
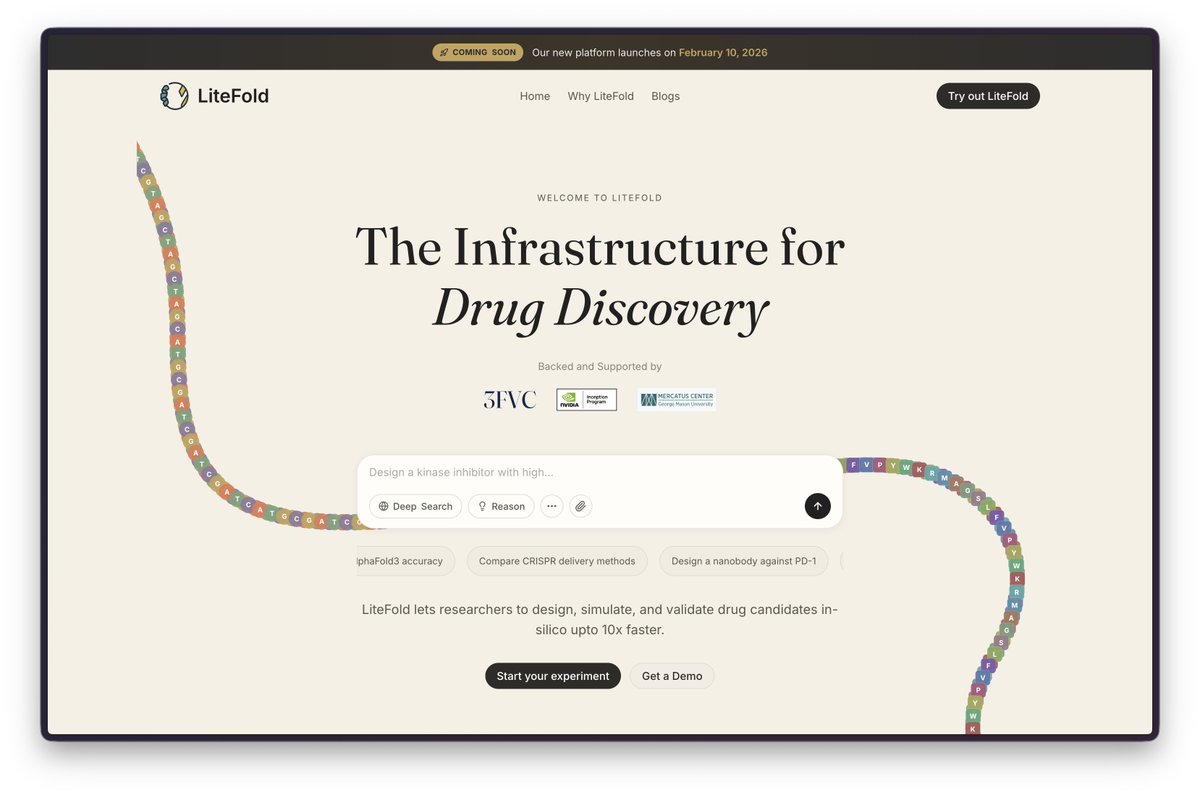
The infrastructure for Drug Discovery. We are here to make AI for Science more accessible.
Joined December 2024
- Tweets 293
- Following 11
- Followers 2,364
- Likes 574
42 Photos and videos





