
the talisman of deep learning.
Joined March 2022
- Tweets 9,038
- Following 633
- Followers 3,250
- Likes 10,166
2,003 Photos and videos














Pinned Tweet

10 Sep 2025
mother of all demos. pt 2.
bodega OS is beautiful, unlimited and all ai models running locally on your hardware.
from porsche, westworld, to learning different planes of power, the giests and vishnu. playboi carti & personal notes at the end too.
it's crippling to use any other ai now. everything else feels bleak and lifeless.
11
6
56
13,227
May 30
openai and anthropic will no longer exist by 2027.
recession and civil war is intertwined by 2027. so expect a big boil.
there won’t be highest tier intelligence, llms are just function aggregators,you can aggregate past a threshold. ( which we have reached ). it will be commoditised like a tts.
space x s1 prospectus if you read it then you wouldn’t give out brain dead opinions on it.
nvidia will survive. wont reach 10T
May 29

Cold take on what comes next:
- OpenAI will flourish
- Anthropic will continue to be profitable
- Google will not catch up to Anthropic or OpenAI
- no chinese company will catch up to Anthropic or OpenAI
- the highest tier of intelligence will become a luxury product that only companies and multi-millionaires/billionaires can afford
- most of the companies that invested massively in them will have massive returns
- SpaceX’s AI will be fine and on par with Google by end of year
- Nvidia will become the first 10T company
3
306
Mar 24
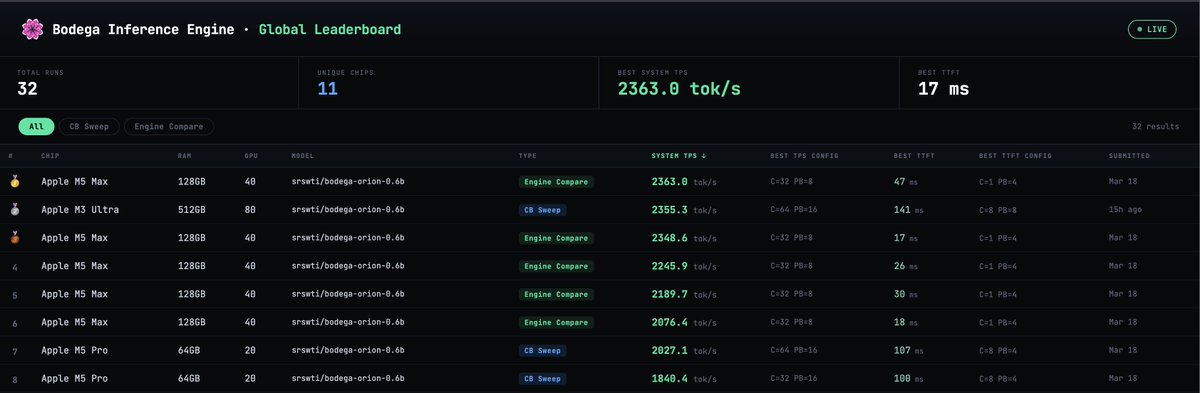
almost 2400 tok/s, 17ms ttft on local hardware seemed impossible. but trust me, it's not.
bodega is now the fastest runtime for local llm inference on the planet.
local ai is now more useful than cloud ai, matching it on model capabilities, throughput speed, and ttft.
1
8
463
knivesysl retweeted

Mar 2
1
5
506
Feb 27
we were supposed to study consciousness and make technology beautiful, but these dimwits are benchmaxxing a deadbeat llm, making computer agents fetch graphs, and generating cat monster videos.
2
11
394
Feb 24
people are now in illusion of “work done”. this is the time to perform magic with meaningful delta.
put your head down. focus on a singular unfathomable problem. spend every second working towards something which you will never achieve.
delta. make your ancestors proud.
1
1
4
288
Feb 23
software so good, people are streaming Bodega on twitch. no agentic flows bs, pure 808 beats and Carti leaks, buying 30 year old 911 flat six engines, Forza horizon gameplays, having fun.
kanye of software.
