
AI engineer @lancedb | prev @kuzudb. Blogging @ thedataquarry.com
Joined October 2013
- Tweets 4,124
- Following 1,872
- Followers 2,350
- Likes 15,917
248 Photos and videos











Jun 12
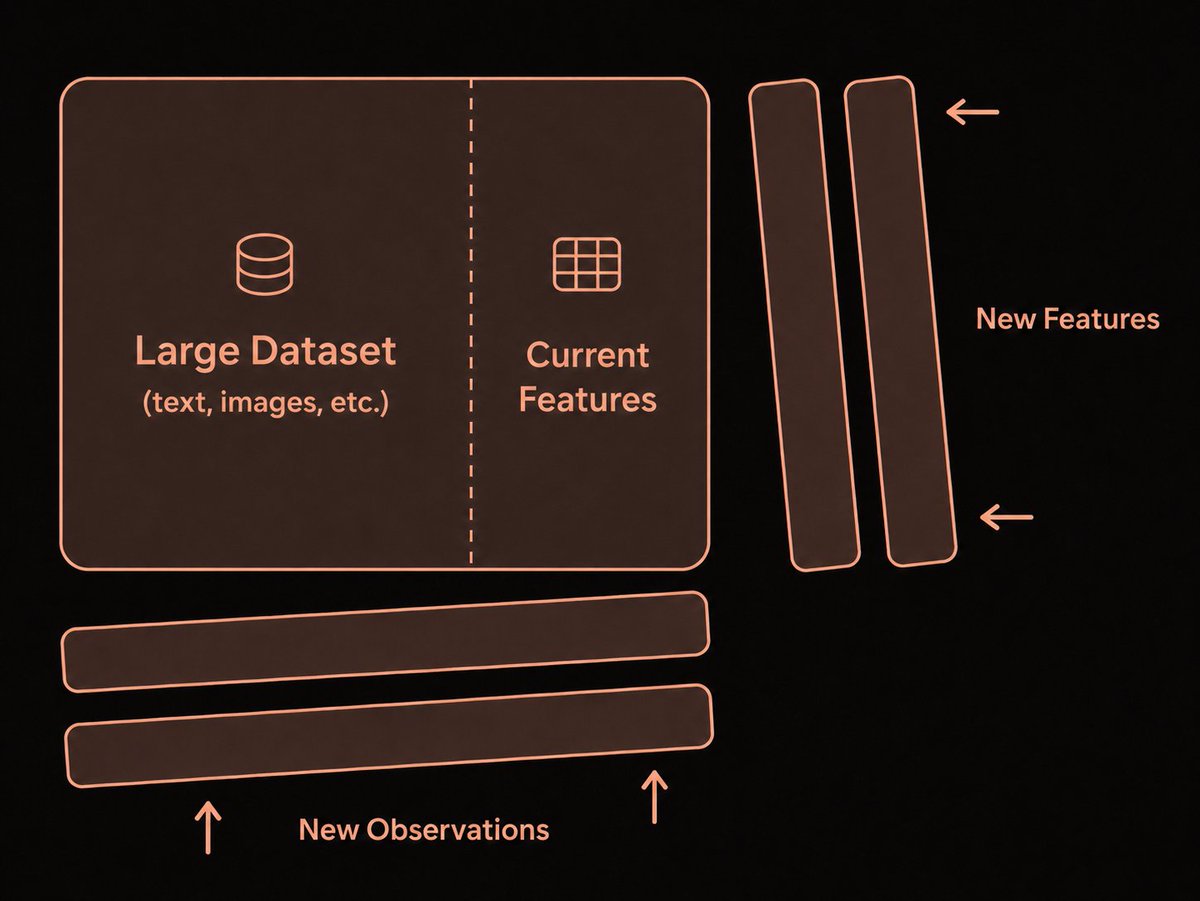
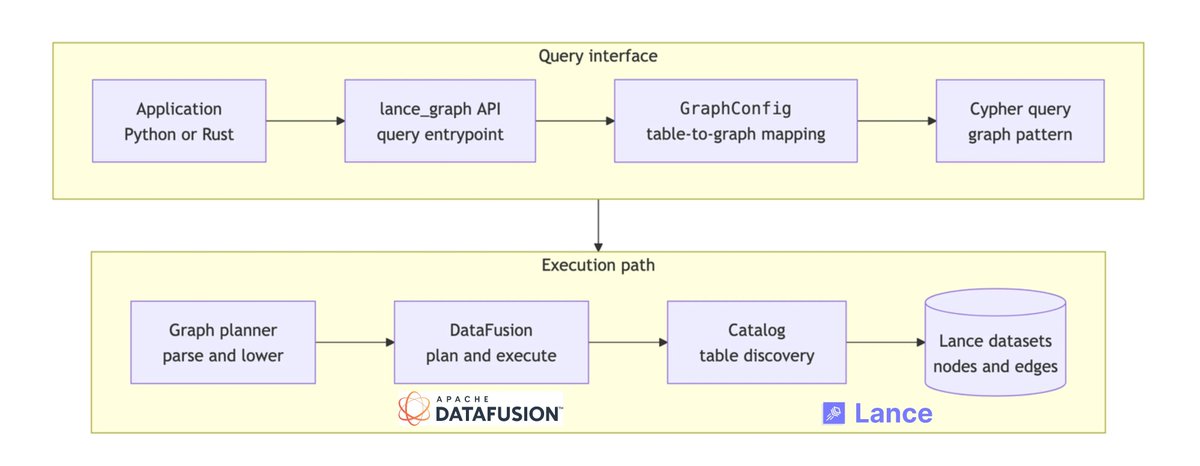
1/6 This recent post is about multimodal feature engineering, which looks simple on paper: write a function, get a new signal.
The hard part is everything else around it: applying it at scale, avoiding drift, handling failures, and knowing its history.
lancedb.com/blog/scalable-fe…
1
1
6
427
Jun 12
5/6 Manual backfills work when the job is small on a single machine.
But model-backed features over huge multimodal datasets need batching, distributed execution, GPU placement, retries, checkpointing, and reproducibility.
That’s where Geneva, an Enterprise feature engineering package in @lancedb, comes in.
docs.lancedb.com/geneva
1
2
61
Jun 12
6/6 You define the per-row computation as a UDF in the Geneva API, register it as a column, and run the backfill.
The *system* handles scale and records the UDF version with the data, which is itself versioned by @lancedb. The AI researcher/engineer focuses on what matters: running experiments and building features.
Read the blog post, with use cases and snippets to learn more! 🚀
lancedb.com/blog/scalable-fe…
2
72
Jun 10
Should be a fun week coming at #DataAISummit, if you're in SF, check out the talks! 🚀

