
vp of engineering :: father of one :: ex-@Amazon, ex-@riotgames
Joined April 2007
- Tweets 5,903
- Following 1,085
- Followers 326
- Likes 112
73 Photos and videos





Istvan retweeted

Jun 12
Elon just created 4,400 millionaires in a single day.
400 of them are now worth over $100 million.
These aren't VCs. They're SpaceX employees, and the list includes welders, technicians, and cafeteria staff, because for two decades the company paid every level of the workforce in stock instead of higher salaries.
Juan Hernandez immigrated from Mexico and took a $28 an hour contractor welding job in 2015. He says he didn't even know what SpaceX was. The company gave him a $10,000 equity grant and let him buy more shares through payroll deductions. That stake is now worth $880,000.
Trevor Hise's parents wanted him to take a stable job at General Electric. He picked SpaceX instead, stayed 12 years, and accumulated over 100,000 shares. At the $135 listing price that's $13.5 million. He's 37 and semiretired. His words: "The magnitude of this has been ridiculous."
The most telling detail came before the listing. Over 100 employees quietly banded together and negotiated a group wealth management deal covering up to $5 billion, because none of them had ever needed a wealth manager before.
Software IPOs have minted millionaires for 30 years. This is the first one where the money went to the factory floor.
3,269
25,556
141,704
7,403,944
Istvan retweeted

Jun 11
A toothpaste company has quietly killed the entire market research industry and nobody is talking about it.
Colgate published a paper showing you can predict real purchase intent at 90% accuracy by simply asking LLMs to roleplay customers.
And this is beyond insane.
If you ask an AI, "Rate this product from 1 to 5," it gives safe, middle-of-the-road garbage.
So researchers invented a method called Semantic Similarity Rating (SSR).
Instead of asking the AI for a number, they asked it to roleplay.
They gave the LLM a demographic profile. They showed it a product concept. And they asked it to write down its raw, unfiltered thoughts.
Then, they used a semantic model to translate those written thoughts into a numerical score.
The results are staggering.
Tested against 57 real corporate surveys and 9,300 actual human responses, the synthetic AI consumers matched real human buying behavior with 90% reliability.
They perfectly mirrored how different age brackets and income levels react to price changes.
And they provided detailed, qualitative feedback that was deeper and more critical than what actual humans wrote.
This destroys the economics of traditional market research.
You don't need to wait a month to see if a product will sell.
You can simulate 1,000 hyper-targeted customer interviews overnight.
You can A/B test pricing across every demographic instantly.

