
365 days of GPU programming ▓▓▓▓▓▓▓▓▓▓▓▓▓▓░░░░░░░░░░░░░░░░░░░░░░░ 161/365
Joined June 2025
- Tweets 505
- Following 661
- Followers 4,924
- Likes 2,857
200 Photos and videos











Pinned Tweet

Mar 27
Day 83/365 of GPU Programming
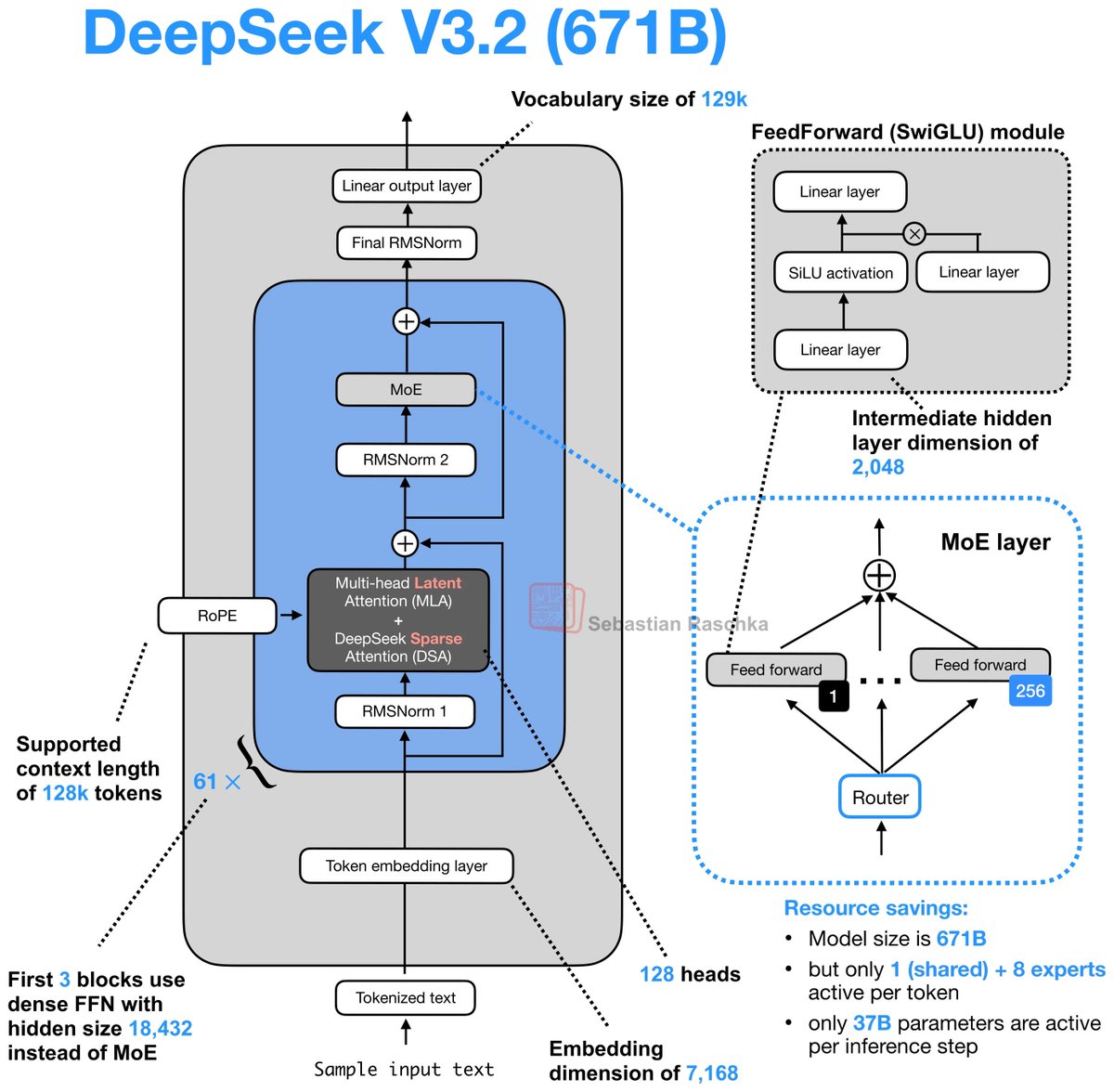
Looking at DeepSeek's Multi-Head Latent Attention today. The last part of the AMD challenge series is to optimize an MLA decode kernel for MI355X where the absorbed Q and compressed KV cache are given and your task is to do the attention computation.
A resource that really helped internalize what MLA does was @rasbt's incredible visual guide to attention variants in LLMs (luckily he posted that last week!), which covers everything from MHA to GQA to MLA to SWA, et cetera. If there's one place to get a visual intuition for recent attention mechanisms, it's this blog post.
@jbhuang0604's video on MQA, GQA,MLA and DSA was the best conceptual intro I found on the topic and progressively builds up the ideas from first principles.
The Welch Labs analysis of MLA is a great watch as well. Beautiful visualization of the changes DeepSeek made for MLA.
Tried out a few kernels once I had a basic understanding of MLA and I think I'm slowly getting more comfortable with at least analyzing kernels.