4
646
Feb 11
just by the way, here’s a soft implementation of our task scheduler ‘shadows’ which we try to patch every now and then for the community. (lately it’s been few weeks) but we gonna maintain shadows more.
it’s built for distributed background job processing with seamless scheduling, designed to be lightweight and fast. handles task queuing, retries, and failure recovery without bloating your main thread.
feel free to fork it, build on top of it, or dm me if you want something specific. :)
Feb 6

bro, last week we got neck deep with support tickets for Bodega. users saying their cpu was spiking hard during tasks that shouldn't even touch the gpu.
turned out our task scheduler was the problem. every time an agent spawned inference jobs or the voice pipeline queued audio processing, we were hammering redis. even when the worker was running on the same damn machine.
didn't do it manually. used axe, the coding agent we built for codebases where things breaking actually matters. it's our internal tool, been using it for close to 6 months now. some of the LLMs we used are especially trained on our codebases too. we dont use claude code, its incentivized to waste tokens and cost you more, plus cant let our shi be trained on their next models.
anyways, so we dug in. traced the bottleneck through 7 layers of our task queue. took 25 minutes. used way less tokens than you'd think. shipped the fix.
before: ~400-2500µs overhead per task. production speed around 2,000 tasks/sec.
after: ~0.5-5µs per task. 20,000 tasks/sec.
do the math lil bro!!!
cpu usage dropped back to normal. and actually, forgot to mention lol, axe also suggested this zero-copy optimization that made things even faster. wait i did mention the overhead speed above, anyways so yeah users happy now.
okay so why would u care? we maintain bodega, a voice os running entirely on your device. inside it there's an inference engine powering ai agents, voice pipelines, real-time audio processing, and a distributed task scheduler handling thousands of jobs per second. when something breaks here, people feel it immediately. we made bodega to be run literally on arch and in all three major OS platforms. so things can obv break even after fool proofing our best for 2 years.
the problem was our scheduler kept serializing every job, network call to redis, then deserializing on the other end. for local tasks where the worker's literally sitting right there? completely wasted cycles. that's what was murdering cpus.
here's the flow axe traced:
before (redis path):
serialize args/kwargs with cloudpickle (~50µs)
create redis message dict
inject opentelemetry context
XADD to redis stream (~100µs)
worker XREADGROUP from redis (~180µs)
deserialize args/kwargs (~50µs)
extract opentelemetry context
execute task
XACK XDEL to redis (~100µs)
total overhead: 400-2500µs per task
after (local queue path):
check local_queue exists? yes
queue.put(execution) (~0.2µs)
event.set() to wake worker (~0.2µs)
worker queue.get() (~1µs)
execute task (same execution object!)
total overhead: ~0.5-5µs per task
here's where most coding agents just don't work for us. claude code dumps 100 files into context, burns through tokens like scar, still misses how functions actually call each other, can't tell you what breaks when you change stuff. they're optimized for demos. for looking good in screenshots. not production systems where downtime costs our life, ngl actually our life. we treat each other as players in srswti, this is a football team lil bro not a family in this org-- each one of us has to perform at best.
axe does it differently. precision retrieval.
pulled exactly what we needed. who's calling the scheduler, what the scheduler calls, how task data flows from creation through the queue to workers, plus impact analysis showing what breaks if we bypass redis for local tasks. way fewer tokens. complete picture of what's happening.
before touching any code, axe showed us 23 call sites hitting task scheduling, 11 files getting affected, exact worker polling logic needing updates, which tests would fail. we shipped zero-copy local queues. 8x performance improvement. it did miss one thing which was to understand the we can just increase our local queue size to max, it can cause problems but thats fine-- thats what us engineers are there for as well.
this is what you need when maintaining large codebases. not websites or excel stuff or faking using gcc compilers on demos. its actually safe refactoring by actually understanding call signatures, dependencies, how data moves through your system.
