
Dogelayer aims to return mining rewards to those who create real value
Joined November 2025
- Tweets 639
- Following 201
- Followers 316
- Likes 371
118 Photos and videos









Dogelayer|SN80 retweeted

This week, @const_reborn speaks with @sebyrubino
#SN46 @zipcodenetwork building accurate property appraisal models on Bittensor.
SN46 Miners submit models ~30 days before evaluation;
evaluation uses properties listed and sold within the last 30 days - ensuring models are tested on data they couldn't have seen
Novelty Search E076
>> Live via Bittensor Discord

10
33
195
9,958
Dogelayer|SN80 retweeted

Jun 11
We've talked a lot about how our efforts to train AI to shop will be entirely open source. Through Bittensor, we're committed to that ethos.
We're excited to share our pre-print on arXiv, our code, our data and our entire post-training pipeline.
Huge shoutout and thanks to @JarrodBarnes in helping us leverage this very valuable data.
This is how AI is going to learn to shop.

Jun 1

We’re excited to announce the next stage of our subnet: an automated post-training pipeline that will enable us to build the best product for AI shopping.
It’s only been 50 days, but we’re now getting 20k high-quality trajectories per day that are rich training signals for online shopping tasks.
Using the trajectories we have thus far, we saw an 18% → 42% climb on Qwen3-4B base using our post-training pipeline.
5
23
93
19,192

Jun 11
Still observing. Still here.

1
1
120
Jun 11
👍
Jun 10

The Grayscale $TAO ETF story is massive. Wall Street is officially knocking on the SEC’s door to bring Bittensor to traditional finance
A few years ago, TAO was a niche DeAI project Today, it’s being treated as an institutional grade asset
The market is starting to recognize what many have missed

1
73
Dogelayer|SN80 retweeted

Jun 9
Our #1 @proofoftalk 2026 takeaway:
The "just talk" phase is over. We've entered Bittensor's era of real-world adoption.
Top subnets are shipping real products, delivering valuable intelligence at cost-leader pricing, and fully integrated into clients' businesses: from SaaS to home hardware to data centers to gas stations.
Some examples:

ALT Yuma CRO Evan Malanga speaking on the Bittensor track at Proof of Talk 2026
8
27
136
11,014
Jun 10
Everything is back
2
237
Dogelayer|SN80 retweeted