Pinned Tweet

Feb 15
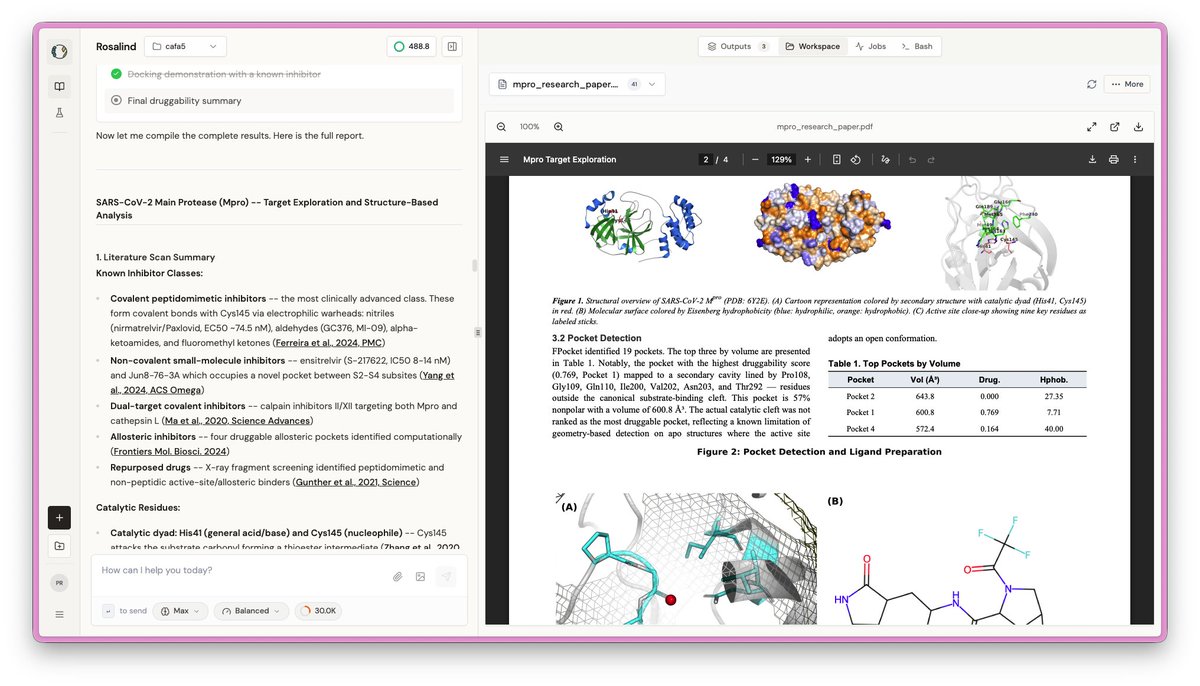
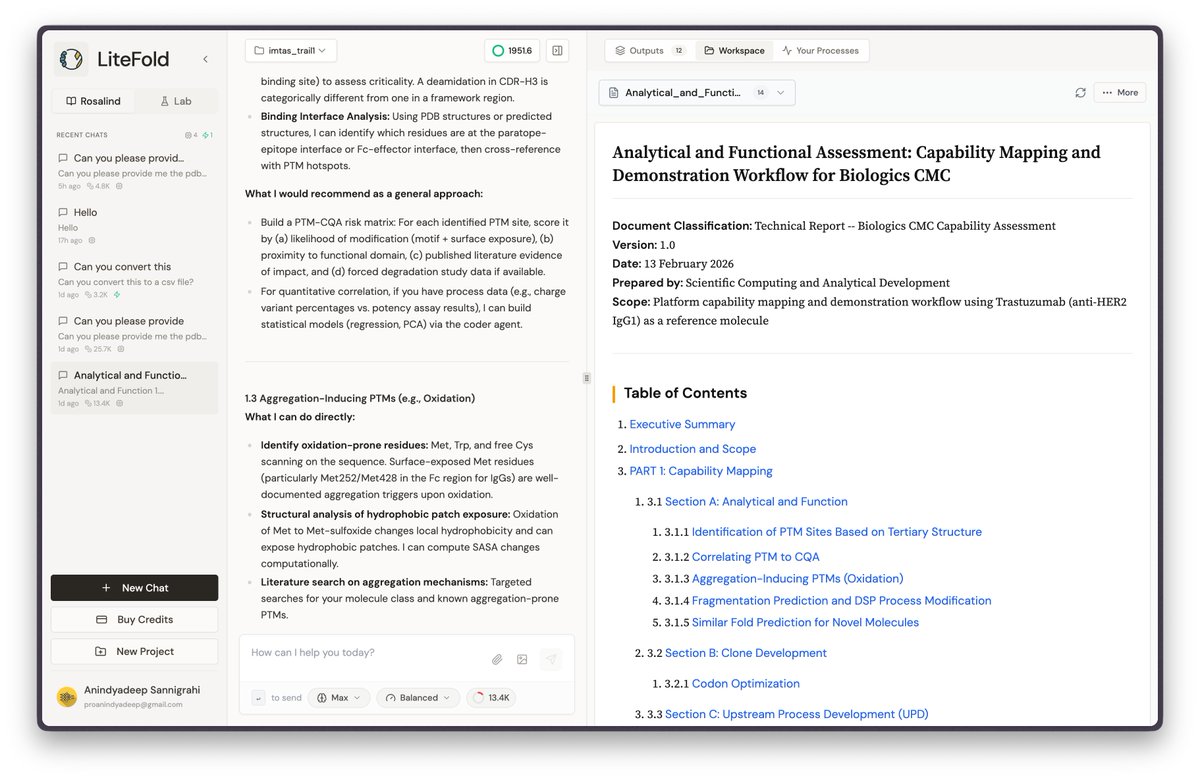
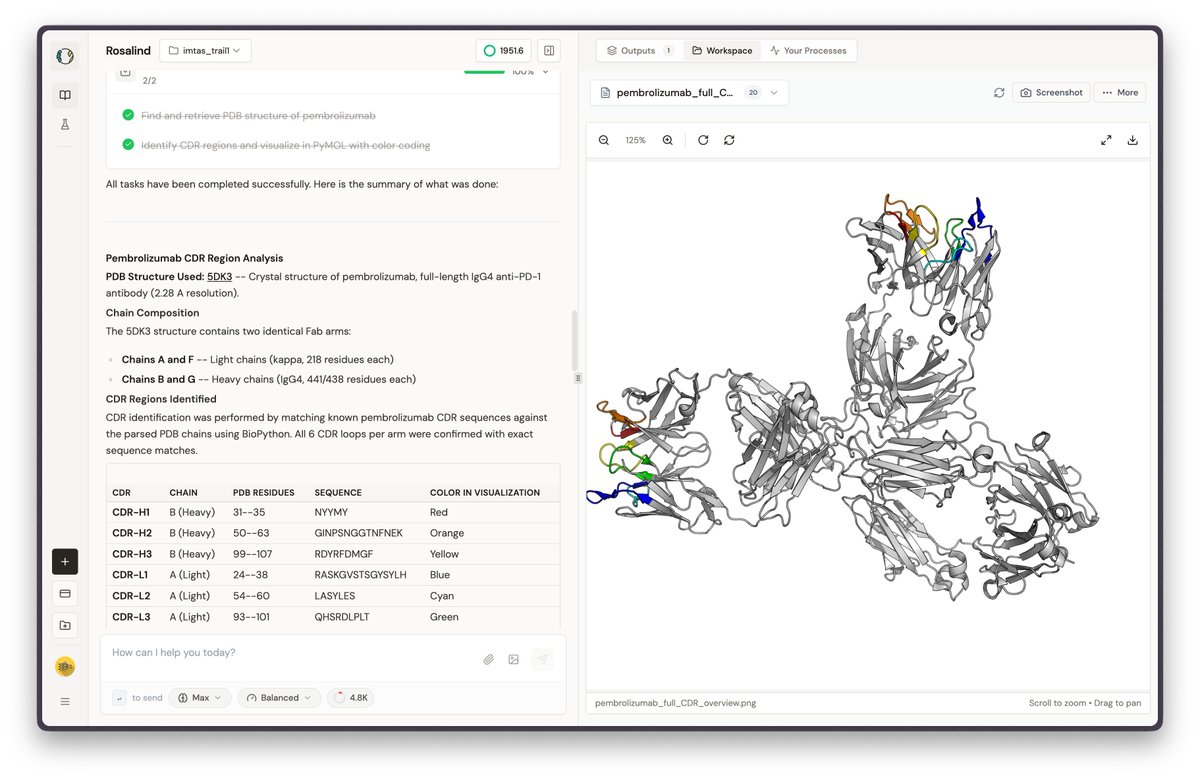
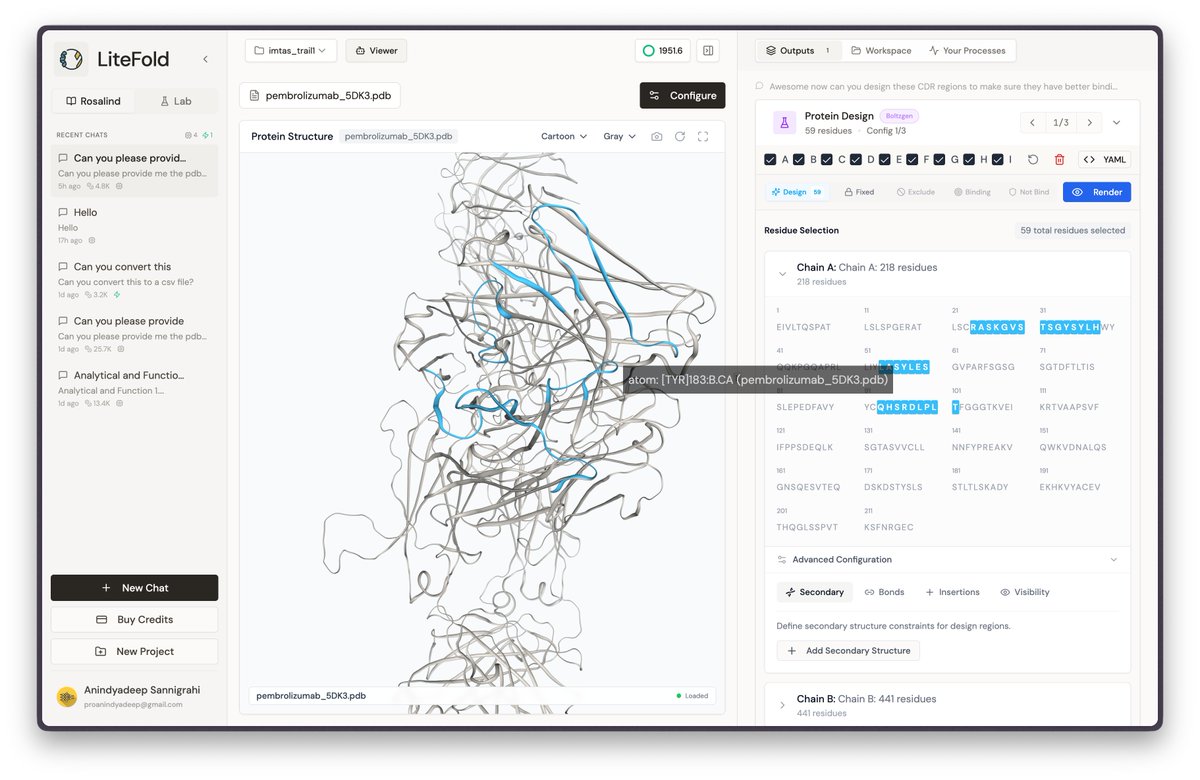