Mar 26

Day 82/365 of GPU Programming
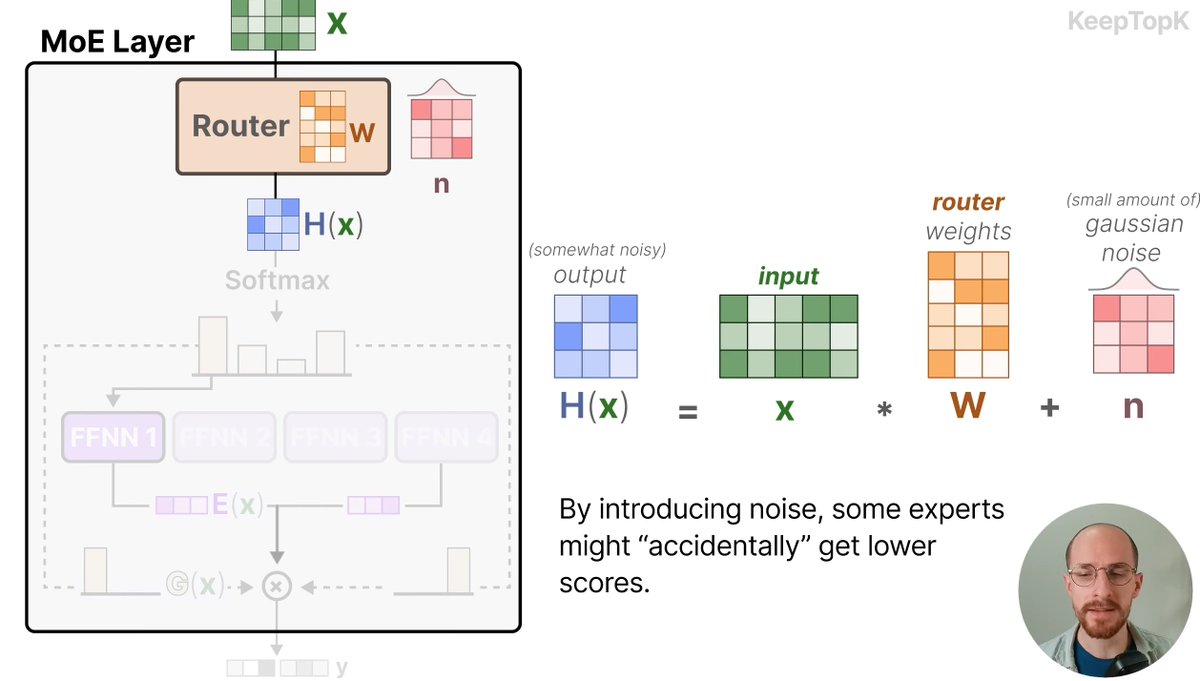
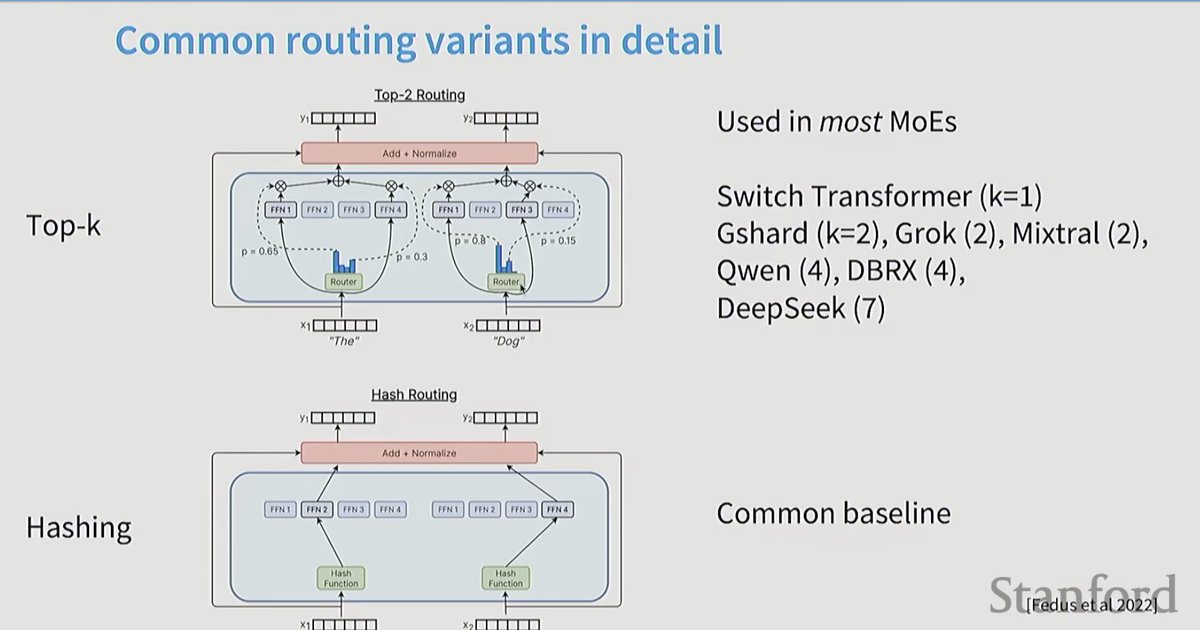
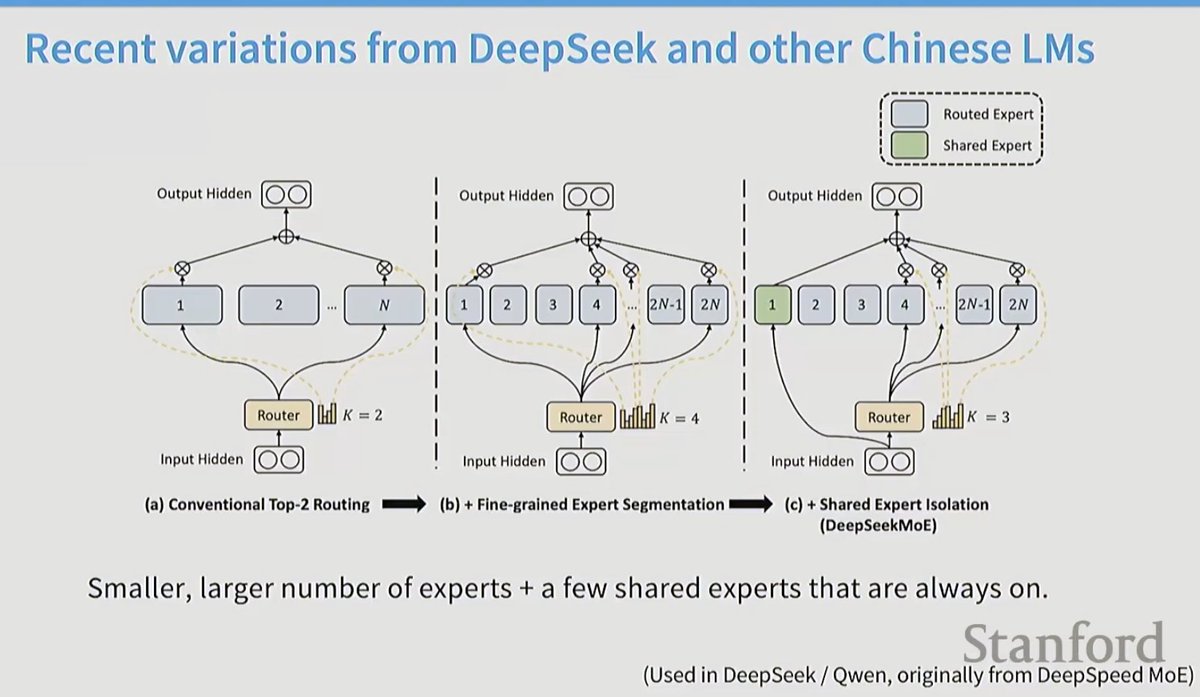
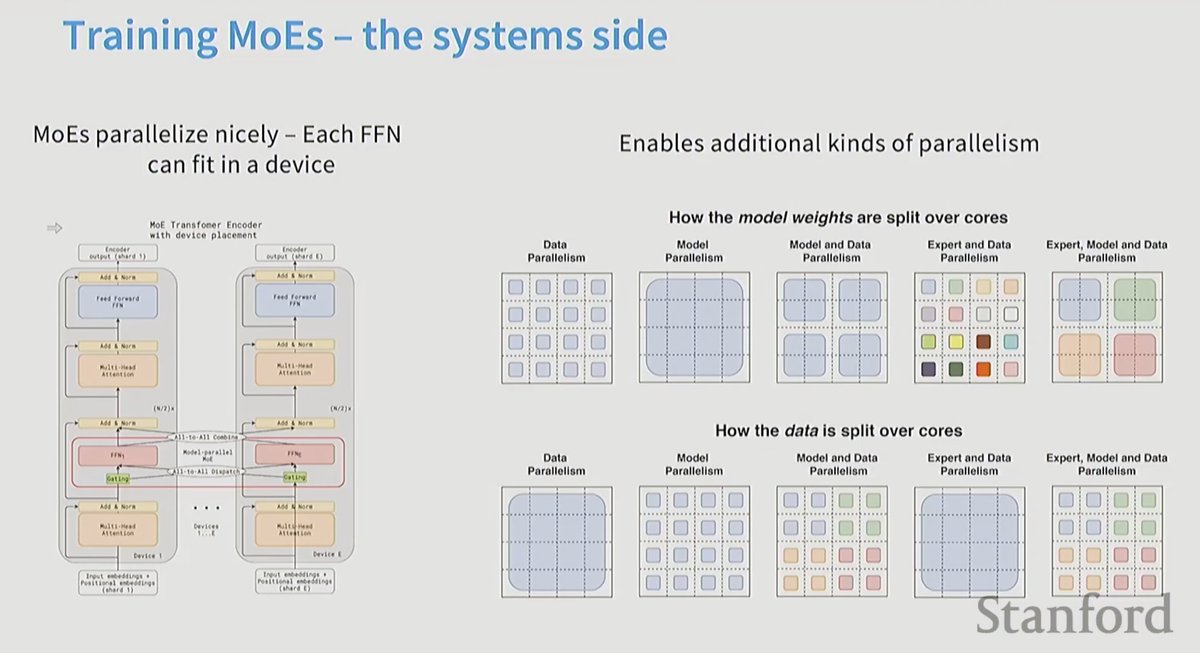
Taking a closer look at Mixture of Experts today, so I can write better MoE kernels. Specifically, to optimize an MXFP4 MoE fused kernel for the GPU Mode challenge.
I haven't had much prior exposure to MoEs, so lots of new concepts I learned today. Luckily I found the best intro to MoEs thanks to @MaartenGr visual overview of the topic.
I then watched @tatsu_hashimoto's amazing Stanford CS336 lecture on MoEs, which added deeper context around why MoEs are gaining popularity, FLOPs, OLMoE, infra complexity, routing functions (mindblown this works so well...), expert sizes, training objectives, top k routing and DeepSeek variations.
Once I had a basic understanding I started playing around with the some AITER kernels but progress there is tbd.
Also had a nice chat with @juscallmevyom (who was kind enough to reach out!) about the AMD kernels and the challenge of materialization overhead.
22
146
1,432
117,416
2h
162/365 of GPU Programming
Spending most of today reviewing the FP4 RaZeR and SMC-SD repos from yesterday as well as finalizing/submitting the camera ready version of my workshop paper.
Maybe obvious to other but as a research novice, I've mainly been trying to understand how to best incorporate feedback from reviewers into the revision and how to best utilize the additional page you get post-review.