Jun 9
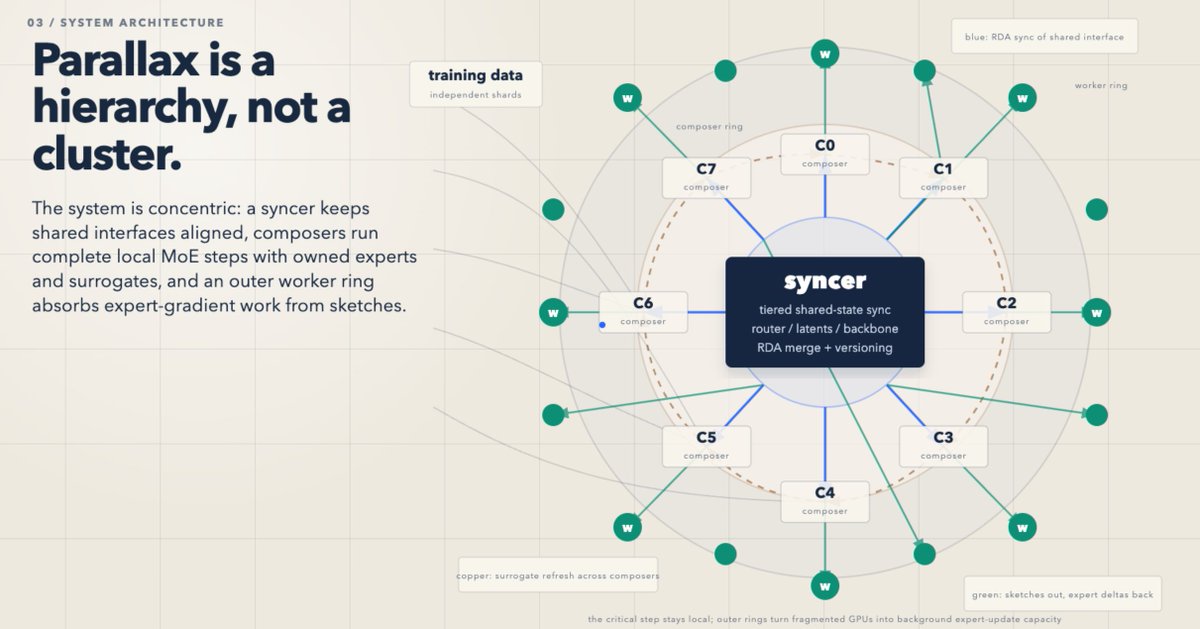
Here's a draft of the tech report on the model training method I've been experimenting with, "Parallax".
chutes.ai/parallax.pdf
TL;DR: MoE models' params are mostly routed experts, and you can massively reduce VRAM and FLOPS per participant by splitting up those experts. You can also offload the expert training to commodity hardware further saving compute/VRAM per island.
The crazy cool thing about these sketches is, you can actually onboard workers nearly instantly (sync time with ternary weights is a few MB), and they never need to download or stream the raw datasets (sketches contain all the work they need to do and are tiny). You'd probably want the first couple layers of the model in your own infra if you had sensitive data because otherwise you could do gradient inversion attacks to reconstitute the raw text, but beyond the first couple layers and not knowing which layer/expert you're training I think it's infeasible so privacy is pretty baked in.
Decoupled DiLoCo/RDA-diloco style backbone sync, surrogates for non-owned routed experts with low rank updates to sync those, tiered sync cadences for various components, "sketches" to offload expert work, etc.
20b tested two different ways, plenty of small model iterations, and 176b params just to prove out feasibility.
There are hundreds of additional experiments and loads of data we could also highlight as well, but the guts are there.
Variations:
- freeze routed expert weights instead of using surrogates, eliminates adam state, backward pass, etc., though you'd need different sync methods vs. low rank updates to the surrogates (the surrogates are already tiny, rank-8 updates to those even smaller)
- hierarchical parallax, i.e. each node itself becomes an rda diloco style multi-learner which then syncs with the outer/global islands (the point here is to enable GPUs without NVLink/etc. and reduce GPU<=>GPU comms to maximize MFU on less-capable/commodity GPUs)
- pipeline parallelize each island itself such that each island can decompose the backbone etc.
26
58
200
36,342
Jun 9
No matter how many setbacks we face, never stop moving forward
1
226
Dogelayer|SN80 retweeted

Jun 7
Proof of Talk: done ✓
Bittensor showed up loud.
Now comes Exploit - our conference. Our room. Our rules.
1,000 builders and breakers in Montréal. Sept 28–29.
Phase 1 tickets close in a month! Don't sleep on it 👇