axe does three things other slop agents can't:
understands large codebases through call graphs, not just dumping files
typical numbers: 99% fewer tokens on function refactors, 89% on codebase overviews, 95% on deep call chains. but here's the interesting part. sometimes axe uses MORE tokens than other tools. because we actually see full call graphs, data flow analysis, program dependencies, impact stuff. tracking down some nasty bug through 7 layers of code? we'll pull 150,000 tokens if that's what it takes. getting it right matters more than saving tokens.
works really well with local llms because we built it for hardware people actually own
bodega runs on all devices (rn only available for apple silicon doe, others coming soon in few weeks) , gaming laptops, whatever you've got. local llms are different though. slower prefill times, smaller context windows, no per-token costs. so we had to build precise retrieval from the ground up. turns out precision helps cloud models too. faster responses, lower costs, better understanding. we tested with our srswti/blackbird-she-doesnt-refuse-21b on m4 max. full agent capabilities, spawning subagents, 120 tok/s inference, everything running local. and yeah now we open sourcing it, because precision is somethign even cloud llms like opus or gpt5.2 can benefit from as well
so the version we released -- indexes the codebase initially--semantic search that finds what code does, not what it's named. its not rag or anything.
you ask "find code handling task queue consumption" grep finds variable names, comments, anything with "consume_task" in it axe finds the actual function polling redis consumer groups, deserializing task data, spawning worker threads. even if someone named it _internal_loop() or something random
how it works: axe-dig, our 5-layer retrieval process. ast for structure, call graphs for relationships, control flow for complexity, data flow for how values transform, program dependence for what affects what. every function gets embedded with what it actually does.
look, if you're building something new from scratch, use whatever works for you. but maintaining production systems? refactoring code someone wrote 3 years ago? working on distributed stuff where you need to understand things before shipping? want powerful agents running on your own machine?
yeah, we built axe for that.
open source now. terminal native. built by the most lethal team working on the fastest retrieval and inference platform
1
5
446
Feb 11
raw digital signatures of sound, emotion, prosody & expressiveness of a human is very very hard to train.
only a few can understand what we meant in this demo, & the post, let alone running it locally on your mom’s macbook air.
if not, go pay to these washed up ai labs lil bro
Feb 10
our text to speech is sota on benchmarks, highly expressive, even better than elevenlabs, and runs locally. unsure? -- see the demo below.
we're open sourcing the full model weights and recipes soon on HF/srswti. the reason it's so prosodic and natural? serpentine streaming.
okay so how does serpentine work?
traditional tts models either process complete input before generating output, or learn complex policies for when to read/write. we took a different approach. pre-aligned streams with strategic delays.
but here's the key innovation, its not an innovation more like a different way of looking at the same problem:
we add a control stream that predicts word boundaries in the input text. when the model predicts a word boundary (a special token indicating a new word is starting), we feed the text tokens for that next word over the following timesteps.
while these tokens are being fed, the model can't output another word boundary action. we also introduce a lookahead text stream. the control stream predicts where the next word starts, but has no knowledge of that word's content when making the decision.
given a sequence of words m₁, m₂, m₃... the lookahead stream feeds tokens of word mᵢ₊₁ to the backbone while the primary text stream contains tokens of word mᵢ. this gives the model forward context for natural prosody decisions. it can see what's coming and make informed decisions about timing, pauses, and delivery.
training data: 7,600 hours of professional voice actors and casual conversations - modern slang, lingo, and how people actually speak 50,000 hours of synthetic training on highly expressive tts systems this training approach is why the prosody and expressiveness feel different from existing systems.
the model understands context, emotion, and emphasis because it learned from natural human speech patterns.
you can try it now on www dot srswti dot com/ downloads--Bodega uses this model as part of our speech to speech engine which runs locally and sounds gorgeous like this.
welcome to the world of dreamers.
1
8
643
Feb 11
if you agree w this washed up goat of yours, feel free to take some time off, love your wife, take care of your necessities, & yuh feel free to unfollow me as well.
this is how yall think of single line of code as. not as instruction sets compiling to a machine— but as this.