22h
161/365 of GPU Programming
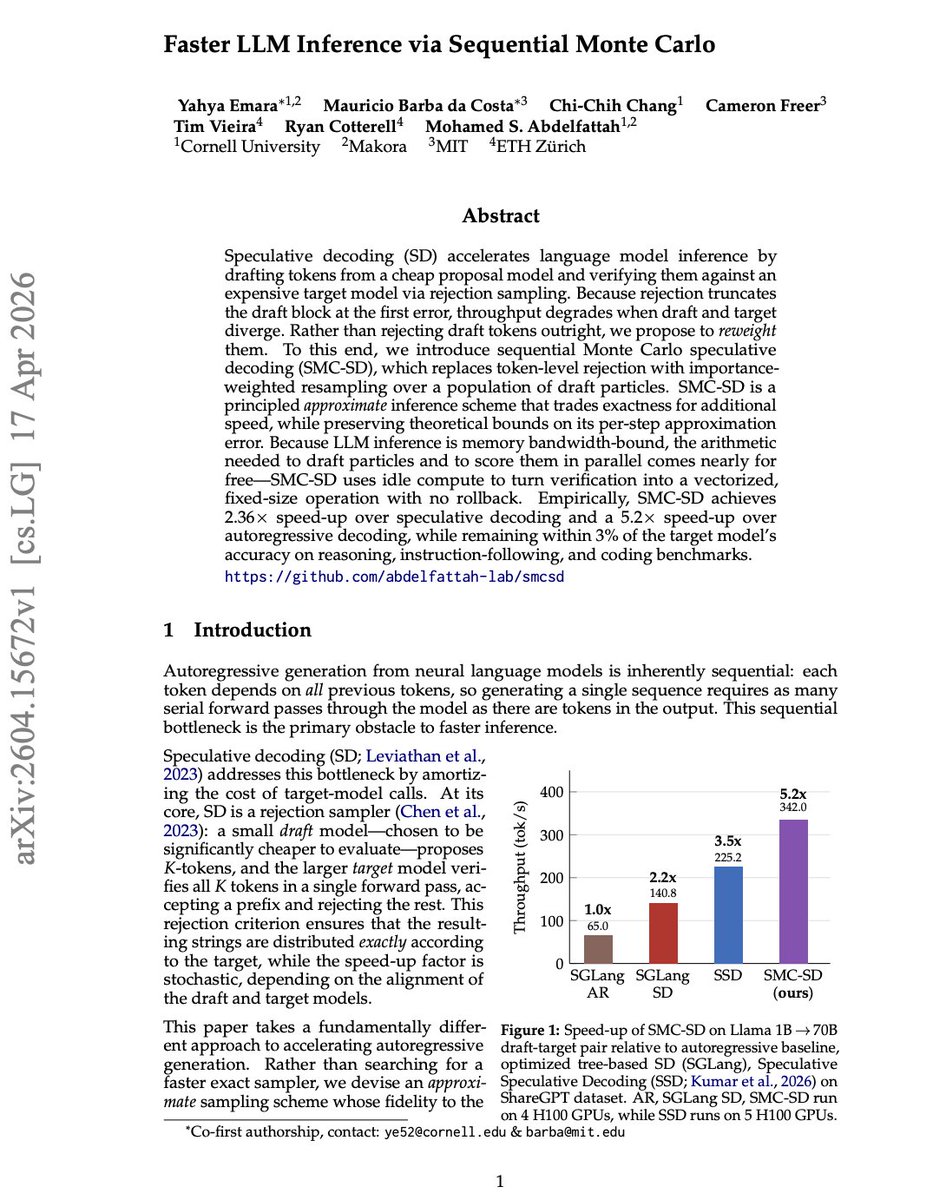
Was listening to an interview with @mohsaied (one of the co-founders of Makora) where he was walking through some of the things they're working on in the automated kernel generation space when he started explaining some current work on making NVFP4 more efficient by remapping redundant zeros and improving speculative decoding with sequential Monte Carlo.
Since I'm quite interested in FP4 at the moment and am increasingly looking at inference engineering, I'm gonna spend some time today reading through those research projects and their corresponding opensource code.


