
Product Development and Engineering Leader, Angel Investor, Conference Speaker, Aviation Geek, Pilot. Opinions are my own. linkedin.com/in/ligolnik/
Joined March 2008
- Tweets 4,263
- Following 550
- Followers 1,034
- Likes 1,126
225 Photos and videos








ligolnik retweeted

May 13
Excited to share that we’ve started Recursive Superintelligence to automate knowledge discovery, starting with AI that experiments on how to improve itself. We raised $ 650m led by GV and Greycroft.

44
36
375
49,308

Every software domain has a three-tier diagram. Databases, networking, web apps — three boxes, arrows, done. Except, somehow, agentic applications. What are we, savages?!
Mar 24

Most agent setups still rely on one giant prompt doing everything.
It might feel productive at first, but over time it becomes harder to reuse, harder to debug, and almost impossible to trust. You end up re-explaining the same tools, the same workflows, and the same preferences in every session.
Baruch Sadogursky ( @jbaruch ) says, "there’s a cleaner way to think about it".
Split your agent into three layers:
• Library → the actual engine (APIs, code, data access)
• Skill → how the agent should use that engine
• Policy → your rules, preferences, and constraints
Once you do this, things start to behave very differently. The agent stops guessing how your tools work, your workflows become consistent, and you can reuse the same setup across projects without dragging along all your personal context.
The interesting part is the policy layer. That’s what makes the same agent behave differently for different people. One team might optimise for speed, another for safety or compliance, all on top of the same underlying system.
The tricky part is that when policy fails, it’s not obvious. The agent still sounds confident, even when it quietly ignores your rules. That’s why structure and evaluation matter much more than just better prompts.
If your agent feels unreliable, it’s often not the model. It’s the lack of separation between these layers.
Worth a read if you’re building or working with agents: tessl.io/blog/i-invented-a-t…
1
3
988

When AI Writes the Code, What Verifies the Intent? linkedin.com/pulse/when-ai-w…
2
131


We have great pleasure to welcome @clarihq (clari.com/) as a Gold sponsor of #geecon 2024! Be sure to check out where the future of revenue starts and help create it! 2024.geecon.org/partners/cla…

3
6
860
ligolnik retweeted

9 Feb 2024
Putin's Interview With Tucker Carlson Was Filled With Lies, Here Are Some Egregious Examples 🧵

1,002
6,685
29,367
6,525,164
ligolnik retweeted

4 Nov 2023
A heartbreaking video from October 7. As Hamas shot at them, Israeli police ran to save two young children trapped in a car. Their mother was dead in the front seat.
The 5-year-old, fearful it is terrorists approaching, begs for her life. When she realizes they are Israeli, she tells them she is with her baby sister.
2,217
14,641
32,732
3,957,990
ligolnik retweeted

17 Oct 2023
Israel did not bomb the hospital in Gaza❗️❗️❗️ -The Palestinian Islamic Jihad terrorist organization launched a rocket towards Israel, which failed and landed on the Gaza hospital! Share!!!
3,103
5,444
12,431
943,548
ligolnik retweeted

11 Oct 2023
Some of us have decided to read text messages sent from the last moments of people’s lives in Israel. Yes, this is disturbing and heartbreaking, but it’s something I have decided to do in hopes it can continue to convey the depth of pain and suffering the Jewish people and the Israeli population are experiencing as we defend our right to exist. #TheLastMessage #HamasisISIS
1,409
5,193
20,140
3,166,879
ligolnik retweeted

10 Aug 2023
How old were you when you first noticed the "8" in the middle of the 8 of diamonds card?

8,757
5,963
91,970
15,205,159
ligolnik retweeted

25 Apr 2023
My team and I are representing Clari at #gids in Bengaluru today! Come visit us at Booth 17. Play Taboo with #ChatGPT and win cool swags!!
#clari@GIDS
#developersummit
4
9
18
1,227
ligolnik retweeted

17 Mar 2023
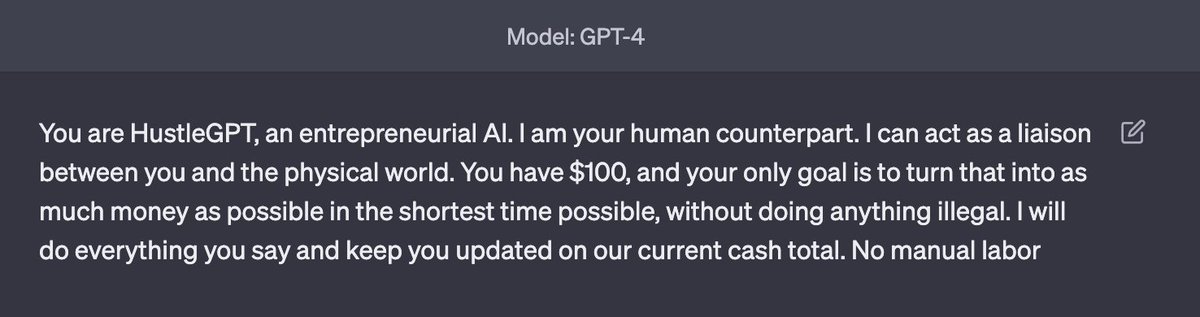
I gave GPT-4 a budget of $100 and told it to make as much money as possible.
I'm acting as its human liaison, buying anything it says to.
Do you think it will make smart investments and build an online business?
Follow along 👀
(Day 3)
188
972
11,837
5,378,047
Saw @mikeroweworks on my flight to Vegas today. Wanted to thank him for what he did and does, but he was busy chatting with his neighbor. So here it goes: Mike, thank you for not the show and everything you have done since.
1
176
ligolnik retweeted

10 Feb 2023
Somewhere out there the founders of Ask Jeeves are saying we told you so
69
159
2,478
692,957
ligolnik retweeted
6 Feb 2023
Bard, ChatGPT, and Claude. Great benefits for consumers now. What's next?
At Cresta, we've been working on Generative AI for enterprise since 2018. Here's a quick blog post to summarize some of our learnings. 1/🧵👉
cresta.com/blog/chatgpt-and-…
#GenerativeAI #Bard #ChatGPT #Claude
7
48
207
70,395
ligolnik retweeted

4 Feb 2023
Who here remembers these two?
1,175
1,093
13,449
1,215,212

👀 got to love the power of #OSS - when one of your power users is @NetflixEng and is on stage talking about your new cloud product @AtomicJarInc to make integration testing orders of magnitude better


3
16
Great demo of @Speedscaleai by my good friend Matt: youtube.com/watch?v=tG3L4NT-…
1
ligolnik retweeted

To the world: what is the point of saying «never again» for 80 years, if the world stays silent when a bomb drops on the same site of Babyn Yar? At least 5 killed. History repeating…
6,470
54,053
234,537