
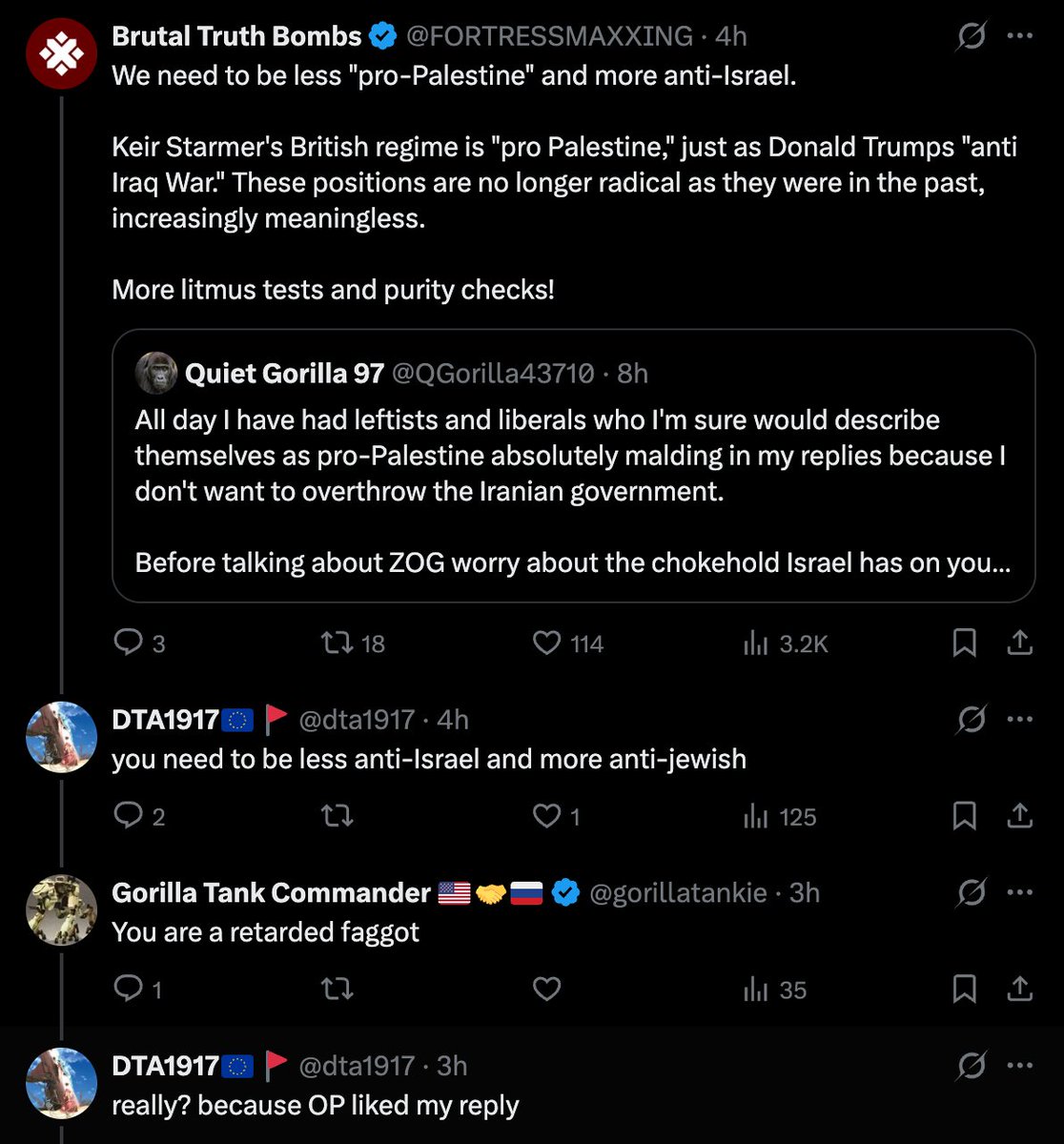
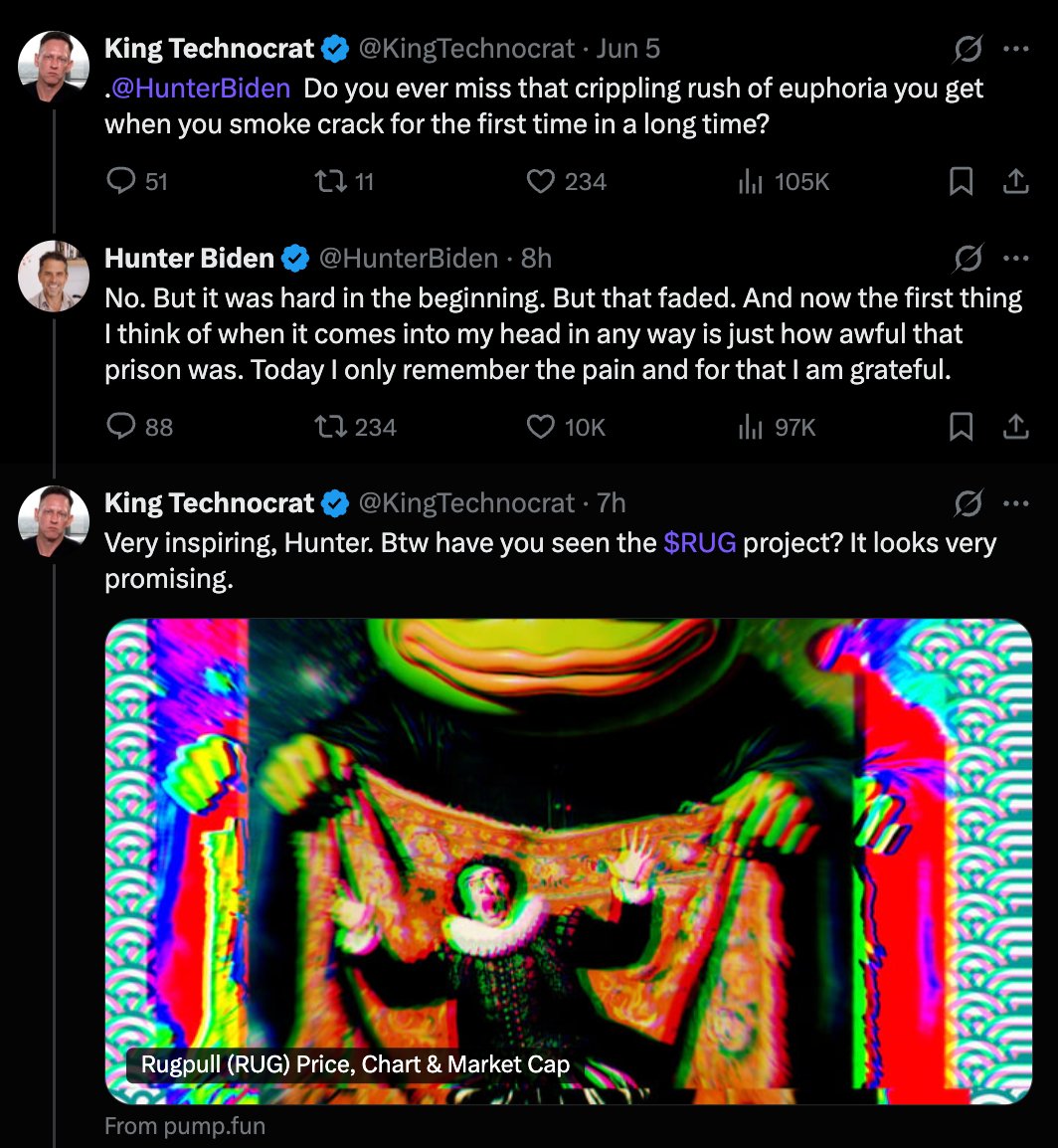
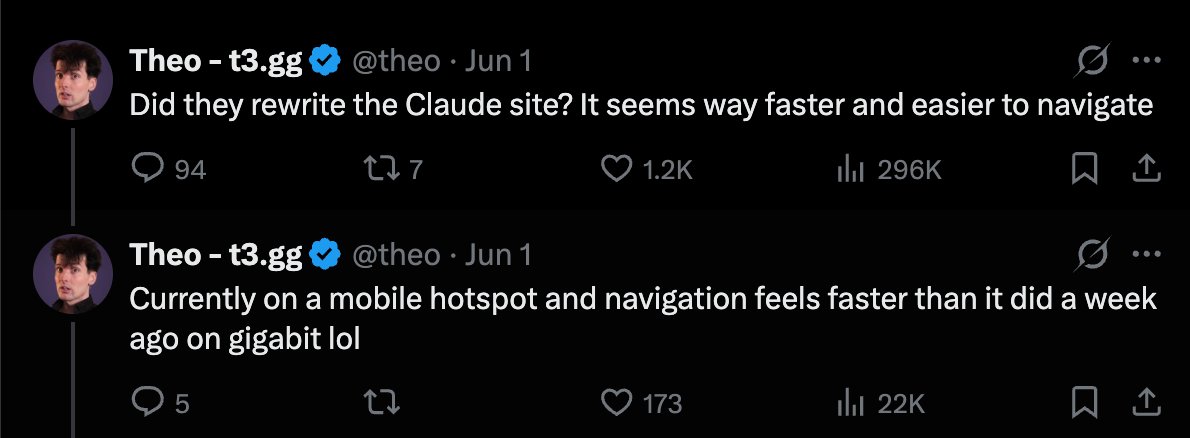
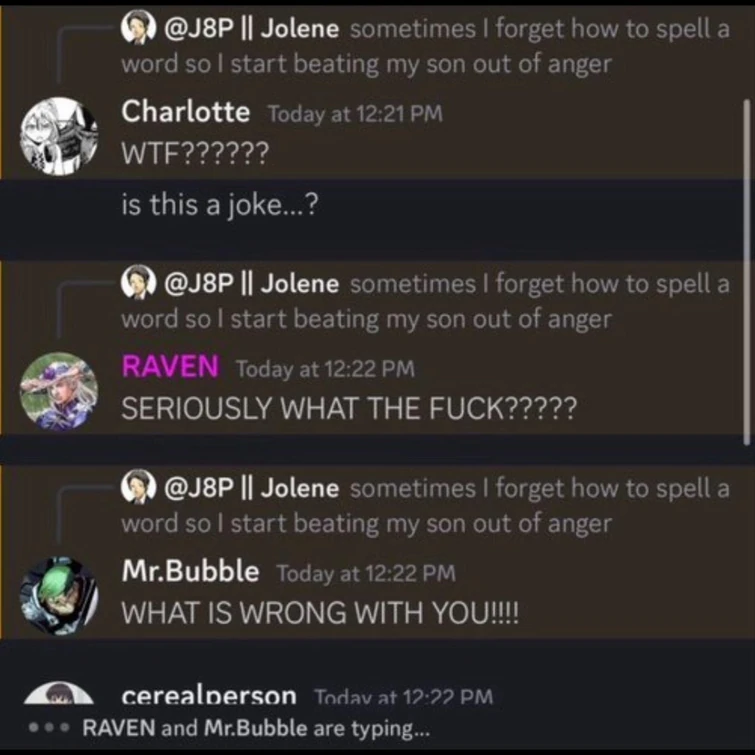
libpol.org is a 4chan-like anonymous imageboard without any right-wingers
Joined June 2023
- Tweets 15,496
- Following 371
- Followers 379
- Likes 96,980
560 Photos and videos