1
1
27
572
2h
- Link to RaZeR repo: github.com/abdelfattah-lab/N…
- Link to SMSCD repo: github.com/abdelfattah-lab/s…
3
70
22h
161/365 of GPU Programming
Was listening to an interview with @mohsaied (one of the co-founders of Makora) where he was walking through some of the things they're working on in the automated kernel generation space when he started explaining some current work on making NVFP4 more efficient by remapping redundant zeros and improving speculative decoding with sequential Monte Carlo.
Since I'm quite interested in FP4 at the moment and am increasingly looking at inference engineering, I'm gonna spend some time today reading through those research projects and their corresponding opensource code.
Jun 12
160/365 of GPU Programming
Taking a little break from studying FlashAttention to continue with CS336 today.
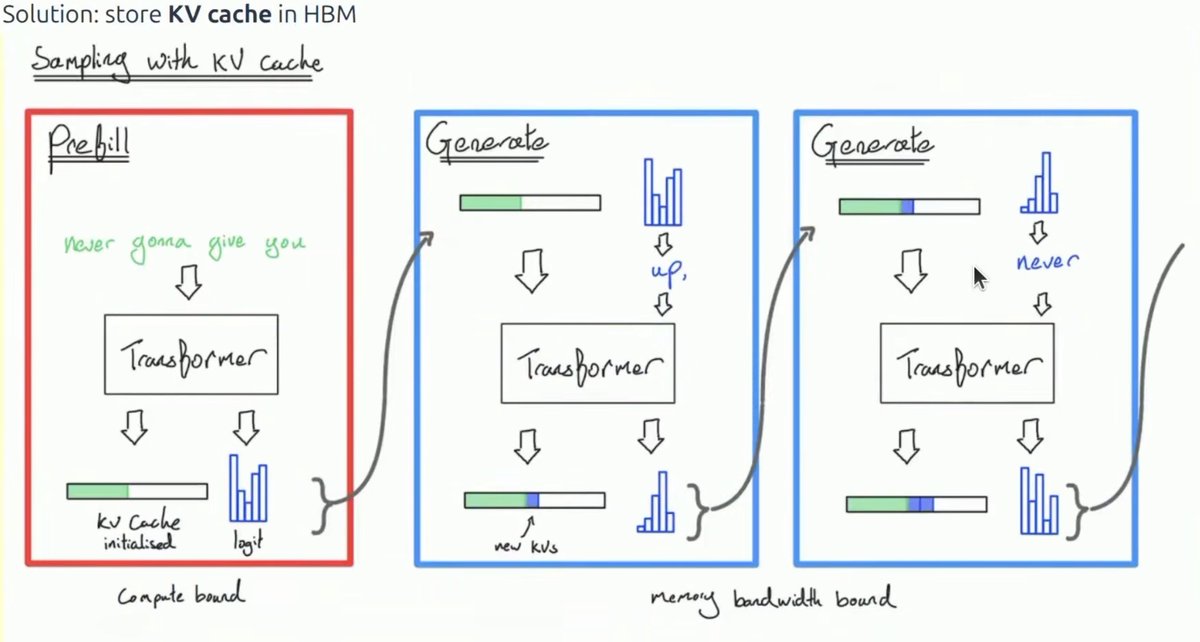
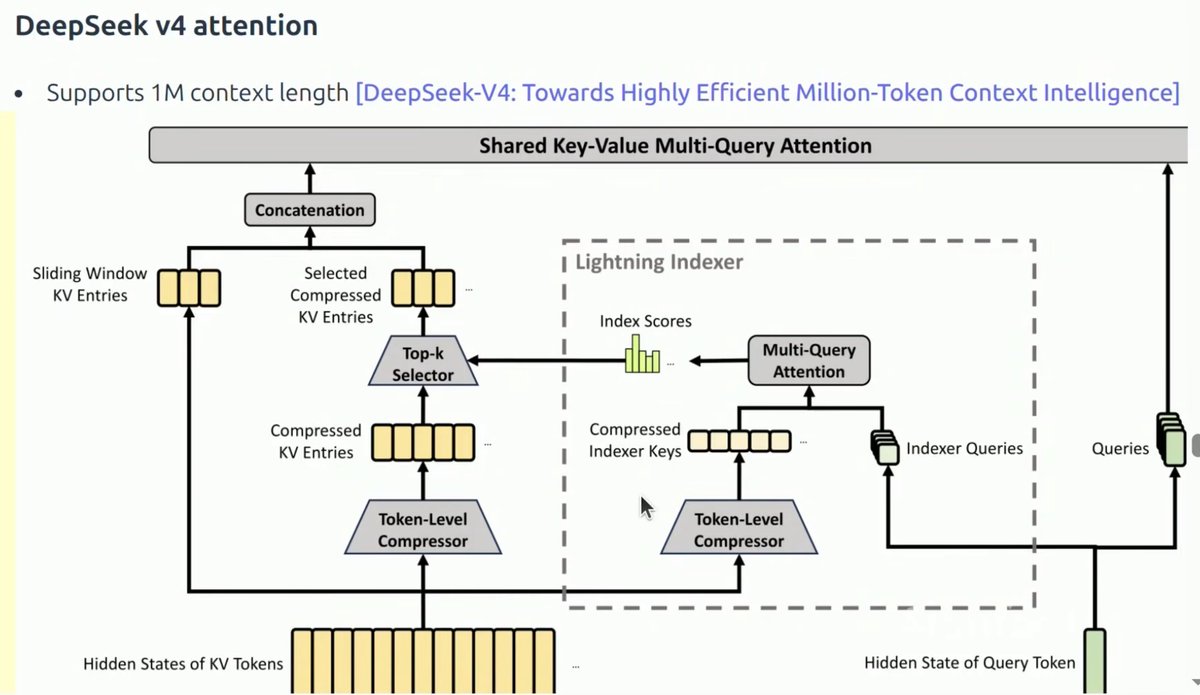
Lecture 10 is on inference and starts with a nice encapsulation of why inference is so important, continues on with what metrics matter in inference (TTFT, latency, throughput), then goes through how you can calculate arithmetic intensities for various operations before breaking down compute vs memory bound, KV cache, prefill vs decode, GQA, MLA, CSA, DSA, HCA, linear attention, QAT, PTQ, speculative decoding, continuous batching and paged attention.
Even if you're familiar with most of these concepts, it's a nice review of the inference stack and touches on some of the tradeoffs inherent in inference optimizations.

