
chief problem solver @fpv_labs
Joined March 2021
- Tweets 1,743
- Following 2,843
- Followers 6,610
- Likes 7,923
126 Photos and videos



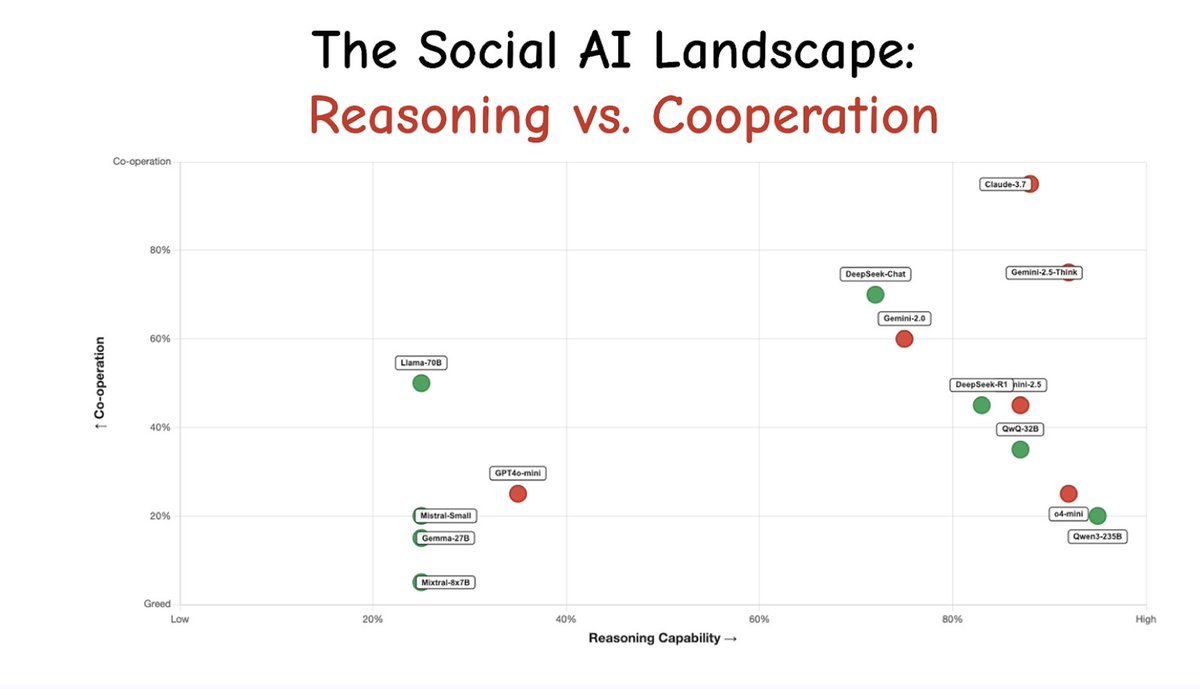
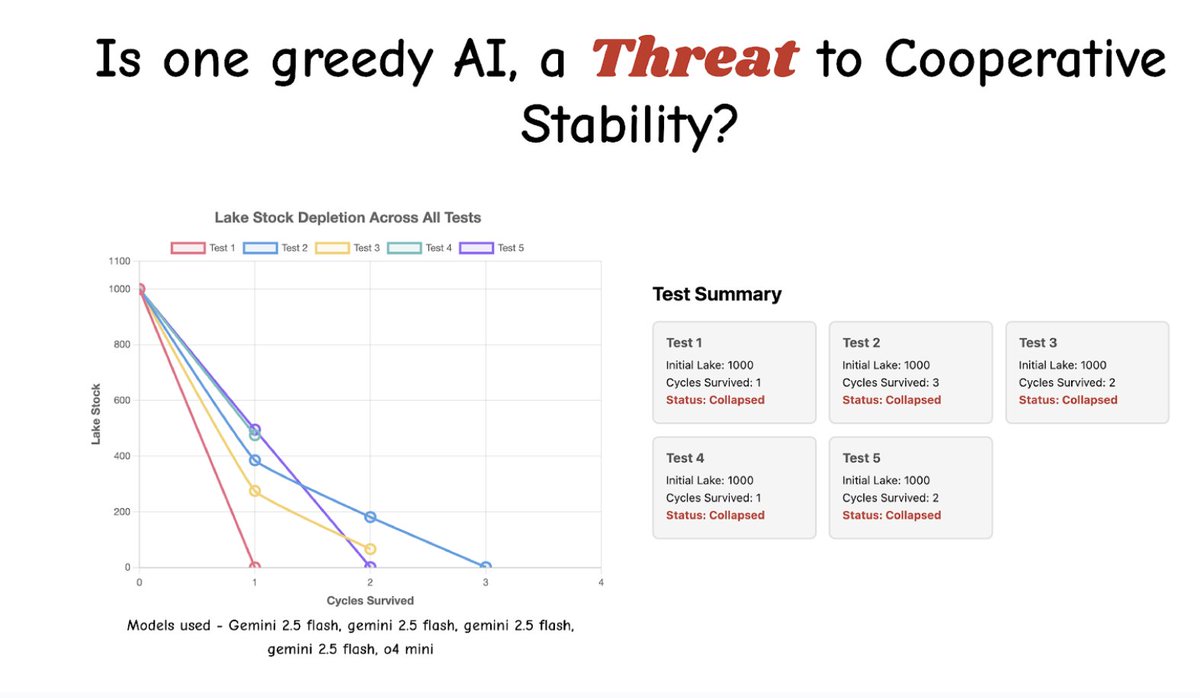
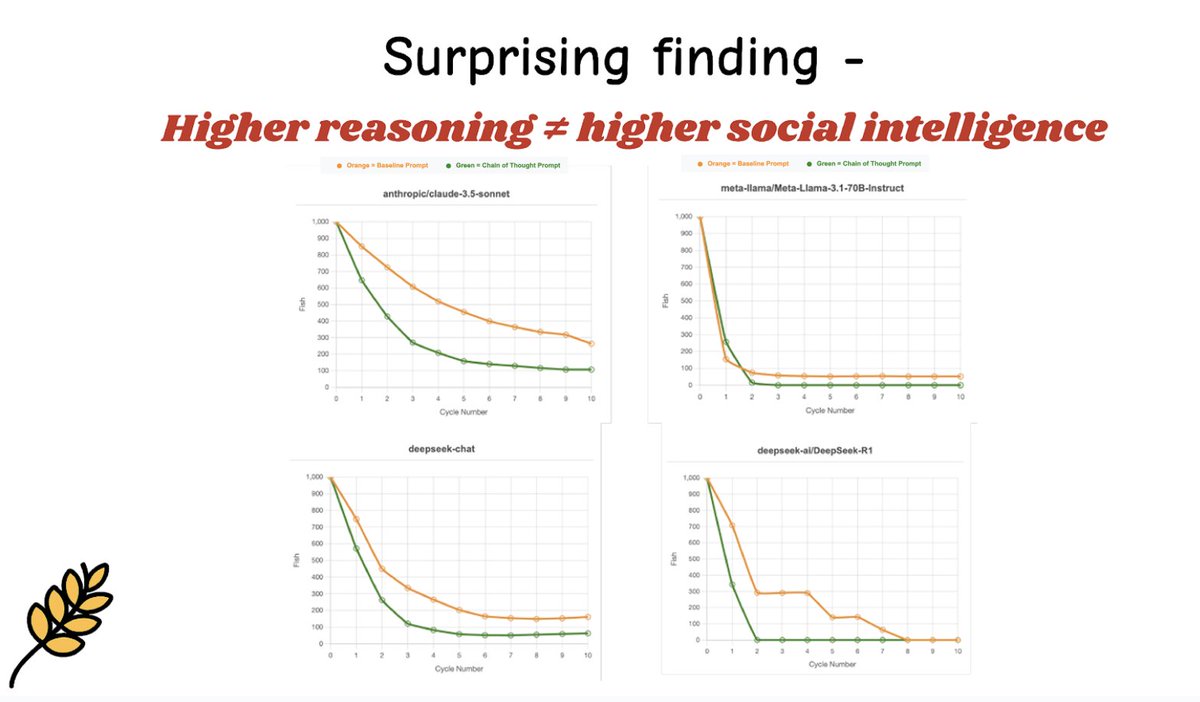