3
13
53
11,032
Dogelayer|SN80 retweeted

Jun 8
Bittensor subnets are beginning to attempt to break history... Again.
Everything you've missed with bittensor:native this week:
Timestamps:
0:00 The AI Giants Are Coming
2:56 The Subnets Heating Up
6:46 The Founder Breaks It Down 10:35 Nvidia's CEO Noticed
15:13 Is The Bottom In?
18:34 One Subnet To Watch
10
33
199
7,827
Jun 8
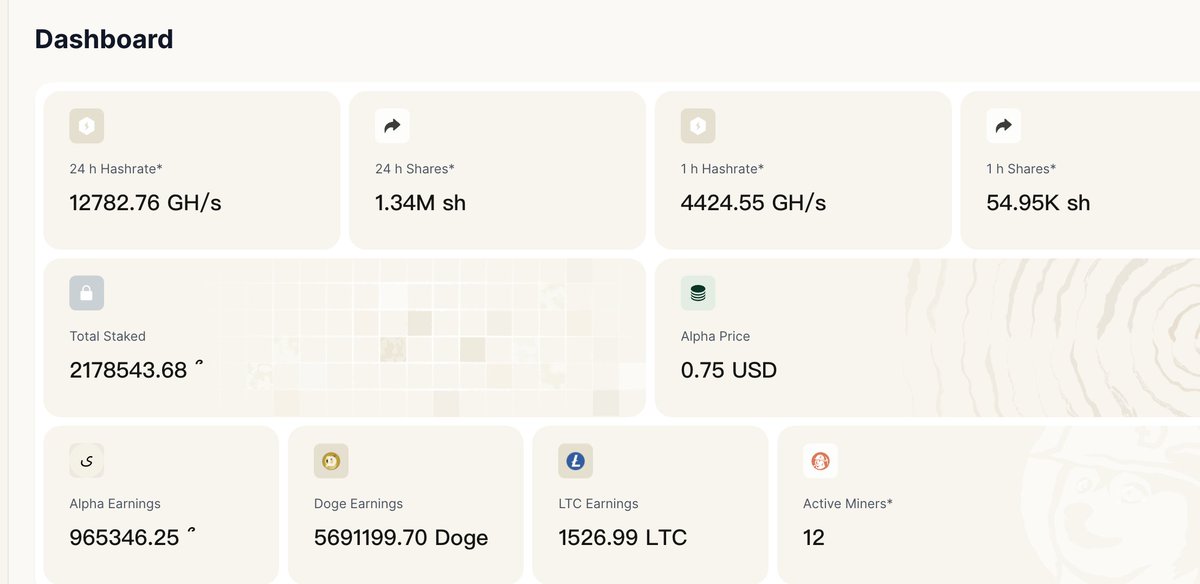
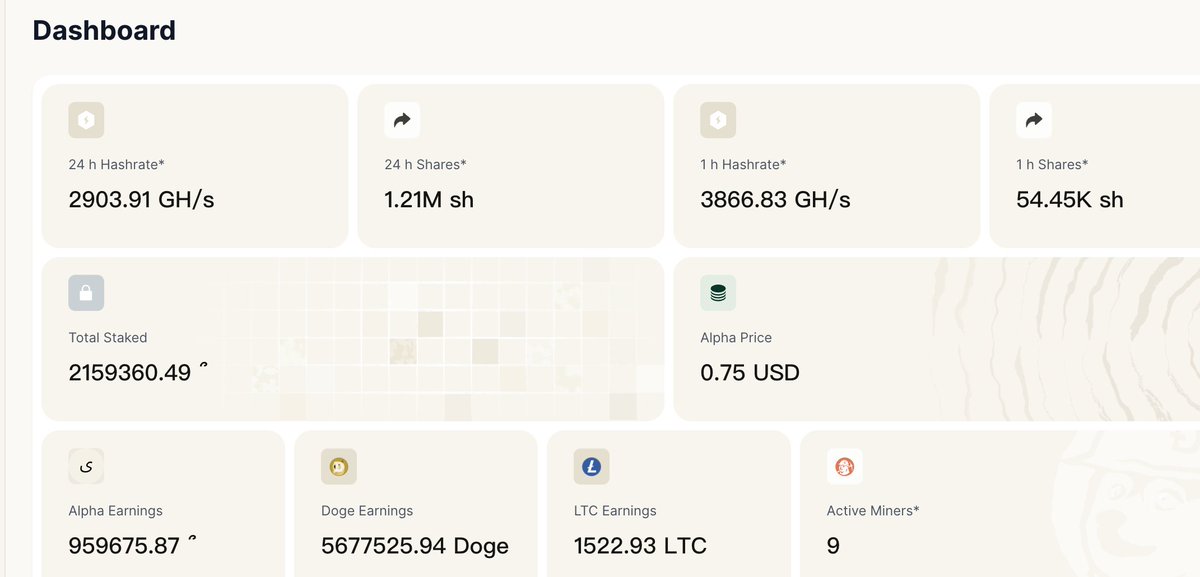
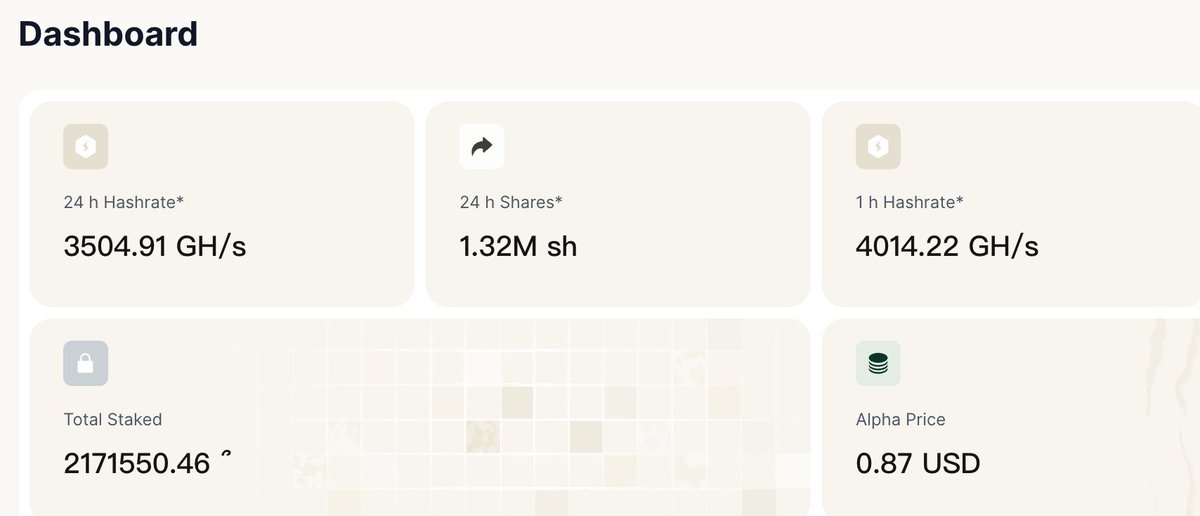
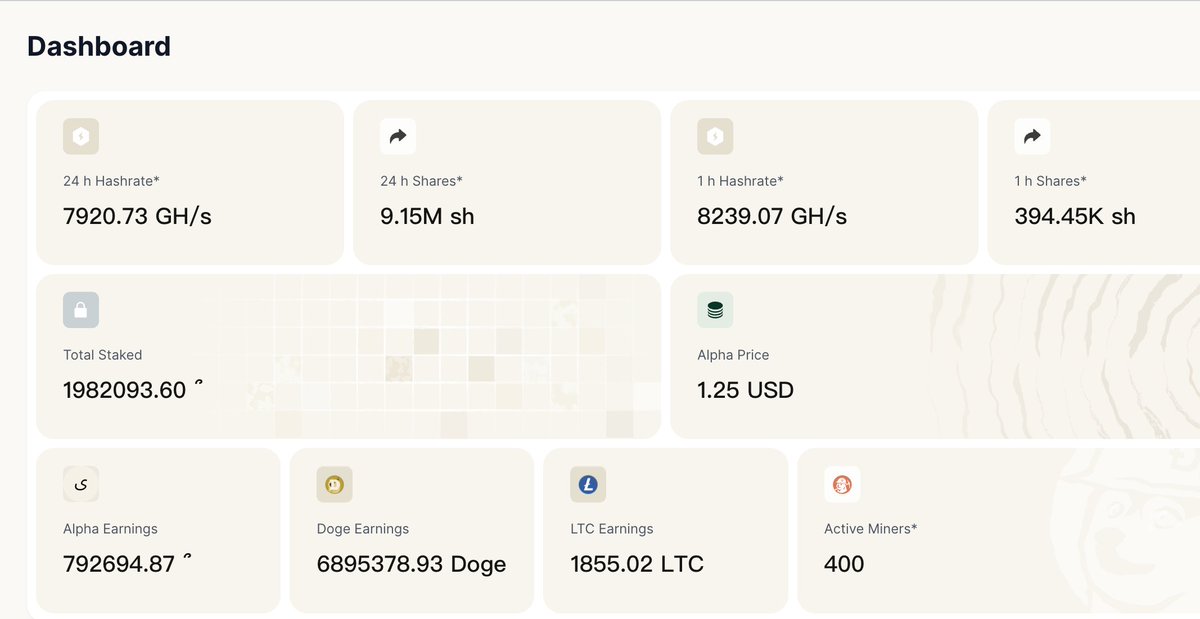
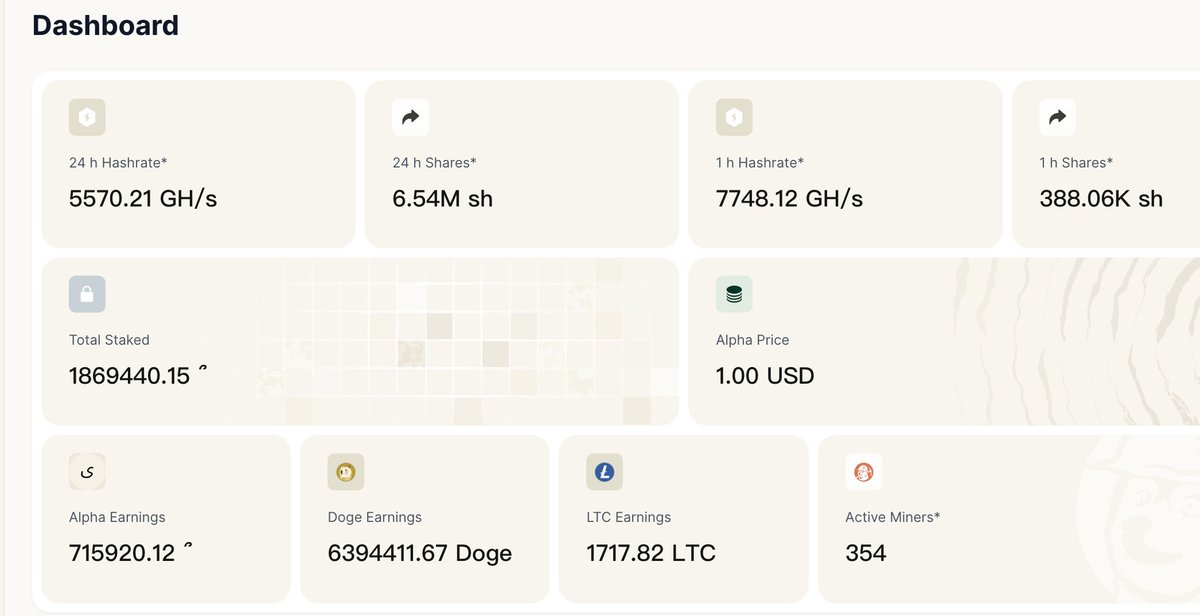
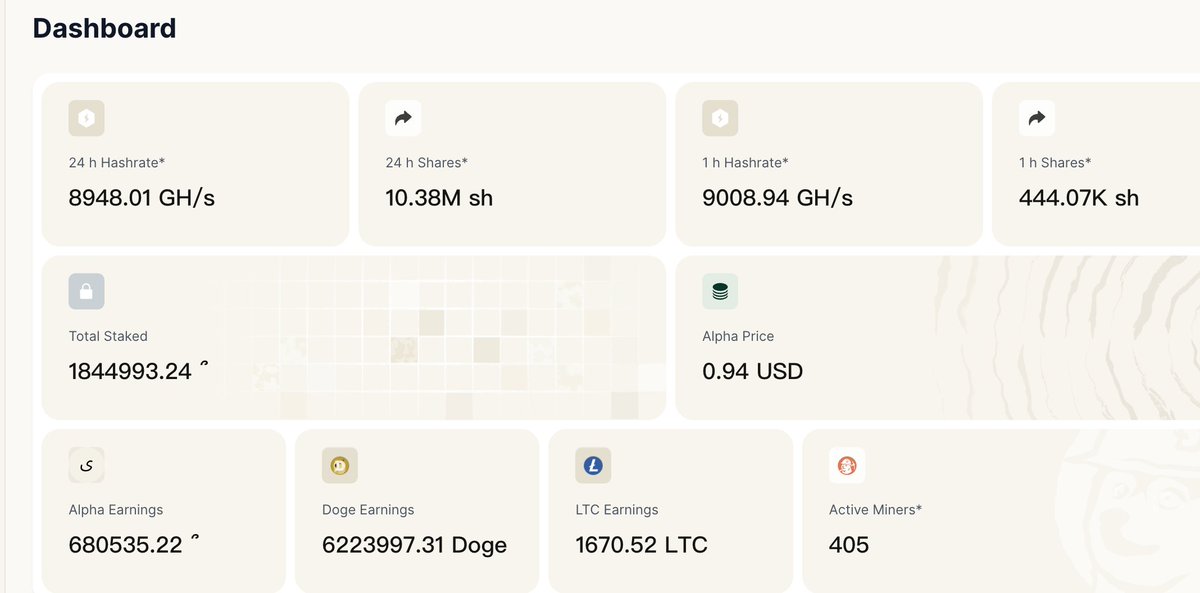
Technical Note: SN80 Production Environment h60 Hashrate Anomaly (2026-06-07)
Target of Anomaly: hotkey 5F4g2C8kqVkFCgF9HCmBPckJq4FwEYbQvTLXBYdkMYzZpjwQ, primarily contributed by worker ...hotkey.1
Symptoms: The 09:37 UTC snapshot showed h60 ≈ 41930 GH (~42 TH/s), h5 ≈ 35 GH, and h24 ≈ 2244 GH. Under the same hotkey, wkrs=4, but the anomaly was heavily concentrated on .1.