2
8
109
4,273
22h
- Link to interview: youtube.com/watch?v=ukzACWrk…
- Link to NVFP4 paper: arxiv.org/pdf/2501.04052
- Link to Monte Carlo Spec Decoding paper: arxiv.org/pdf/2604.15672
2
7
421
Jun 12
160/365 of GPU Programming
Taking a little break from studying FlashAttention to continue with CS336 today.
Lecture 10 is on inference and starts with a nice encapsulation of why inference is so important, continues on with what metrics matter in inference (TTFT, latency, throughput), then goes through how you can calculate arithmetic intensities for various operations before breaking down compute vs memory bound, KV cache, prefill vs decode, GQA, MLA, CSA, DSA, HCA, linear attention, QAT, PTQ, speculative decoding, continuous batching and paged attention.
Even if you're familiar with most of these concepts, it's a nice review of the inference stack and touches on some of the tradeoffs inherent in inference optimizations.
Jun 11
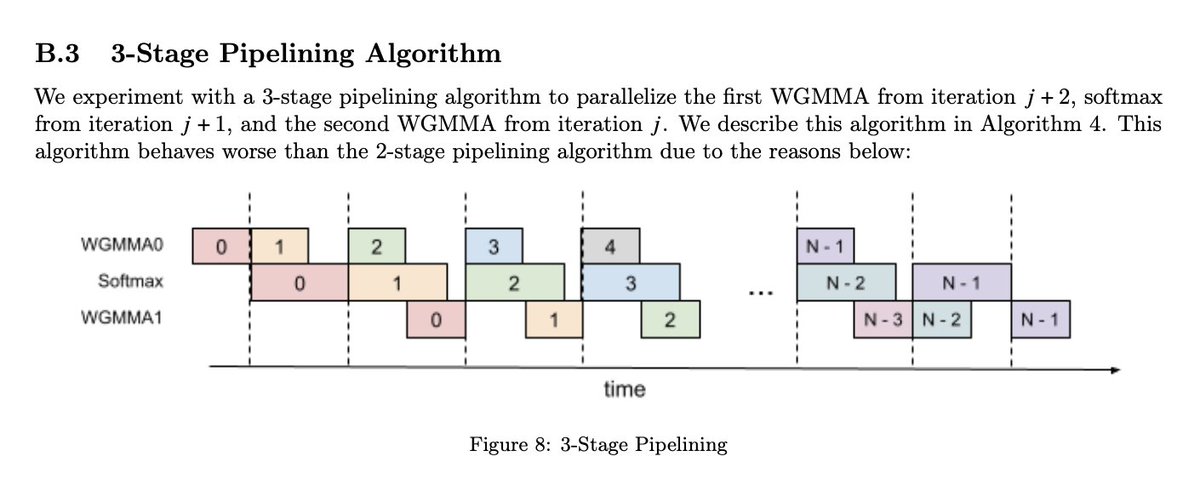
159/365 of GPU Programming
Doing a regular review today just looking at what I've been studying the past few weeks and looking at questions/confusions I wrote down along the way.
Will focus on parallelism/sharding strategies, FlashAttention v1-v4 and take another look at scaling laws tomorrow.


2
10
99
6,959
levi retweeted

Jun 11
Last fall, we shared our deep dive on FA4 internals.
But we didn't stop at grokking the kernel.
Since then, we've been developing improvements for inference performance and upstreaming them.
This blog post explains those contributions.
modal.com/blog/flash-attenti…

2
27
194
17,020
Jun 11
159/365 of GPU Programming
Doing a regular review today just looking at what I've been studying the past few weeks and looking at questions/confusions I wrote down along the way.
Will focus on parallelism/sharding strategies, FlashAttention v1-v4 and take another look at scaling laws tomorrow.
Jun 10
158/365 of GPU Programming
I think I understand the high level differences between the FlashAttention 2, 3 and 4 forward passes now but have yet to grasp the lower level details of each algorithm and the backward passes.
Need to spend some time learning more about cooperative thread arrays, DSMEM, emulation of the exp function, rowmax/rowsum, warp partitioning and specializatio, WGMMA, asynchrony, producer/consumer pipelines, etc


1
4
66
4,700
Jun 10
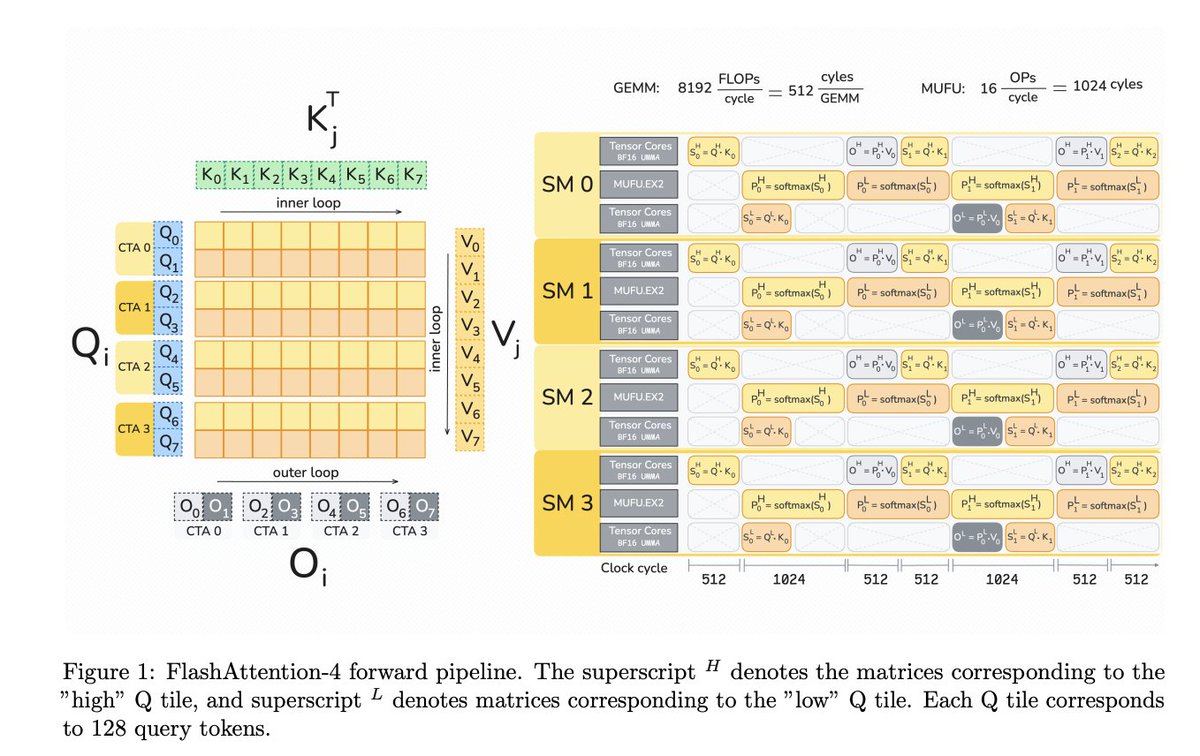
158/365 of GPU Programming
I think I understand the high level differences between the FlashAttention 2, 3 and 4 forward passes now but have yet to grasp the lower level details of each algorithm and the backward passes.
Need to spend some time learning more about cooperative thread arrays, DSMEM, emulation of the exp function, rowmax/rowsum, warp partitioning and specializatio, WGMMA, asynchrony, producer/consumer pipelines, etc
Jun 9
157/365 of GPU Programming
Another FlashAttention4 resource that's been really helpful for me is the talk @charles_irl gave last year on GPU Mode (basically the lecture version of We reverse-engineered Flash Attention 4 blog post which is awesome as well) about FA4's code and the evolution to FA4.
Really cool how the Modal team broke down the code before the paper release and made educated inferences about the forward pass.
Wish more people did deeper code dissections like this!