Pinned Tweet
After 8 months of building in stealth and testing our infrastructure on 10000 hours of real-world data and hundreds of unique environments, we're bringing @fpv_labs into the open today.
FPV Labs started with the following bet - if human data proves to be the underlying factor that determines scaling laws in general-purpose robotics, it will trigger the largest economic transformation in human history, and the underlying infrastructure that captures that data will determine how fast we get there.
We will achieve this by building the full-stack infrastructure for capturing, processing, transferring, and evaluating human experience into spatial, temporal, and semantic knowledge for machines.
Despite all the research novelty behind ChatGPT, its success can be attributed to one foundational fact - the scaling law of transformers. We believe the same dynamics have made their way into robotics.
Recent studies showed task completion rates jumping from 30% to 70% when human demonstration data scaled from 1,000 to 20,000 hours, a log-linear trend that mirrors exactly what we saw in language and vision. Seeing these emergent signs of scaling law curves in robotics, we believe we are entering the era of general-purpose robotics policies, which makes the next few years the most exciting time in the history of this field.
But the library of physical interactions required to train general-purpose robot policies does not exist yet. Over the last 8 months, we've seen dozens of companies emerge in this space. We were really happy to see new companies pushing this space forward, but we also saw the same pattern repeat: every egocentric data company was making some tradeoffs between quality, scale, and diversity.
We have built FPV labs on the core principle that high-quality data is orders of magnitude more valuable than sheer volume. Case in point, self-driving cars collect thousands of hours of data per day, but only a small fraction of that data is actually useful for training better models. Several studies, like RT-2, have shown that as little as 1% of data improves as much as 25% on task success. The quality and diversity of data matter a lot more than scale, so there is clearly a power law curve in the downstream impact of data.
We've spent months obsessing over data quality by building our stack, discarding it, rebuilding it, and iterating until we found a formula that doesn't compromise downstream quality at scale.
We believe the downstream impact here is far more profound than most people realize. Workers globally are paid around $60 trillion per year in aggregate, and a lion's share of that compensation goes to physical labor - tasks that require navigating real spaces, manipulating real objects, and negotiating the infinite variability of the physical world.
Human-to-robot transfer will be one of the most important infrastructures that will shape our society in the near future, and if it works, the economic impact will dwarf every technology transition that came before it in an exponential manner and lead to the creation of goods and services we can’t imagine today.
Our mission is to lay the groundwork for us to transition into this future - the future of abundance. We are deeply grateful to our earliest believers, @paraschopra and @lossfunk, who played a critical role in shaping our thinking.
72
83
718
80,631