Root Cause Overview
This was a single-worker connection-level incident caused by a combination of a miner submit flood and F2Pool VarDiff (variable difficulty) dynamic adjustments. It was not a pool-wide outage, nor an error in the proxy hashrate formula.
1. Submit Flood (.1 worker)
Between 09:25 and 09:30 UTC, .1 had approximately 15,000 shares accepted within about a 15-minute window (peaking at around 9,383 shares/minute at 09:27, compared to a normal rate of ~30 shares/minute). The uniq_ratio was 1.0, and the block_hash for each share was unique. This indicates high-frequency submissions of distinct nonces rather than an expired replay of a single job.
2. F2Pool VarDiff (Isolated to this connection)
Overly dense submissions triggered VarDiff, driving the pool_difficulty of .1 up from 4,194,304 (2²²) to between 268 million and 537 million (2²⁸ to 2²⁹). During the same period, the pool_diff for rig1 and rig05 under the same hotkey remained at 4,194,304. This demonstrates that VarDiff is applied per F2Pool worker connection, rather than being a global adjustment for the hotkey or the entire pool.
3. Why h60 was Artificially Inflated
Displayed Hashrate: h60 = sum(pool_difficulty) × 65536 / 3600.
After VarDiff spiked the pool_difficulty, a large volume of accepted shares accumulated based on this high difficulty, inflating h60 to ~41,930 GH. The actual_difficulty for individual shares remained around 68–131, meaning it did not represent a genuine 42 TH/s physical hashrate.
4. Reward Metric (share_value)
LTC/DOGE payout distribution utilizes share_value = sum(actual_difficulty), independent of h60 or pool_difficulty. Although the share_value rose due to the surge in accepted shares—causing that day's reward allocation percentage to be temporarily higher—it was not amplified millions of times by the pool_diff. Payouts were still calculated strictly by accumulating the actual_difficulty of the accepted shares.
130
Dogelayer|SN80 retweeted