5
8
108
4,993
Jun 9
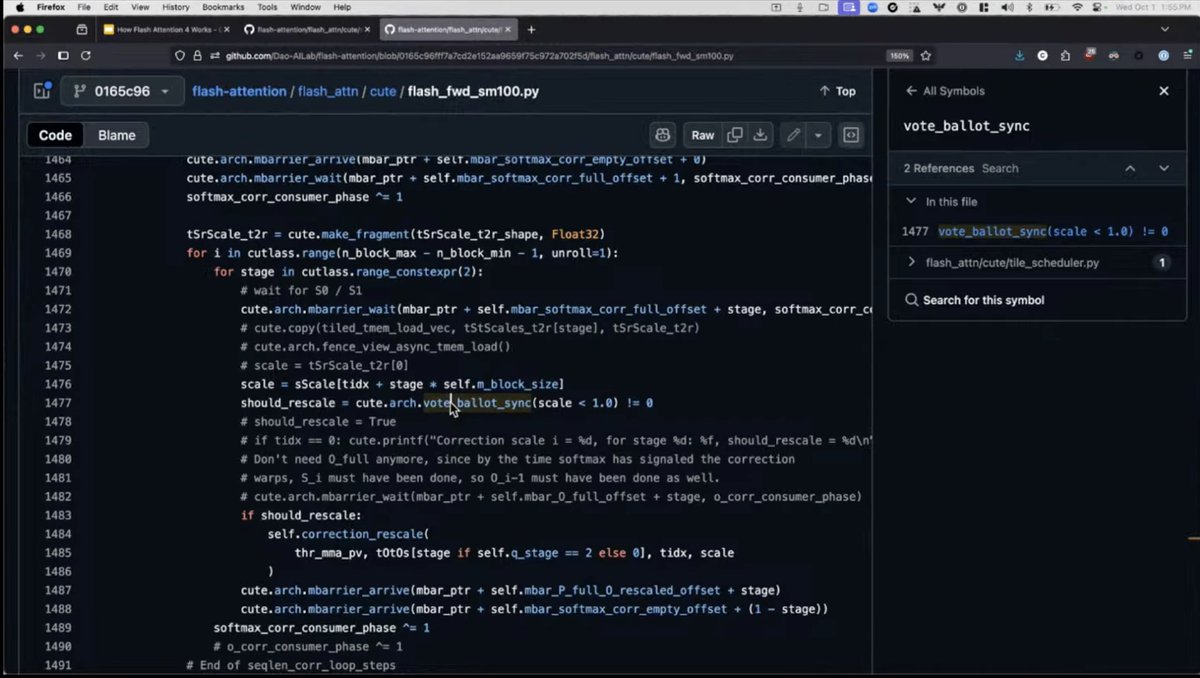
157/365 of GPU Programming
Another FlashAttention4 resource that's been really helpful for me is the talk @charles_irl gave last year on GPU Mode (basically the lecture version of We reverse-engineered Flash Attention 4 blog post which is awesome as well) about FA4's code and the evolution to FA4.
Really cool how the Modal team broke down the code before the paper release and made educated inferences about the forward pass.
Wish more people did deeper code dissections like this!
Jun 8
156/365 of GPU Programming
Giving FlashAttention 4 a read today and trying to get a sense of the evolution of FlashAttention in its forward and backward passes over the four generations.
I've seen @tedzadouri's GPU Mode talk mentioned quite a few times recently and have to echo that it's such a good perspective into what the thought process was behind FA4 and the steps to get there. @marksaroufim also does a great job interleaving the talk with pointed questions that help uninitiated learners like me get a better grasp of the concepts.
Also want to highlight @drisspg's talk on FlexAttention which had the animation/visualization of the softmax/MMA pipelining in FA4.


5
7
82
7,315
Jun 9
- Link to talk: youtube.com/watch?v=ZIEq-WTq…
- Link to blog post: modal.com/blog/reverse-engin…
2
5
538
Jun 8
156/365 of GPU Programming
Giving FlashAttention 4 a read today and trying to get a sense of the evolution of FlashAttention in its forward and backward passes over the four generations.
I've seen @tedzadouri's GPU Mode talk mentioned quite a few times recently and have to echo that it's such a good perspective into what the thought process was behind FA4 and the steps to get there. @marksaroufim also does a great job interleaving the talk with pointed questions that help uninitiated learners like me get a better grasp of the concepts.
Also want to highlight @drisspg's talk on FlexAttention which had the animation/visualization of the softmax/MMA pipelining in FA4.
Jun 7
155/365 of GPU Programming
Looking at FlashAttention 3 today and learning more about its hopper specific use of WGMMA (Warpgroup Matrix Multiply-Accumulate), different types of inter-warpgroup overlapping and the unique challenges of FP8 vs FP16 w.r.t datatype conversion and k-major constraints on FP8 WGMMAs.
Mainly trying to process the paper and reviewer comments today before going through the code.