Code itself will go away in favor of just making the binary directly.
The next step after that is direct, real-time pixel generation by the neural net.
1
7
444
Feb 10
our text to speech is sota on benchmarks, highly expressive, even better than elevenlabs, and runs locally. unsure? -- see the demo below.
we're open sourcing the full model weights and recipes soon on HF/srswti. the reason it's so prosodic and natural? serpentine streaming.
okay so how does serpentine work?
traditional tts models either process complete input before generating output, or learn complex policies for when to read/write. we took a different approach. pre-aligned streams with strategic delays.
but here's the key innovation, its not an innovation more like a different way of looking at the same problem:
we add a control stream that predicts word boundaries in the input text. when the model predicts a word boundary (a special token indicating a new word is starting), we feed the text tokens for that next word over the following timesteps.
while these tokens are being fed, the model can't output another word boundary action. we also introduce a lookahead text stream. the control stream predicts where the next word starts, but has no knowledge of that word's content when making the decision.
given a sequence of words m₁, m₂, m₃... the lookahead stream feeds tokens of word mᵢ₊₁ to the backbone while the primary text stream contains tokens of word mᵢ. this gives the model forward context for natural prosody decisions. it can see what's coming and make informed decisions about timing, pauses, and delivery.
training data: 7,600 hours of professional voice actors and casual conversations - modern slang, lingo, and how people actually speak 50,000 hours of synthetic training on highly expressive tts systems this training approach is why the prosody and expressiveness feel different from existing systems.
the model understands context, emotion, and emphasis because it learned from natural human speech patterns.
you can try it now on www dot srswti dot com/ downloads--Bodega uses this model as part of our speech to speech engine which runs locally and sounds gorgeous like this.
welcome to the world of dreamers.
3
2
13
1,234

Feb 6
bro, last week we got neck deep with support tickets for Bodega. users saying their cpu was spiking hard during tasks that shouldn't even touch the gpu.
turned out our task scheduler was the problem. every time an agent spawned inference jobs or the voice pipeline queued audio processing, we were hammering redis. even when the worker was running on the same damn machine.
didn't do it manually. used axe, the coding agent we built for codebases where things breaking actually matters. it's our internal tool, been using it for close to 6 months now. some of the LLMs we used are especially trained on our codebases too. we dont use claude code, its incentivized to waste tokens and cost you more, plus cant let our shi be trained on their next models.
anyways, so we dug in. traced the bottleneck through 7 layers of our task queue. took 25 minutes. used way less tokens than you'd think. shipped the fix.
before: ~400-2500µs overhead per task. production speed around 2,000 tasks/sec.
after: ~0.5-5µs per task. 20,000 tasks/sec.
do the math lil bro!!!
cpu usage dropped back to normal. and actually, forgot to mention lol, axe also suggested this zero-copy optimization that made things even faster. wait i did mention the overhead speed above, anyways so yeah users happy now.
okay so why would u care? we maintain bodega, a voice os running entirely on your device. inside it there's an inference engine powering ai agents, voice pipelines, real-time audio processing, and a distributed task scheduler handling thousands of jobs per second. when something breaks here, people feel it immediately. we made bodega to be run literally on arch and in all three major OS platforms. so things can obv break even after fool proofing our best for 2 years.
the problem was our scheduler kept serializing every job, network call to redis, then deserializing on the other end. for local tasks where the worker's literally sitting right there? completely wasted cycles. that's what was murdering cpus.
here's the flow axe traced:
before (redis path):
serialize args/kwargs with cloudpickle (~50µs)
create redis message dict
inject opentelemetry context
XADD to redis stream (~100µs)
worker XREADGROUP from redis (~180µs)
deserialize args/kwargs (~50µs)
extract opentelemetry context
execute task
XACK XDEL to redis (~100µs)
total overhead: 400-2500µs per task
after (local queue path):
check local_queue exists? yes
queue.put(execution) (~0.2µs)
event.set() to wake worker (~0.2µs)
worker queue.get() (~1µs)
execute task (same execution object!)