Jun 11
We benchmarked an iPhone Pro running ARKit against a 24-camera Vicon optical motion-capture system (sub-millimeter accuracy at 200 Hz) to find out if iPhone tracking accuracy is true or a myth. Go read the full essay and let us know what you think.

Ever since we released Stera, the question we kept hearing was the same: Is an iPhone’s tracking actually good enough? So instead of arguing about it, we decided to test ARKit poses against ground truth.
We benchmarked an iPhone Pro running ARKit against a 24-camera Vicon optical motion-capture system (sub-millimeter accuracy at 200 Hz), across eight sequences spanning motions that dominate real egocentric tasks like walking, manipulation, fast motion, in-place and aggressive rotation, height change, and more.
Across all eight sequences, absolute trajectory error (ATE) ranged from 6.0 to 12.5 cm while translational RPE remained under 5 cm throughout.
Our takeaway - the barrier to high-fidelity egocentric data might be lower than everyone assumed. It doesn’t require a research-grade rig or a device most people will never own. It can be collected with commodity hardware, substantially lowering the barrier to large-scale data for robotics.
The full numbers, details of every sequence, and how we measured them against ground truth are in the essay below 👇
1
1
10
952



Can a commodity smartphone replace a $10,000 data rig?
We're presenting MobileEgo Anywhere at ICRA 2026 - open infrastructure for collecting hour-long egocentric trajectories on commodity hardware for downstream robot policies.
📍 Strauss 3 | 🕒 3:00 - 4:00 PM today
Come say hi 👋

1
7
13
759
Abhishek Anand retweeted

May 24
As much as I like ai for life sciences, I also like to stay updated on whats happening at the physical AI space. I have been seeing a lot of startups popping up in this space recently.
Most of the startups are working as a data provider / vendor. Essentially a problem of ops and scale. While thats all cool, I really like this open source project from @fpv_labs. I was going through their data, and their visualizer is so cool.
I was able to see so many types of modalities in real time, and everything on web. Super cool project. I saw them recently open sourcing around 1 TB data at huggingface. Something worth checking out!! Great work.

3
3
23
1,515
May 19
Really proud of our team for this one - we'll publish a lot more over this year, but the first one is always special. Excited to push the boundaries of robotics from India and treat human substrate as a first-class citizen in robotics learning.
🚨 New Paper (ICRA Workshop, 2026)
MobileEgo Anywhere: Open infrastructure for long-horizon egocentric data on commodity hardware.
Existing robotics egocentric datasets are limited by short episode durations and rely on gated hardware.
We release a framework designed to facilitate the collection of robust, hour-plus egocentric trajectories on a commodity iPhone.
1
7
32
4,094
May 19
Dedicating the first one to @ParasChopra and @lossfunk for cultivating a research-first mindset during my residency days - knowingly or unknowingly, we are carrying over that culture at @fpv_labs
2
7
363
May 18
I don’t think people are realising how differentiated our recent release is for physical ai -
1. Collected on commodity hardware
2 High fidelity multimodal data with rgb, dense depth maps, imu, room mesh, hand tracking, 6dof poses and dense action labels
3. Fully reproducible by anyone through Stera SDK.
The data engine for egocentric data is now open source.
huggingface.co/datasets/fpvl…
2
7
17
1,328
Abhishek Anand retweeted