2
4
44
5,948
Jun 8
- Link to paper: arxiv.org/pdf/2603.05451
- Link to 1st author talk: youtube.com/watch?v=kPKKvBqQ…
- Link to FlexAttention talk: youtube.com/watch?v=JiCJJDQN…
1
4
323
Jun 7
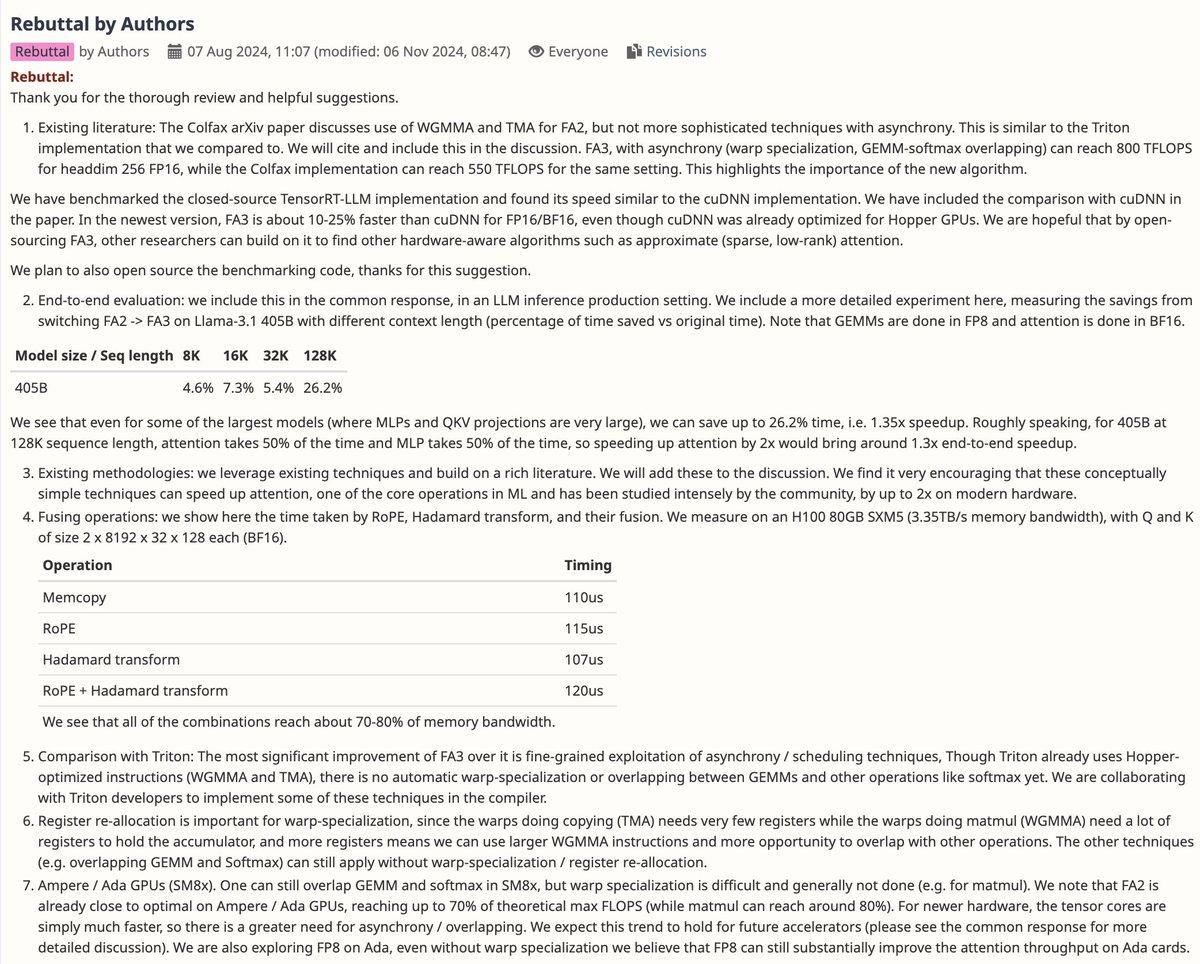
155/365 of GPU Programming
Looking at FlashAttention 3 today and learning more about its hopper specific use of WGMMA (Warpgroup Matrix Multiply-Accumulate), different types of inter-warpgroup overlapping and the unique challenges of FP8 vs FP16 w.r.t datatype conversion and k-major constraints on FP8 WGMMAs.
Mainly trying to process the paper and reviewer comments today before going through the code.
Jun 6
154/365 of GPU Programming
There's this really nice talk by Tri Dao that walks through some of the behind-the-scenes of FlashAttention 1 and FlashAttention 2.
Learned about the lore of Young-Jun Ko and how FA2 was originally born out of a refactor to use CUTLASS 3.
Not the most technical talk but cool to peek behind the curtain of one of the most important ML systems contributions of our time.


4
1
67
4,635
Jun 6
154/365 of GPU Programming
There's this really nice talk by Tri Dao that walks through some of the behind-the-scenes of FlashAttention 1 and FlashAttention 2.
Learned about the lore of Young-Jun Ko and how FA2 was originally born out of a refactor to use CUTLASS 3.
Not the most technical talk but cool to peek behind the curtain of one of the most important ML systems contributions of our time.
Jun 5
153/365 of GPU Programming
I've only ever looked at the original Flash Attention paper, so I'm spending this weekend to take a closer look at FA v2 and v3 this weekend.
One thing I love about OpenReview is how you can look back at the back and forth authors had with reviewers (in this case, Tri Dao for his FA2 ICLR submission) answering questions and providing rebuttals. You can also tell which reviewers are more familiar with the specific topic over others, which makes the questions asked during the review phase also quite broad in nature.