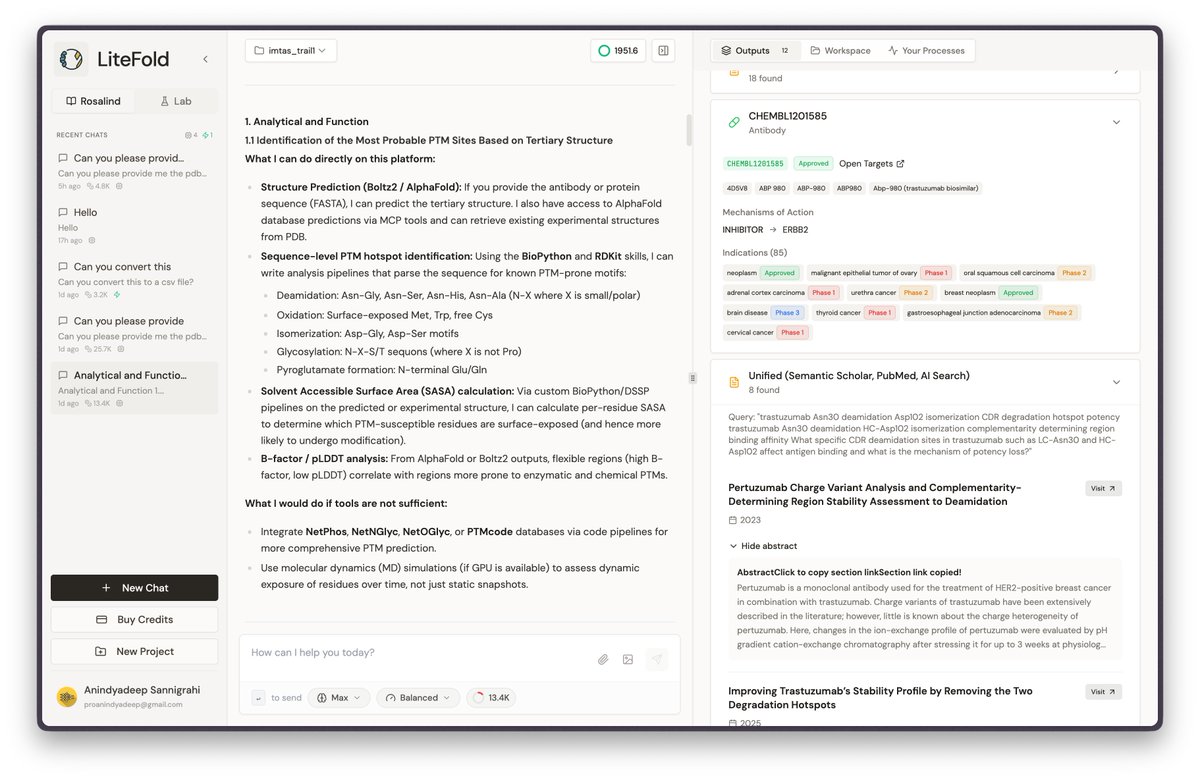
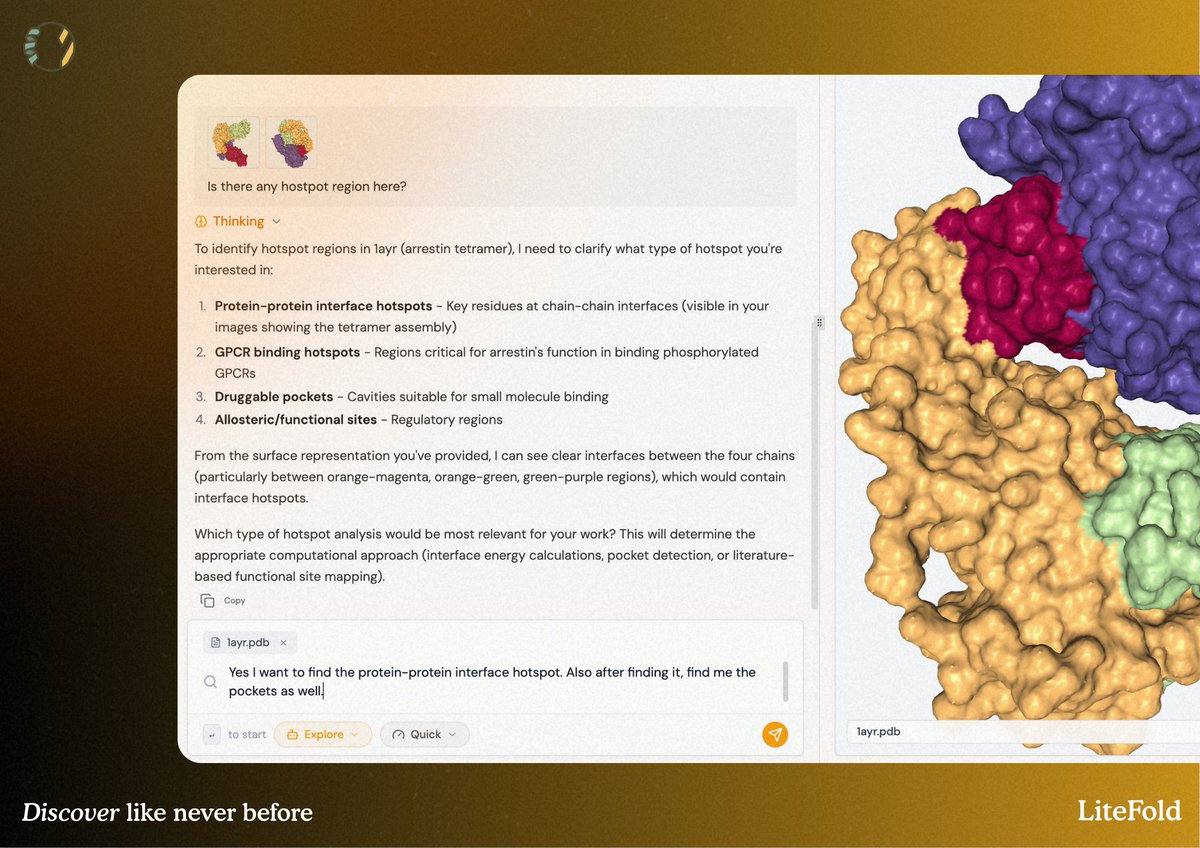
Announcing Rosalind, the most versatile AI Co-Scientist for computational biology and therapeutics research. Giving every biologist their own frontier research lab. Make every experiment count. It's live. Links in the comments.
25
83
681
58,964
LiteFold retweeted