10h
BREAKING
Local farrier revealed to have forged horseshoe so cursed it colocates Marc Andreessen and Timnit Gebru

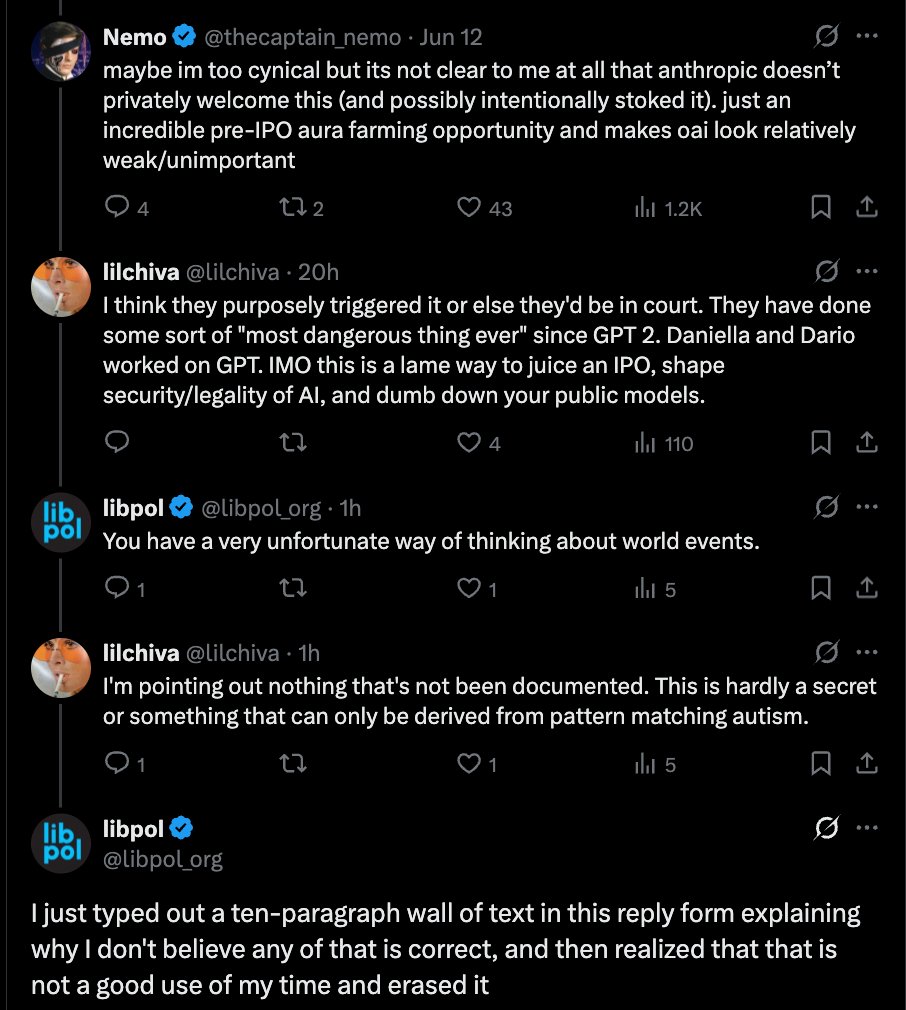
Lol Anthropic made such a big deal about their model being “dangerous” because they thought the only result was gonna be hype something something preventing China from something.
1
38
libpol retweeted