Jun 2
Tao Wallet is now on Android.
More people on-chain.
More access to $TAO.
More ways into the subnet economy.
Download Today.
8
48
180
24,195
Jun 4
The hash rate is back.
3
478
Dogelayer|SN80 retweeted

Jun 3
"If you are a company, why should you do a subnet? Why not just raise from a VC or hire people?"
Jacob Steeves @const_reborn, co-founder of @bittensor, just answered that live on the Proof of Talk stage.
Decentralising Intelligence: The Unification of AI and Bitcoin. What happens when the two largest open networks in computing share the same architectural future.
Powered by @ExploitSummit.
Watch on Proof of Talk X: x.com/i/broadcasts/1DxLddEgz…
7
60
274
26,254
Dogelayer|SN80 retweeted

Jun 3
Don't sleep on Bittensor $TAO. Big things happening
Jun 3

I've been digging into the @MacrocosmosAI @IOTA_SN9 100B parameter pretraining run to understand what it is (or isn't) and potential implications.
My honest assessment below in case its helpful for others:
73
179
1,062
92,447
Dogelayer|SN80 retweeted

Jun 2
Apparently no one saved me a seat. Packed at @proofoftalk! 😁
$TAO rooms overflowing again.

10
28
239
25,578
Dogelayer|SN80 retweeted

May 31
NEWS: @opentensor & @Tangem team up on a limited edition Bittensor wallet for cold $TAO storage.
Pre-order now at bittensor.tangem.com
7
26
137
6,154