Community note
The 90% figure refers to the AI method achieving 90% of human test-retest reliability for purchase intent surveys, not 90% accuracy in predicting real purchases. It was tested on personal care products in categories LLMs know well. arxiv.org/abs/2510.08338
228
939
7,579
701,119
Istvan retweeted
May 5
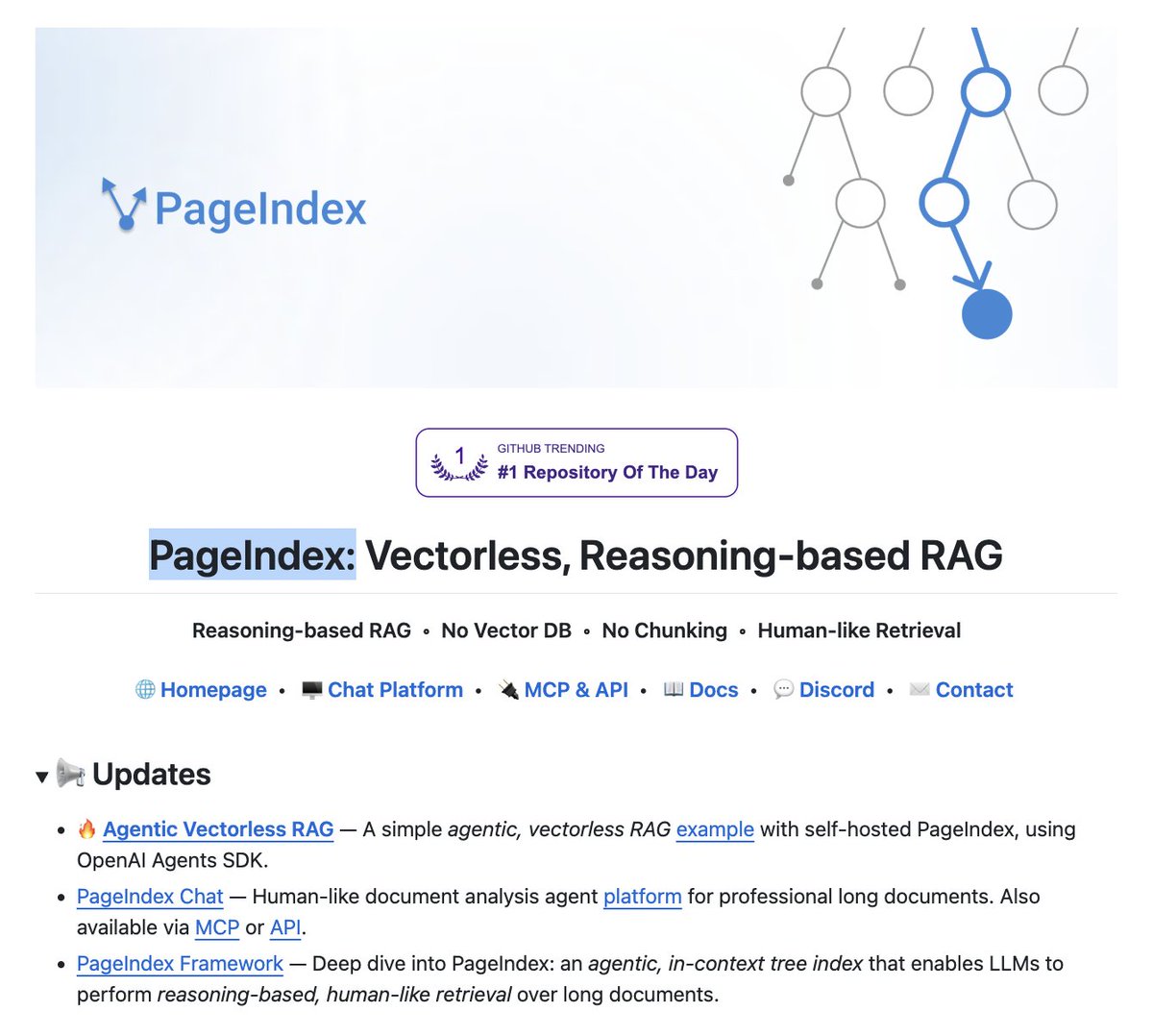
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
222
778
6,897
617,171


Unfortunately yes, we remember
Apr 11

Remember when everyone said I was crazy for noticing how much Claude Code regressed?
82
This is exactly the right way for most businesses domain apps (as opposed to highly specialized use cases)
Apr 11

What if you just write Rust like a high-level, garbage collected language?
Turns out with a few rules you can basically get all its perf / type benefits with only a 10-20% per hit.
- Immutable types, functionalish pipes
- Arc clone liberally
- DDD services
1
107
Apr 10

“Built in rust” is not a feature btw
62
I have very similar experience. Diversifying your LLM use is a must at this stage.
Apr 6

Anthropic really is burning more and more dev goodwill
Claude Code is suddenly getting unusable for stuff you could use it before (as in a day before!) and the AI now refuses to so stuff that it doesn’t think is strictly to do with software development.
No transparency why ofc
147

Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: cs.stanford.edu/~knuth/paper…

148
1,864
9,101
1,413,956

Istvan retweeted

Jan 29
NVIDIA just dropped a banger paper on how they compressed a model from 16-bit to 4-bit and were able to maintain 99.4% accuracy, which is basically lossless.
This is a must read. Link below.

71
422
4,298
308,397
Nothing signals how great era we live in than getting approval to have the word “open” in your product from a company.🤷♂️
Jan 30
I like this final name better 🦀
Of course because Anthropic demanded the first name to be change (similarity to Claude) you might wonder if OpenAI could do the same the future.
In what is an absolute boss move @steipete called Sam and asked, then changed the name
86
They are in the web dev industry 🤷♂️
Jan 27

What am I missing? Why is 3ms a good result?
1
1
2
1,070
Istvan retweeted

Jan 9
I’ve been building Dexter for 2 months now.
It’s like Claude Code, but for finance.
What Dexter can do:
• find undervalued stocks
• analyze them in detail
• build investment thesis
All of the code is open source.
Bonus: Dexter can also run on local LLMs.
248
344
5,530
552,766
We reached the end of internet very quickly today. It is not worth to read anything else.
Jan 8