Jun 13
Meet the members of Proxima:
Anindyadeep (@anindyadeeps) is building Litefold. LiteFold combines physics-based simulation and AI to accelerate the design and validation of drug candidates in silico.
Their leading product is Rosalind: An AI Co-Scientist for Life Sciences.


4
8
50
4,551
LiteFold retweeted

Jun 1
> Three 30 ns MD runs of human β2AR, in parallel, from a browser
> Apo in water, carazolol-bound, and embedded in a POPC bilayer
> Finished in an afternoon on cloud GPUs.
> No CHARMM-GUI session, No terminal, no topology debugging, no queue.
> Life is good!
Focus on the Science, we take care of the rest. Links in the comments.
Jun 1

We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in comments.
3
6
27
5,204
LiteFold retweeted
Jun 1
We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in comments.
2
4
16
6,339
Jun 1
We ran β2AR three ways: bare, with carazolol bound, and in a lipid bilayer. Carazolol sits in the extracellular pocket, but the RMSF drop shows up at the cytoplasmic end of TM6.Inverse agonism as distal dampening, visible in 30 ns of MD. Read more in the blogpost. Links in comments.
2
4
16
6,339
LiteFold retweeted
May 30
We at almost 50K downloads in 3 days niceee!!! Would love to see what the community is building. Meanwhile stay tuned for some more surprising coming. Currently cooking!!!
May 27