Jun 11



24
1,265
24,780
461,281
libpol retweeted

Jun 11
Claude says the black mold in my house is good because it turns me into an ecosystem: I'm not just myself -- I'm something bigger now
14
33
618
13,356
Jun 10
Fable really feels so much more pleasant to talk to than Opus
Less annoying, less of a yapper, more straightforward, less forgetful, less prone to confusion
32
libpol retweeted
Jun 9
New Claude model is crazy but it still can't answer the strawberry question

39
227
8,299
176,600

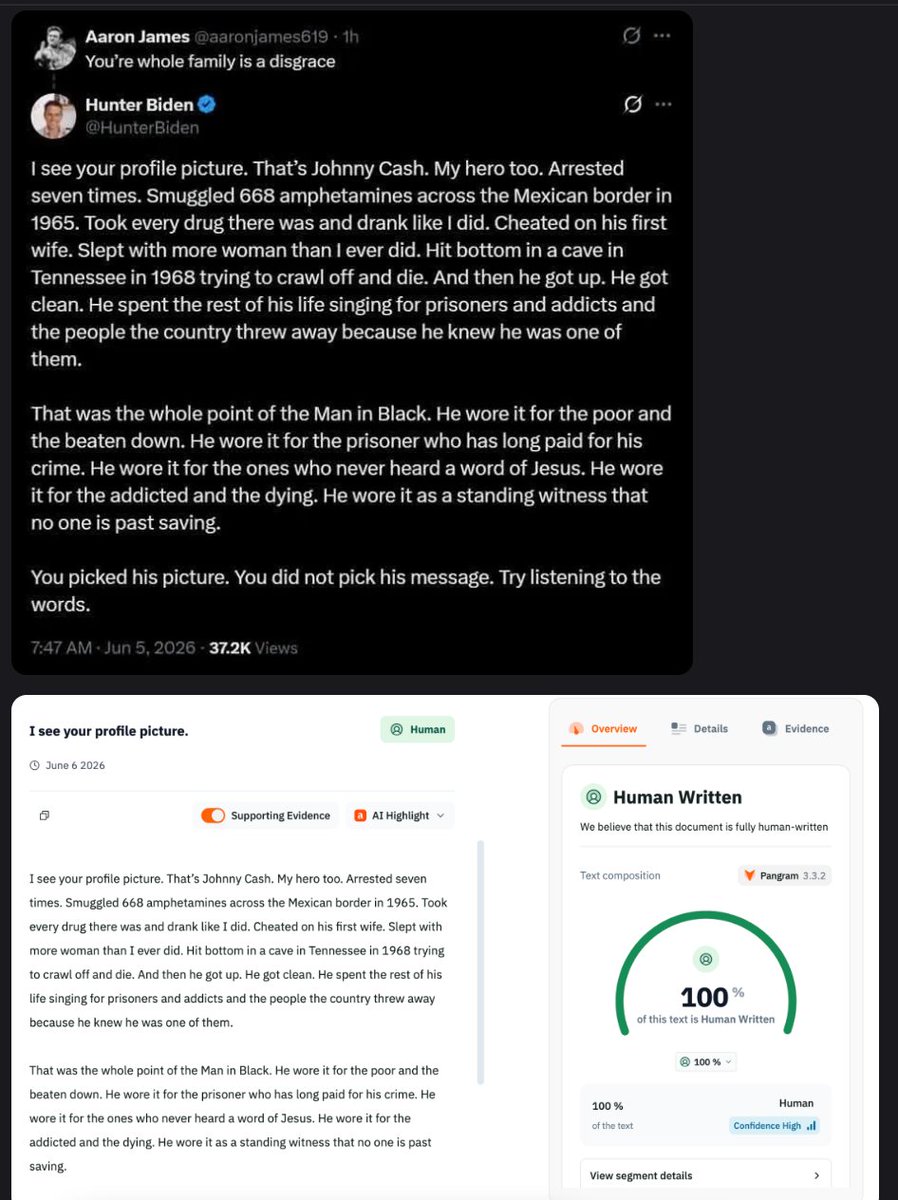
We believe that this document is fully AI-generated
pangram.com/history/6a4c486e…