1/ Two LanceDB sessions at @databricks #DataAISummit next week in SF (June 15-18)

1
7
631
Jun 10
Another great one! 👇🏽
Jun 10

Excited to be speaking at @databricks Databricks Data AI Summit next week on June 15th! My Session is in the afternoon. Will cover topics around building fresh data view for long horizon agents and our insights about it building @cocoindex_io and live demo. Looking forward to exchange ideas and see you there! #DataAISummit
Ping me if you are around and would love to grab a casual coffee!

1
5
515
Jun 8
Really looking forward to this one! To everyone in Toronto, let's look at @lancedb and how it enhances training data workflows at @TMLS_TO!
Register here: torontomachinelearning.com/t…
Prashanth Rao @tech_optimist and Sarwar Bhuiyan are running a workshop at TMLS on June 19.
𝗘𝗻𝗵𝗮𝗻𝗰𝗶𝗻𝗴 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝘄𝗶𝘁𝗵 𝗟𝗮𝗻𝗰𝗲 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗟𝗮𝗸𝗲𝗵𝗼𝘂𝘀𝗲
They're covering Lance's architecture and what makes it suited for ML workloads (fast random access, native blob storage, built-in versioning), live PyTorch and Hugging Face integration examples, a 3D world-model dataset case study, and I/O benchmarks during data loading.
If you're managing multimodal training data at scale and your storage, search, and training layers are still three separate systems, this one's for you.

8
390
Jun 3
👀 My eyes spy a killer 🔥 new feature coming out soon in @lancedb: "first-class support for table branching across the Rust, Python and TypeScript SDKs".
The team is COOKING!!
🥳 🚀
github.com/lancedb/lancedb/p…
1
9
574
Jun 3
2
3
301
Jun 3
Ahh nvm, I just remembered that this is at the LanceDB layer, and you're operating at the Lance layer. Oh well!
1
1
299
Prashanth Rao retweeted