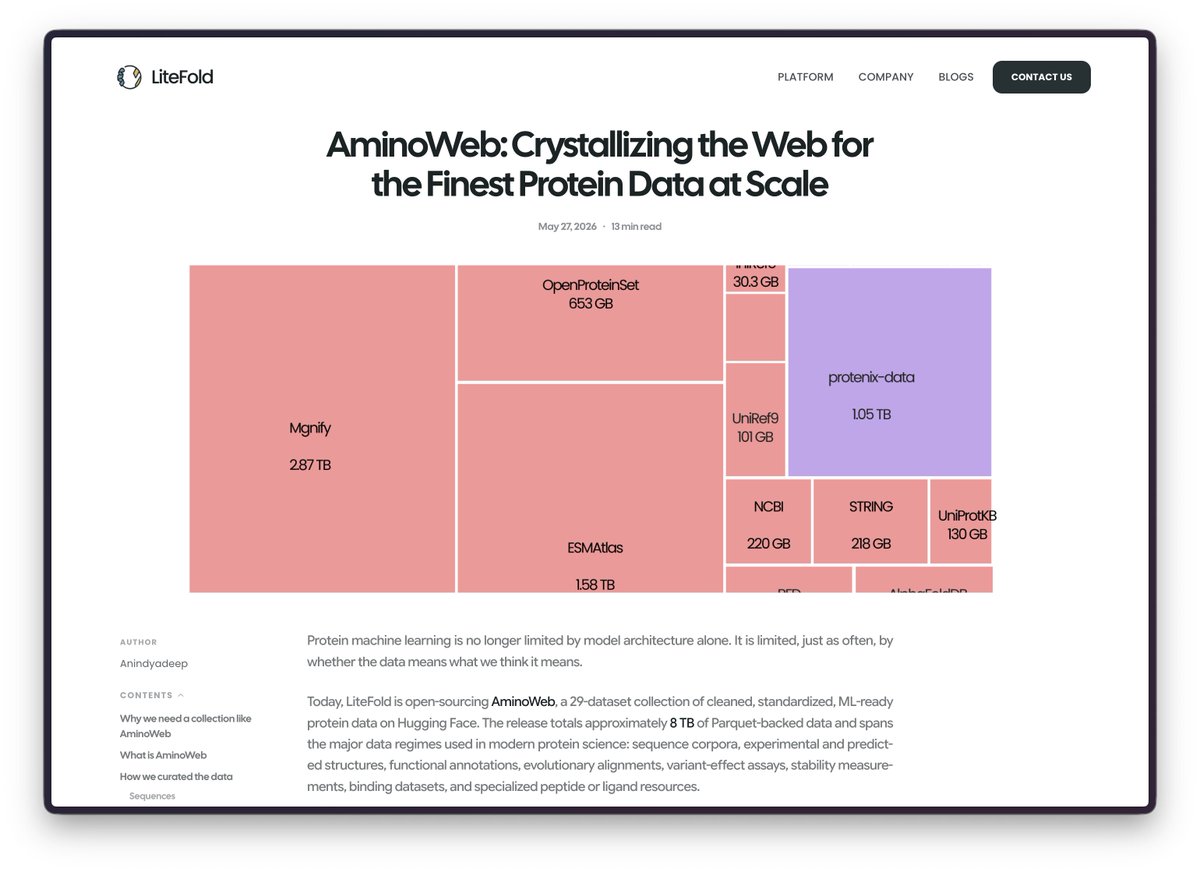
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
11
7
80
7,184
LiteFold retweeted
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
May 27