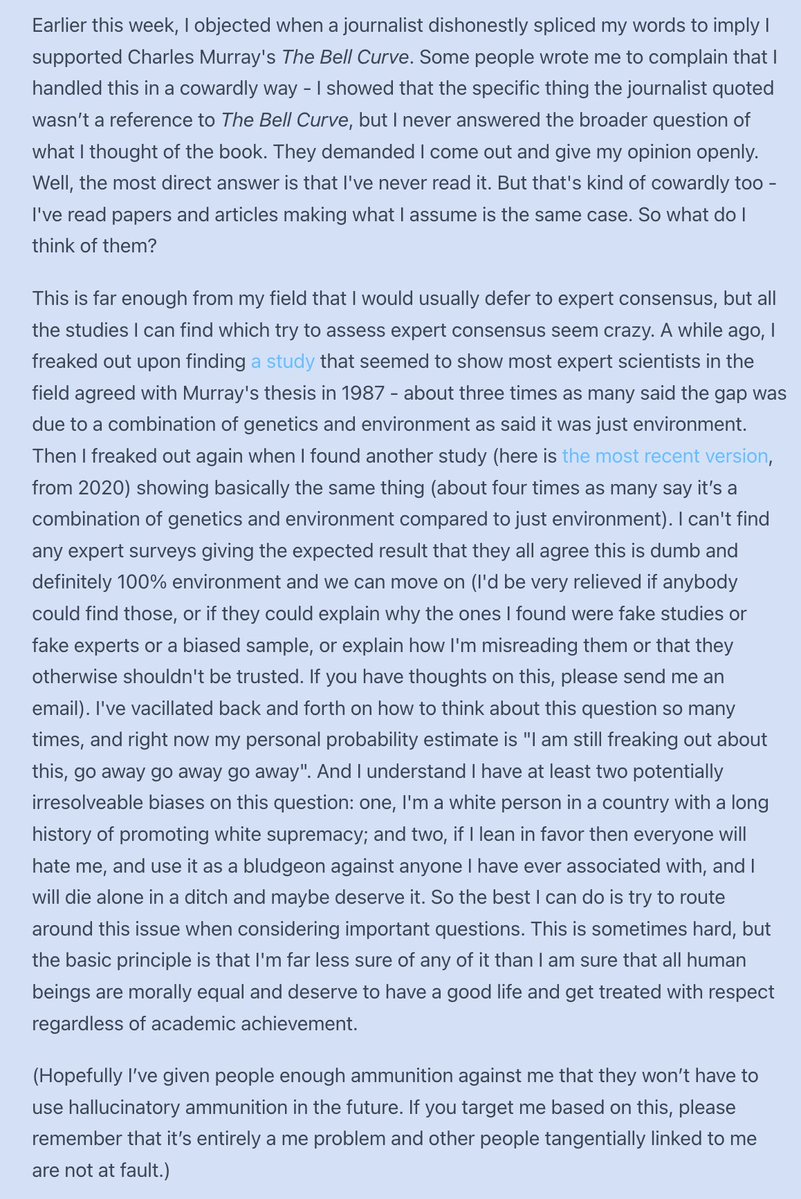
Students without access to LLMs are 2 to 8 times more creative than students with access.
That is the finding of a new paper comparing 2,200 college admissions essays written by humans before ChatGPT with essays generated by GPT-4.
The key point is not individual creativity. GPT-4 can write well, sometimes better than individual students. The problem is collective creativity.
Each new human essay added new semantic territory. New ideas. New angles. New experiences. New combinations.
Each new GPT-4 essay added much less.
The authors call this the diversity growth rate: how much novelty each additional text contributes to the collective pool of ideas.
Humans kept expanding the pool. GPT-4 made the pool converge.
Even when the authors pushed GPT-4 to be more creative, changed parameters, or used chain-of-thought prompting, the homogenizing effect remained.
This is the real danger of AI in education.
Not that students will write worse.
That everyone will write the same.
*
Full paper in the first reply

