
1 Photos and videos
kush thaker retweeted

Jun 10
You can now run @supermemory locally.
Introducing the supermemory local
- Fully self-contained. Comes with our graph engine, embedding model, etc.
- Run on any machine, with your @openclaw, hermes, claude, etc.
- SDKs to add memory to your agent, or build your company brain.
149
93
1,754
588,084

kush thaker retweeted

Jun 5
we’re donating $10 to charity for every person that shares a memory with me!
see you at Dolores :)
Jun 5

let's walk down the Memory Lane
Saturday 12 PM @ Mission Dolores Park
see y'all there!
1
2
5
395
kush thaker retweeted
May 29
I made a universal company brain.
- connect to ANY agent natively
- Git-like versioning and RBAC permissioning
- connectors to all sync tools of companies
- Dreams about your company
- run on-prem. Free to start.
it's live today.
we've been using it for 6 months @supermemory

28
24
476
253,592
kush thaker retweeted

May 28


6
25
3,620
kush thaker retweeted
May 28
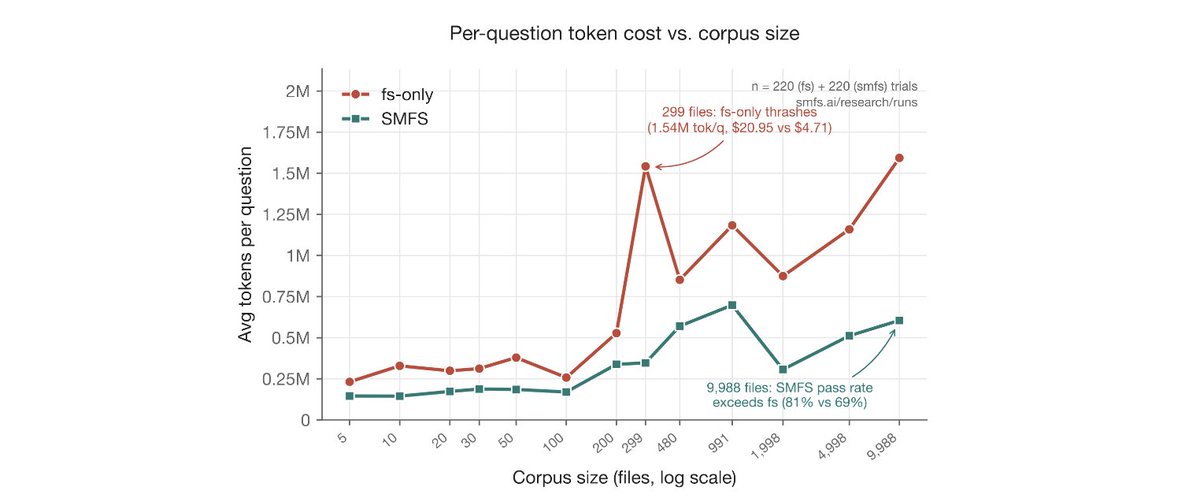
We set out to find out how we can build the best filesystem for agents out there.
SMFS is consistently better in terms of tokens, cost, latency AND accuracy.
Technical report here: smfs.ai/research/memory-as-a…
2
4
37
4,281
kush thaker retweeted
May 28
Agent observability can be more than logs and traces.
Introducing Qualitative Analysis.
it's FREE for next 3 months 👇
@Supermemory can now automatically give you reports on your users/agents - which you can tailor and ask questions to!
Eg: "What's the split of developers?"
20
11
179
23,537


kush thaker retweeted
May 27
The Context Cloud for agents is here.
Introducing the new @supermemory.
A new way to do context, for your agents
Everything you need for context - Memory, RAG, Filesystems, Profiles, are now available as blocks you can compose to build something for your use case
46
24
436
88,031
kush thaker retweeted
May 26
Agent can grep, find, cat and append using new preprint representation

1
11
33
11,023
kush thaker retweeted
May 26
Today, we're switching to Dynamic Dreaming in the supermemory API
It's an interesting and honestly, magical new way to do memory. I wrote a bit about it here 👇
2
4
35
3,538
kush thaker retweeted
May 26
wtf. Web pages as text files?!?!
Instead of vision and images, Preprint enables LLMs to edit the markdown files to do actions on the browser.
This is insane!
1
5
87
16,654
kush thaker retweeted
May 26
What if project the web Into the substrate LLMs already work with
github.com/supermemoryai/pre…
2
11
1,787
kush thaker retweeted
May 26
10
17
184
19,215
kush thaker retweeted
May 17
Fun story:
Kush helped me build the v0 of supermemory, 2 years ago.
We kept in touch, and now he's in the team, handling the infrastructure now that usage is exploding!
May 17

Life Update: Joined @supermemory to make your agents unforgettable!
6
2
100
10,895
kush thaker retweeted

May 18
We built an AI hackathon judge!
Agentic evaluators are a fascinating, fast-moving space.
We ran an experiment for a recent hackathon in partnership with @AnthropicAI and @genspark_ai, and learned a ton about where agents help, where they fail, and where humans need to stay in the loop.
Wrote about those lessons, and how we're thinking about making project and builder evaluation fairer, more evidence-based, and more robust at scale 👇

1
8
14
1,246

May 17
Life Update: Joined @supermemory to make your agents unforgettable!
May 17
we’re hanging out at the @ycombinator and @AgentPhoneHQ hackathon today
if you’re around, come chat with us!

12
2
96
18,928
Mar 7
Introducing Hatch: A lightweight microVM orchestrator designed for agentic workloads.
Give every agent its own VM.
1
1
3
650