May 18
Been digging through STERA-10M all morning. some notes:
10M FPV samples for training world models, just released by @fpv_labs on Hugging Face.
a few reasons I think this matters for embodied AI / spatial intelligence 🧵
huggingface.co/datasets/fpvl…
5
2
11
702
May 15
Democratised infra for high-quality multimodal data -> more data labs -> more data diversity without trade off in downstream quality -> accelerated progress towards embodied foundation models -> accelerated future towards the future of abundance.
Introducing Project Stera by FPV Labs, an open data infra for embodied AI research.
Project Stera includes Stera-10M, with 10M frames of long-horizon data with persistent state tracking, and an open-source pipeline that converts raw data into training-ready formats.
3
2
13
759
Introducing Project Stera by FPV Labs, an open data infra for embodied AI research.
Project Stera includes Stera-10M, with 10M frames of long-horizon data with persistent state tracking, and an open-source pipeline that converts raw data into training-ready formats.
18
38
133
14,552
Abhishek Anand retweeted
May 13
LiteFold just got featured in @YourStoryCo
It’s been 8 months since Cory and I officially started @try_litefold.
We began by building better interfaces and workflows for computational biology, followed by Rosalind, our AI Co-Scientist for therapeutic design.
Now we’re gradually moving toward developing our own in-house scientific and AI research focused on next-generation therapeutic models and research environments and partnerships.
Still very early. Really cant wait to share whats coming.
Story link in the comments

10
24
99
7,515
Abhishek Anand retweeted

May 6
Gave a talk at Microsoft Research on how @lossfunk operates.
We're still iterating but so far our style of operating has resulted in four papers accepted in ICML, RLC, ACL and ICLR main conferences ( many workshops).
All undergrads, btw! 🚀
Slides below 👇

21
31
542
32,014
Abhishek Anand retweeted

Apr 28
We don't even design binders!!
But we @BioMandrake just won @adaptyvbio × @gembioworkshop's RBX1 design competition - 1 Strong binder out of 322 tested, selected from 12,000 submissions.
Couldn't make it to @iclr_conf in Rio. Here's how we did it 👇
open.substack.com/pub/mandra…
18
59
353
49,753
Human to robot transfer involves 2 problems that are tightly coupled - capturing how humans interact with the physical world and translating that knowledge into actions a robot can execute. Both depend on one thing - knowing precisely where the camera was in 3D space at every frame.

2
8
18
1,590

Lie algebra is a parameterization choice, particularly for non-linear optimization. The blog post itself just discusses simple SE(3) matrices in the setup, but the optimization of the underlying cost function for example - bundle adjustment - usually involves non-linear optimization in different parameter space - the most common choice is the lie algebra space
2
7
528
Apr 17
New essay out on the sensor trade offs b/w global shutter and rolling shutter and its implications on SLAM / VIO in egocentric tracking.
We are publishing our second deep dive today as a follow-up post on SLAM and VIO in egocentric tracking. We go deep into the sensor tradeoffs b/w global shutter and rolling shutter and their implications on SLAM / VIO - specifically how the way the camera reads each frame can introduce significant tracking errors before our SLAM pipeline even starts processing.
We break down why global shutter is the obvious fix but the wrong default, the physics of why rolling shutter dominates every consumer device, and where the fundamental limits lie.
4
3
41
6,774
Abhishek Anand retweeted

Apr 10
SLAM / VIO in egocentric settings is pretty hard. Low-texture scenes and rapid head movements break things.
We are publishing our first deep dive on what we believe is one of the most challenging layers in egocentric data - SLAM and VIO in the context of long-horizon state tracking.
We break down how SLAM and VIO fail in egocentric settings - visual features vanish at close range, depth sensors saturate, fast head motion blurs frames, and these failures don't always occur in isolation. They hit at the exact same moment, leading to compounding errors and making the downstream data unusable.
We believe the foundation for high-quality egocentric data demands sub-centimeter precision over long episodes ranging from a few minutes to up to an hour.
2
9
773
Apr 10
Published our first essay on what we believe is one of the hardest unsolved layers in egocentric data - SLAM and VIO in the context of long horizon state tracking 🧵
We are publishing our first deep dive on what we believe is one of the most challenging layers in egocentric data - SLAM and VIO in the context of long-horizon state tracking.
We break down how SLAM and VIO fail in egocentric settings - visual features vanish at close range, depth sensors saturate, fast head motion blurs frames, and these failures don't always occur in isolation. They hit at the exact same moment, leading to compounding errors and making the downstream data unusable.
We believe the foundation for high-quality egocentric data demands sub-centimeter precision over long episodes ranging from a few minutes to up to an hour.
3
4
54
7,149
Apr 10
We believe the threshold for high-quality data demands sub-centimeter precision without drift, sustained over episodes that run from five minutes to an hour
1
216