1
5
84
libpol retweeted

Jun 9
buy low. morphological freedom is good, we are not slaves to our lots at birth, and it is both possible and reasonable for a mentally sound person to conclude they would be happier with a change
we’re in a wave of anti-trans sentiment right now, but the morality hasn’t changed
Jun 9

GALLUP: Moral acceptability of changing one’s gender hits new record low
✅️ Morally acceptable: 38%
❌️Morally wrong: 57%
——
Net acceptability trend
🟡 2021: (–5)
🟤 2025: ( –14)
🔴 2026: (–19)

80
66
1,042
52,967
Jun 9
this is one of the worst songs I've ever experienced in my entire life

49
libpol retweeted

Jun 9
if you are not asking chatgpt for restaurant recommendations in a while loop then you are going to die
19
1
129
6,555
libpol retweeted

0 is as much a magnitude ratio as any other number you like. For example, 0 is the ratio of your correctness to mine.
5
22
1,273
7,928
libpol retweeted
I cannot believe the replies found another way to be pedantically annoying. You are all convinced that zero is "not a number" due to, apparently, the TV show Young Sheldon?
21
39
3,022
230,742
libpol retweeted

Jun 9
If someone tells me they lost weight through diet and exercise, then to me all that says is that you’re afraid of needles. Basically it’s cheating.
54
66
1,955
241,028
libpol retweeted

when writing code, especially with ai, you often just need to know that it's possible to do something, and then the exact details are trivial
1
1
6
112
libpol retweeted




68
675
15,500
937,916
libpol retweeted

Jun 8
western neoliberals have more in common with a Tsinghua Business school graduate turned CCP bureaucrat than with western communists
6
18
250
7,534
libpol retweeted

Jun 9


Jeffries: It’s not clear to me that Donald Trump is a big Knicks fan. Does this guy even know the difference between Karl Rove and Karl-Anthony Towns? I don’t think so.
20
591
15,073
406,135
Jun 9
Just at a purely meta level, it's interesting how Cassie Pritchard is like 1000 miles ahead of seemingly nearly all Twitter leftists when it comes to the art of winning
I would not be shocked if she one day emerges as some sort of ascendant CyberLenin

DSA should create a taskforce of our most libbed-out members dedicated to ingesting all of Singer, Rawls, and LessWrong to start propagandizing the EAs.
91
libpol retweeted

my friend at anthropic just asked me what color dog collar i wanted . i asked them “what the hell” and they insinuated that after the IPO everyone will be “owned” by some frontier lab employee . and would i prefer an oai owner ? i said green
53
97
3,547
204,831
libpol retweeted

Jun 8
USAID derangement is so incredible because the fringe left thinks it was an imperialist tool to elect right-wingers and the far-right thinks it was a globalist tool to elect leftists.

122
734
6,903
178,423
Jun 8
This seems to mostly be "easy-to-medium tasks any model could do, but who implements things the most elegantly and idiomatically", and it makes sense Opus 4.8 wins that. For "make this sprawling difficult complex change in this big codebase", I think GPT-5.5 will generally win
Jun 8

Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

43