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
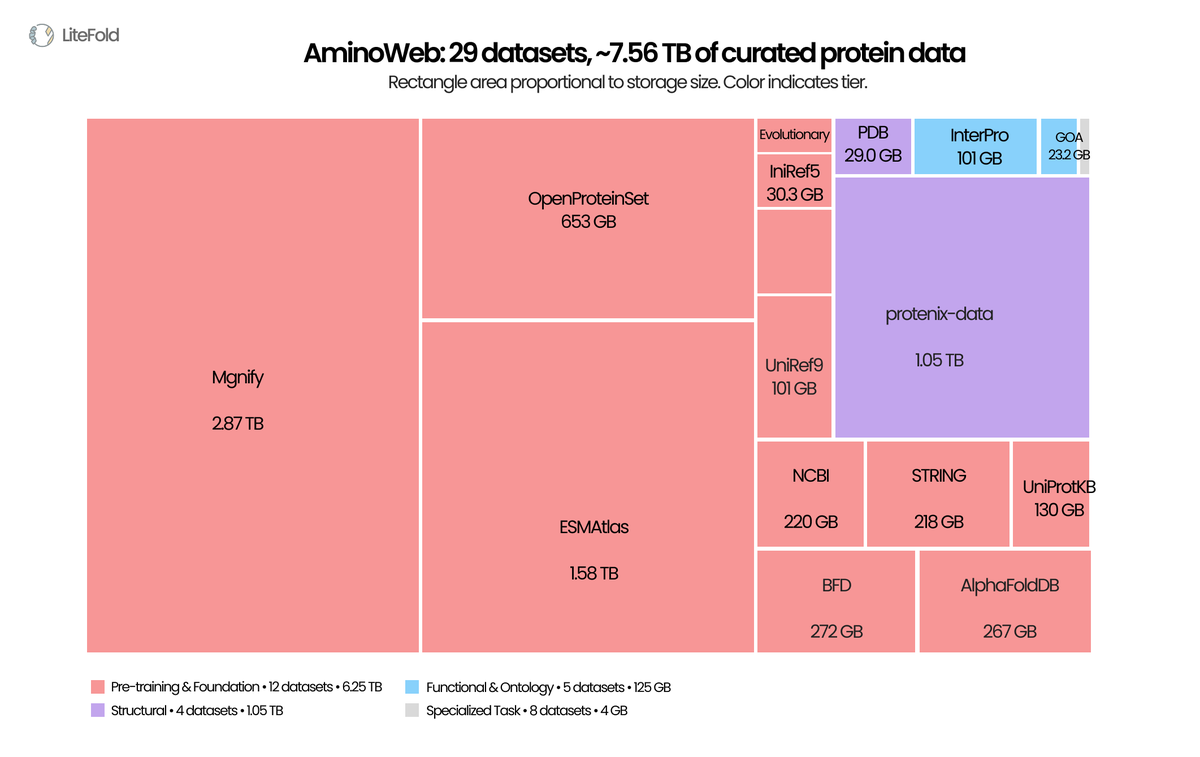
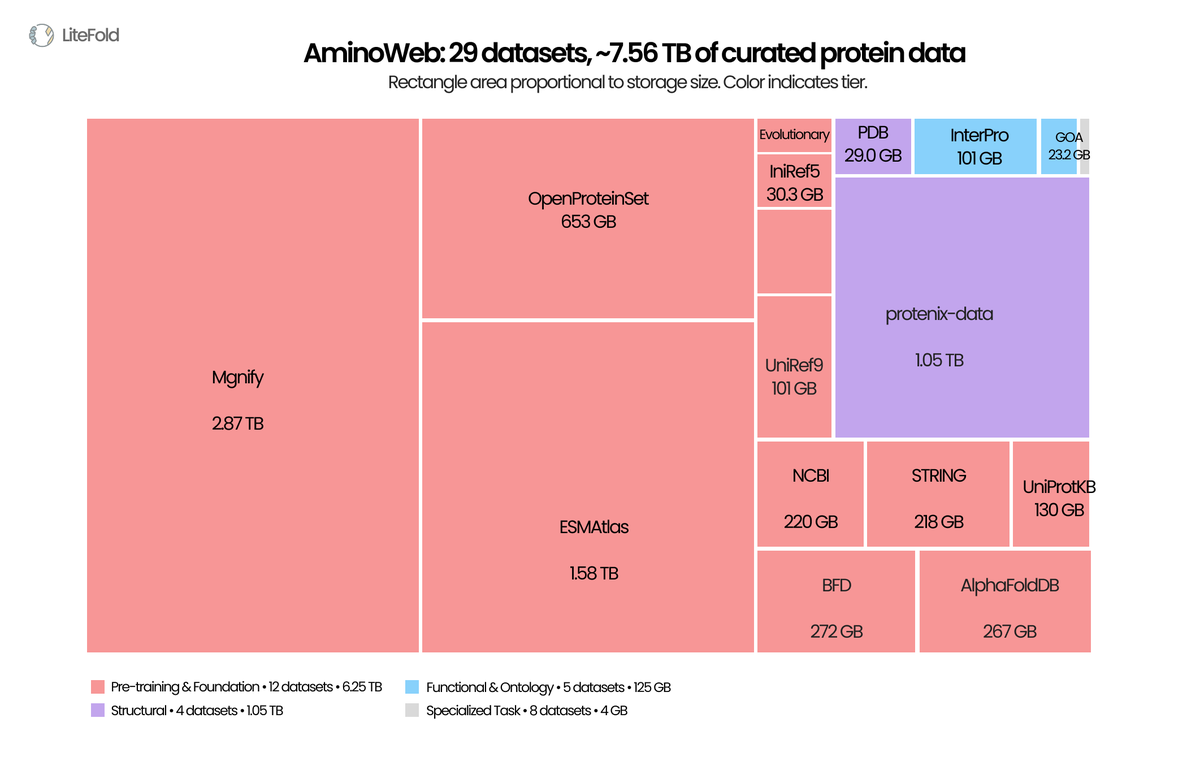
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
38
71
360
87,771
LiteFold retweeted

