2,438,392
kni retweeted

28 Jan 2025
“Social-conservative Fiscal-liberal” are the worst type of Republicans, yet they’re ascendant in Congress.
They’re tearing apart traditional family structures by wrecking our economy with big government spending.
698
2,153
14,779
224,370
kni retweeted

27 Jan 2025
waiting on an intro = lack of agency. just reach out
13
7
216
16,043
i give ross my thanks for joining crypto


26
kni retweeted

21 Jan 2025
.@arcprize quick project
Need extra hands to help with r1 testing for ARC Prize. Paid
Eng LLM work, python
Know anyone? Dm or greg@arcprize
17
20
137
41,231
kni retweeted

20 Jan 2025
DeepSeekの推論AIモデル「DeepSeek-R1」を使ってコーディングできる(成果も表示)「DeepSeek R1 Code Generator」が、Hugging Face内のAIチャット「anychat」に実装されました。無料でお試しできます。
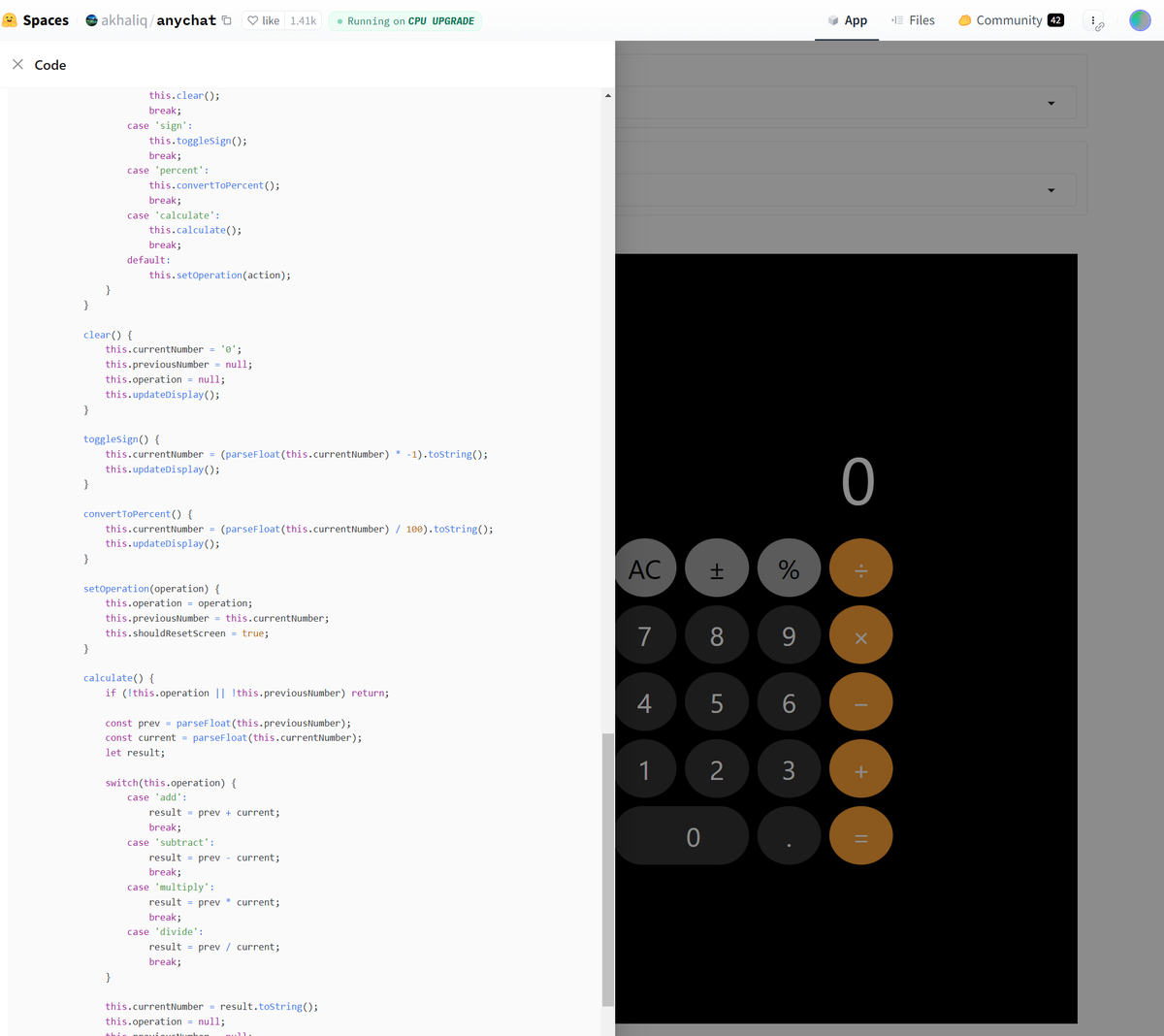
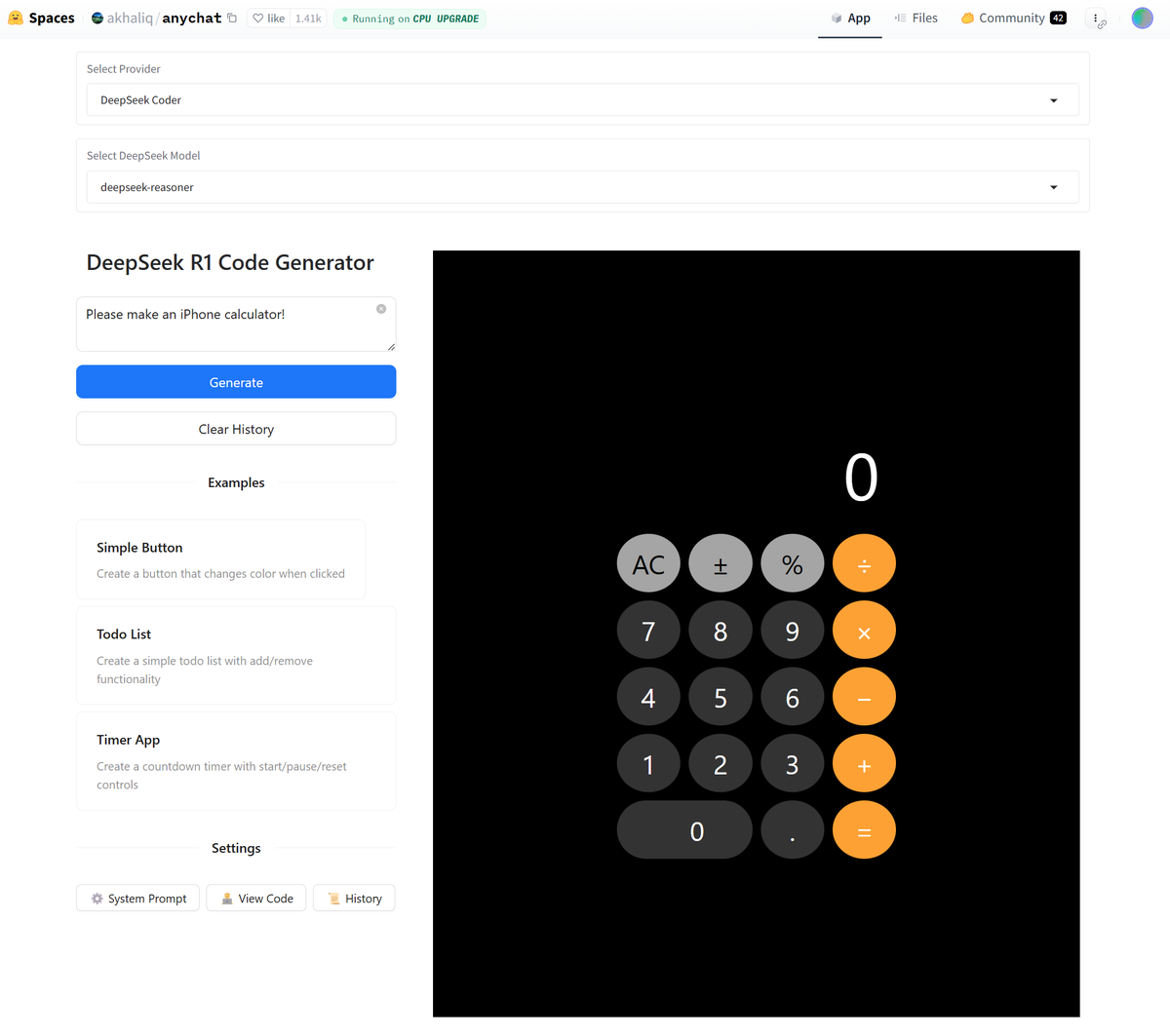
3
13
65
33,962