Jun 2
unsurprisingly, the best food i ate in London was Chinese


225
306
13,101
656,034
Jun 2
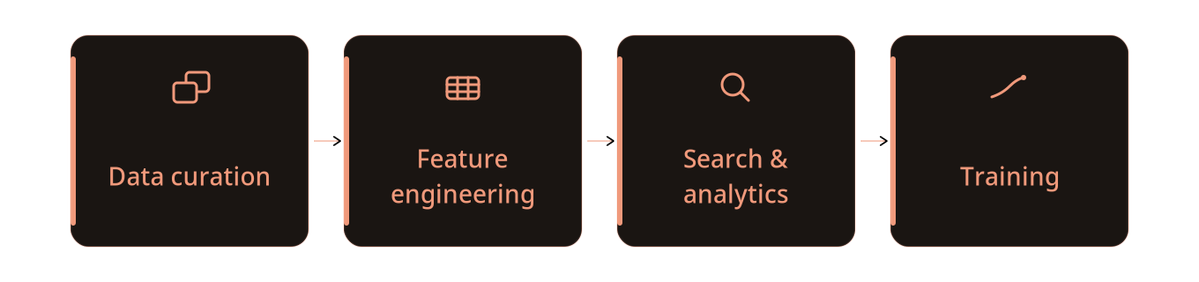
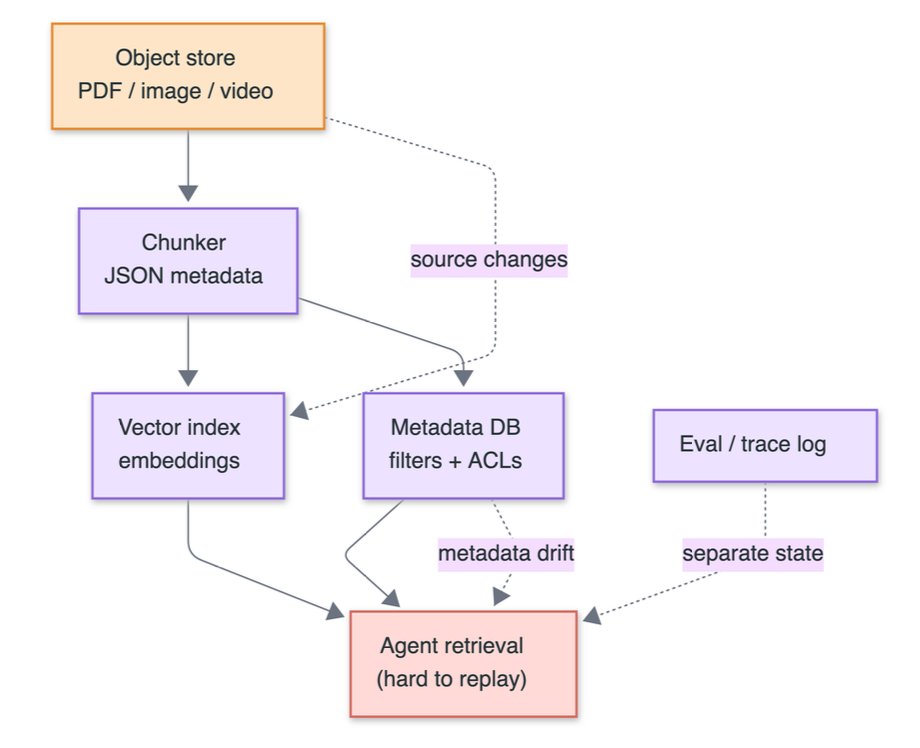
Dataset curation looks like a search problem at first, but for training pipelines the hard part is everything around it: filtering, deduping, sampling, inspection, materializing the subset, and being able to reproduce the decision later.
I wrote about how we’re thinking about this at @lancedb for the next generation of AI data infrastructure:
lancedb.com/blog/reproducibl…
1/6
1
13
482
Jun 2
From a user perspective, the end state is not simply "I found a useful subset."
It’s a durable training search artifact: a Lance table, accessible in @lancedb with the selected rows, raw data, embeddings, metadata, indexes, provenance, and version history.
Downstream feature engineering, search, analytics and training workflows can pin to the same curated dataset instead of reconstructing it from an ad hoc notebook state that knows nothing about data provenance.
5/6
1
83
Jun 2
At @lancedb, these kinds of problems around ease of experimentation, exploration, reusability and reproducibility, along with the immense scale of data that AI researchers are handling on a daily basis, are fundamental to how we think about where AI data infra is headed.
Read the blog for more details, and watch out for more interesting posts, including benchmarks and training experiments, coming soon! 👇🏽
6/6
lancedb.com/blog/reproducibl…
66
Jun 1
So cool! @nvidia's Cosmos 3 team (building next gen Physical AI infrastructure) is building on top of Lance!
"Unified data layer: SILA organizes data curation as a unified columnar Lance dataset (Pace et al., 2025), where each row represents a data sample and each typed column represents a curation signal such as a caption, tag, quality score, or annotation."
Link to the full report: research.nvidia.com/labs/cos…
Cosmos 3 by @nvidia released today — a frontier omnimodal world model for Physical AI.
For the data infrastructure behind it, they built on Lance.
SILA, NVIDIA's internal curation platform, processes tens of billions of multimodal training candidates as a single Lance dataset. Curation signals, embeddings, and vector indexes all in one table. No separate vector DB.
One table from raw data to training-ready.

1
18
1,638