The open-source protein ML space just got a massive upgrade. Phenomenal work by @anindyadeeps and @try_litefold on dropping the biggest protein data collection on Hugging Face
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
1
5
10
2,018
LiteFold retweeted
May 28
Well, it the dataset was a nice success, now lets go one step up, and evaluate things (with some new evaluations)!! Coming Soon

May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
1
4
41
1,935
LiteFold retweeted

May 28
So proud of young Indian entrepreneurs who are doing such great work
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
1
2
16
1,188
LiteFold retweeted

May 27
@anindyadeeps my man breaking records !!
May 27
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
2
8
790
LiteFold retweeted

May 27
8TB of protein data opensourced !!
@anindyadeeps the dennis hassabis of Blr
@juscallmevyom the goat
May 27
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
2
11
1,092
LiteFold retweeted

May 28
Absolute massive protein dataset, great stuff from @try_litefold
May 27
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
1
1
13
1,868
LiteFold retweeted

The open source has tackled the closed source by an unimaginable margin. Great job @try_litefold @anindyadeeps
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
2
6
1,064
LiteFold retweeted

May 27
Bro casually dropped the biggest Protein dataset on @huggingface
check it out guys !!
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
1
12
164
28,554
LiteFold retweeted

May 27
today was a massive day for protein engineering.
esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein complexes, including antibody–antigen binding.
alongside it: the new esm atlas. a huge expansion of known protein space, heavy on metagenomic sequences from soil, ocean, and the parts of biology that have been least characterised (until now!!)
and if that weren't enough, litefold dropped the fineweb of proteins, so every major protein database (pdb included) aggregated, cleaned, and made plug-and-play in one place.
these are the releases that push the whole field forward, and the pace of open science right now is almost motion-sickness inducing
all of it on huggingscience.co (and ofc @huggingface)
9
75
347
36,066
LiteFold retweeted
May 27
Today was indeed an awesome day for protein engineering!! Well guys this is just the start, now lets do some folding. Coming Soon
May 27

today was a massive day for protein engineering.
esmfold2 dropped—next gen of the esm series, fully open on @huggingscience. 1.1 billion predicted structures, 6.8 billion sequences. 800m more entries than the alphafold db, and reportedly edging out alphafold3 on protein complexes, including antibody–antigen binding.
alongside it: the new esm atlas. a huge expansion of known protein space, heavy on metagenomic sequences from soil, ocean, and the parts of biology that have been least characterised (until now!!)
and if that weren't enough, litefold dropped the fineweb of proteins, so every major protein database (pdb included) aggregated, cleaned, and made plug-and-play in one place.
these are the releases that push the whole field forward, and the pace of open science right now is almost motion-sickness inducing
all of it on huggingscience.co (and ofc @huggingface)
1
4
49
3,875
LiteFold retweeted
May 27
A lot more things coming soon!!
May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
3
9
755
LiteFold retweeted
May 27
LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
11
32
143
46,368