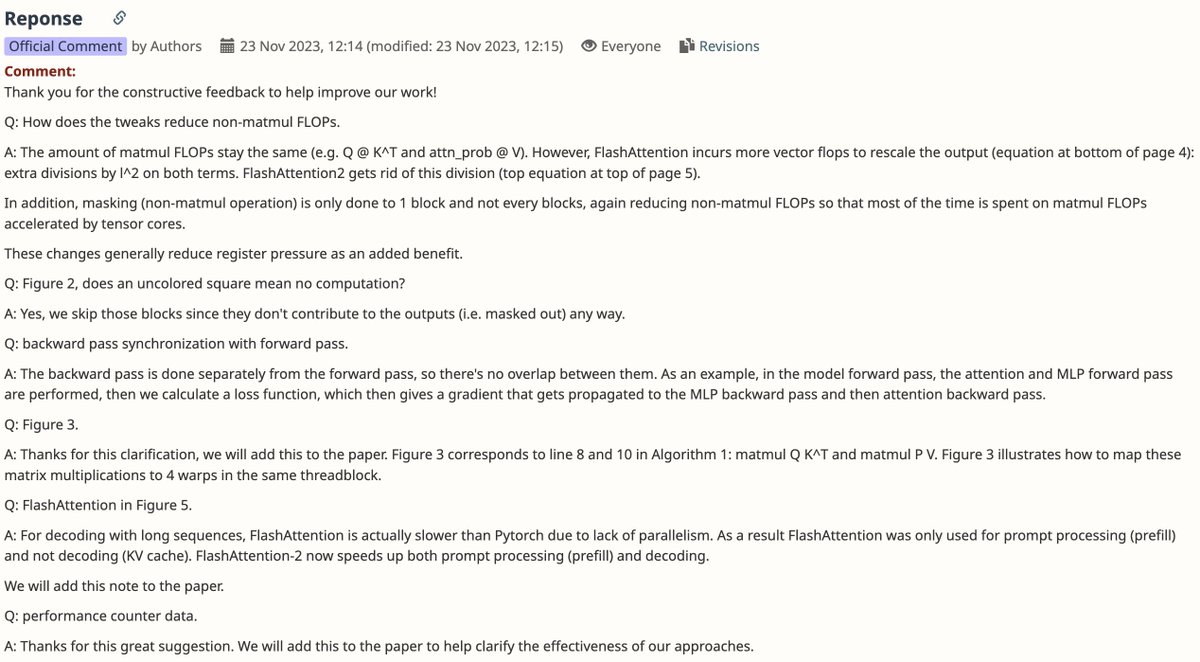

2
6
84
5,742
levi retweeted

Jun 6
Finally got some time to port my tcgen05 kernels to CuteDSL. For PTX enjoyers, this should feel natural (except TMA 🤣).
A BF16 MMA mainloop is shown below. I also worked up an example for MXFP8 and NVFP4.
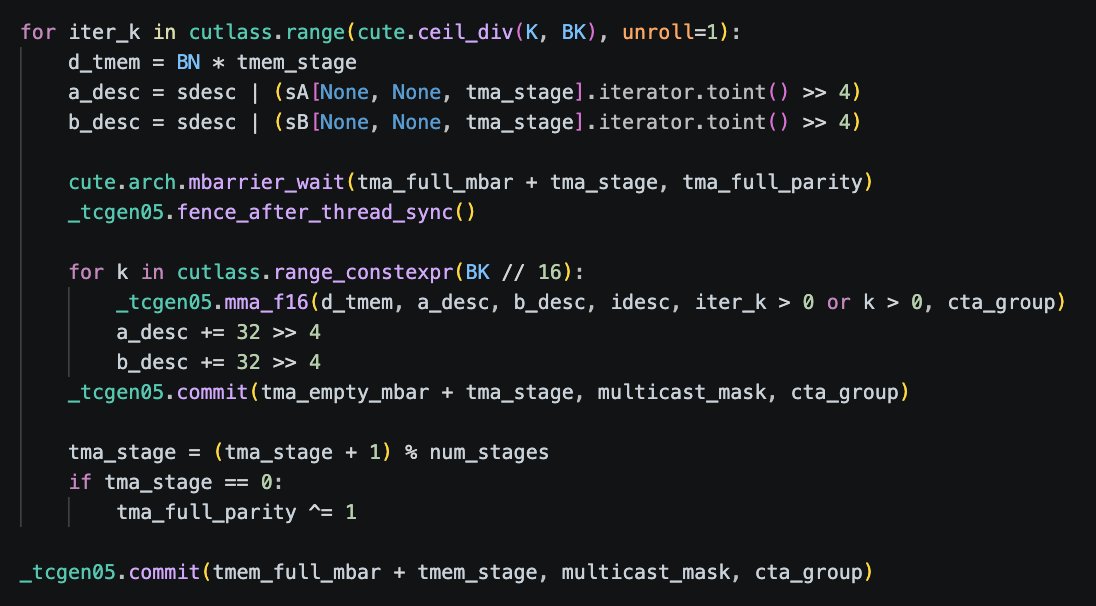
3
10
135
10,980
Jun 5
153/365 of GPU Programming
I've only ever looked at the original Flash Attention paper, so I'm spending this weekend to take a closer look at FA v2 and v3 this weekend.
One thing I love about OpenReview is how you can look back at the back and forth authors had with reviewers (in this case, Tri Dao for his FA2 ICLR submission) answering questions and providing rebuttals. You can also tell which reviewers are more familiar with the specific topic over others, which makes the questions asked during the review phase also quite broad in nature.
Jun 4
152/365 of GPU Programming
@mlech26l recently gave a really nice talk at MIT on Massively Parallel Training based on his experience as CTO of Liquid AI.
The lecture provides a really practical overview of the implications of scaling laws, compute vs memory tradeoffs, activation checkpointing, offloading to CPU memory, RDMA, sharding tradeoffs (e.g. optimizer states, pipeline, column vs row parallelism, etc), load balancing challenges, DeekSeek ZeRO, FSDP strategies and stacking different kinds of parallelisms

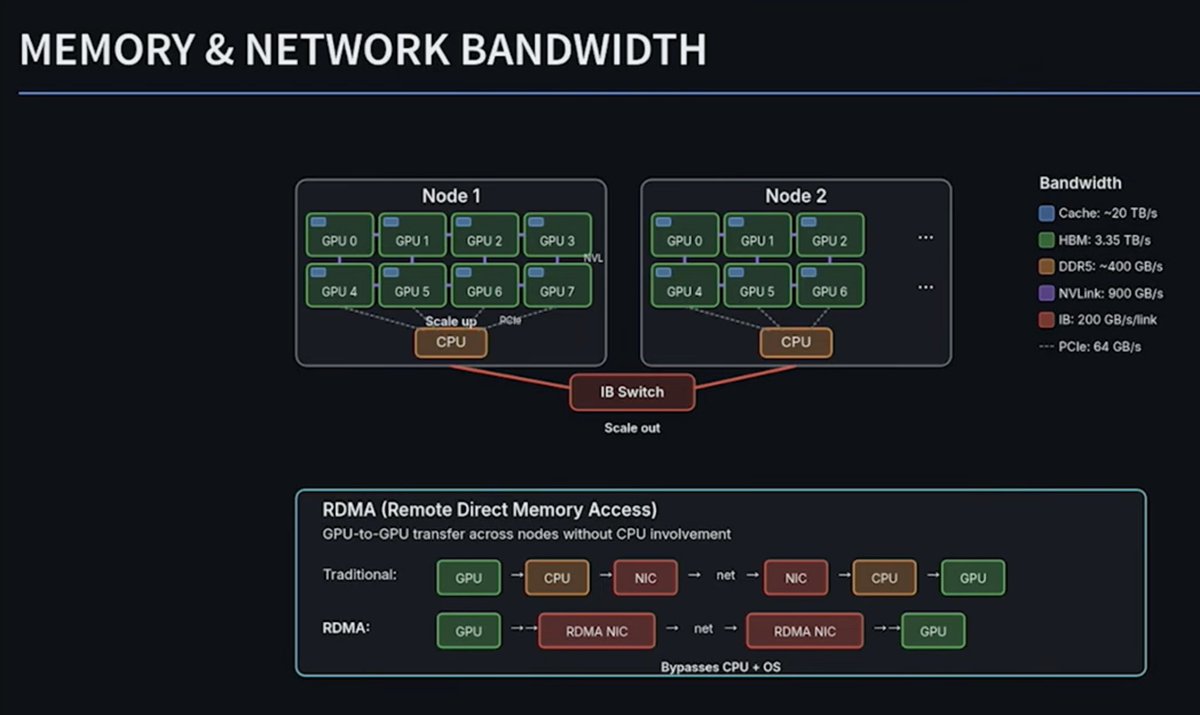

2
2
55
5,460