total overhead: ~0.5-5µs per task
here's where most coding agents just don't work for us. claude code dumps 100 files into context, burns through tokens like scar, still misses how functions actually call each other, can't tell you what breaks when you change stuff. they're optimized for demos. for looking good in screenshots. not production systems where downtime costs our life, ngl actually our life. we treat each other as players in srswti, this is a football team lil bro not a family in this org-- each one of us has to perform at best.
axe does it differently. precision retrieval.
pulled exactly what we needed. who's calling the scheduler, what the scheduler calls, how task data flows from creation through the queue to workers, plus impact analysis showing what breaks if we bypass redis for local tasks. way fewer tokens. complete picture of what's happening.
before touching any code, axe showed us 23 call sites hitting task scheduling, 11 files getting affected, exact worker polling logic needing updates, which tests would fail. we shipped zero-copy local queues. 8x performance improvement. it did miss one thing which was to understand the we can just increase our local queue size to max, it can cause problems but thats fine-- thats what us engineers are there for as well.
this is what you need when maintaining large codebases. not websites or excel stuff or faking using gcc compilers on demos. its actually safe refactoring by actually understanding call signatures, dependencies, how data moves through your system.
axe does three things other slop agents can't:
understands large codebases through call graphs, not just dumping files
typical numbers: 99% fewer tokens on function refactors, 89% on codebase overviews, 95% on deep call chains. but here's the interesting part. sometimes axe uses MORE tokens than other tools. because we actually see full call graphs, data flow analysis, program dependencies, impact stuff. tracking down some nasty bug through 7 layers of code? we'll pull 150,000 tokens if that's what it takes. getting it right matters more than saving tokens.
works really well with local llms because we built it for hardware people actually own
bodega runs on all devices (rn only available for apple silicon doe, others coming soon in few weeks) , gaming laptops, whatever you've got. local llms are different though. slower prefill times, smaller context windows, no per-token costs. so we had to build precise retrieval from the ground up. turns out precision helps cloud models too. faster responses, lower costs, better understanding. we tested with our srswti/blackbird-she-doesnt-refuse-21b on m4 max. full agent capabilities, spawning subagents, 120 tok/s inference, everything running local. and yeah now we open sourcing it, because precision is somethign even cloud llms like opus or gpt5.2 can benefit from as well
so the version we released -- indexes the codebase initially--semantic search that finds what code does, not what it's named. its not rag or anything.
you ask "find code handling task queue consumption" grep finds variable names, comments, anything with "consume_task" in it axe finds the actual function polling redis consumer groups, deserializing task data, spawning worker threads. even if someone named it _internal_loop() or something random
how it works: axe-dig, our 5-layer retrieval process. ast for structure, call graphs for relationships, control flow for complexity, data flow for how values transform, program dependence for what affects what. every function gets embedded with what it actually does.
look, if you're building something new from scratch, use whatever works for you. but maintaining production systems? refactoring code someone wrote 3 years ago? working on distributed stuff where you need to understand things before shipping? want powerful agents running on your own machine?
yeah, we built axe for that.
open source now. terminal native. built by the most lethal team working on the fastest retrieval and inference platform
3
2
8
1,006
Feb 6
here is our HF, we open sourced reasoning models from 90m to multimodal models with amazing agentic coding capabilities as well-- all keeping in mind with low memory footprint.
huggingface.co/collections/s…
1
3
236
Feb 6
uv pip install axe-cli
go to your project path, and write "axe"-- your good to go, and yeah please python 3.13 recommended
enjoy! its still in preview, we would love to welcome contributions, and maintainers as well :
github.com/SRSWTI/axe
1
7
344
Feb 1
in a world full of lies, deception, and false idols-
become a person who provides service before self, remains self-critical, perpetually optimises for helping people by any means, and practices intellectual honesty.

5
269