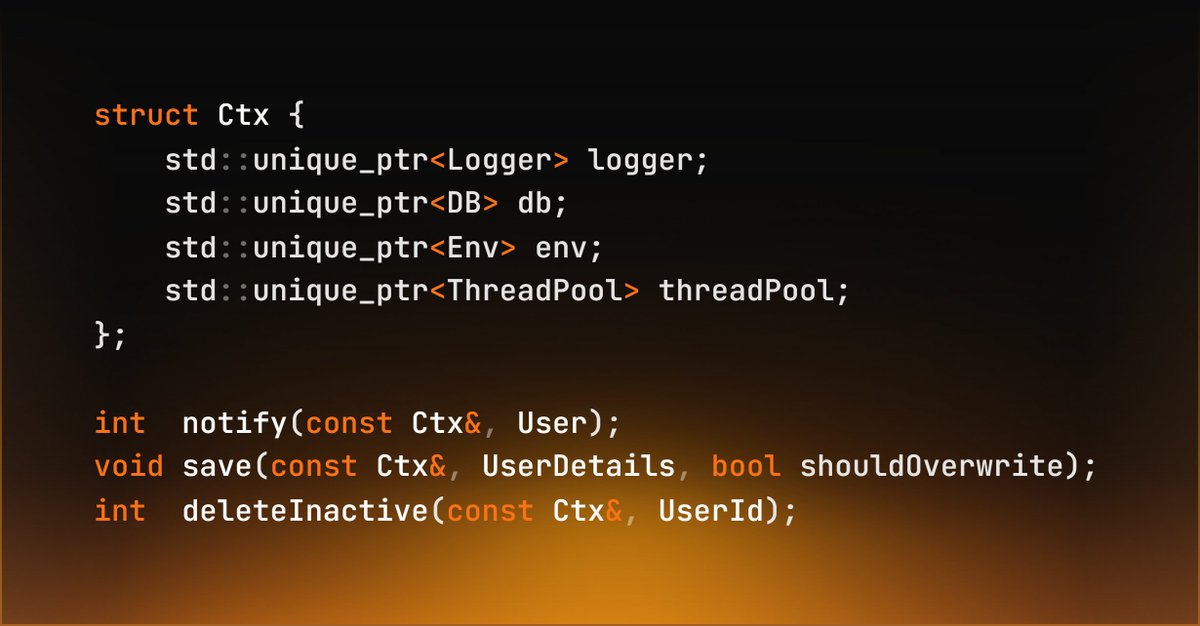
After 8 years of Haskell, 2 years of OCaml, 2.5 years of C and 45 minutes of Go, I present you the ultimate Design Pattern.
The Context Pattern
FP, OOP, Procedural and Declarative Programming combined to create The Last and Only design pattern you ever need.
A single record containing all your dependencies that you pass to every function explicitly.
No more inheritance.
No more classes and methods.
No more Dependency Injection.
No more singleton pattern.
No more private/public.
Mocks have never been easier.
This is the only pattern you need to structure EVERY SINGLE APP NO MATTER THE INDUSTRY (microservice, compiler, spaceship system).
91
Istvan retweeted

Jan 8
After 8 years of Haskell, 2 years of OCaml, 2.5 years of C and 45 minutes of Go, I present you the ultimate Design Pattern.
The Context Pattern
FP, OOP, Procedural and Declarative Programming combined to create The Last and Only design pattern you ever need.
A single record containing all your dependencies that you pass to every function explicitly.
No more inheritance.
No more classes and methods.
No more Dependency Injection.
No more singleton pattern.
No more private/public.
Mocks have never been easier.
This is the only pattern you need to structure EVERY SINGLE APP NO MATTER THE INDUSTRY (microservice, compiler, spaceship system).
191
133
2,116
243,655
I think TailwindCSS is convenient. Using raw CSS is not so much. For humans. For agentic coding tools raw CSS is totally doable. You can re-implement your own atomic css library in short time if you like the concept.
Jan 9

All my new code will be closed-source from now on. I've contributed millions of lines of carefully written OSS code over the past decade, spent thousands of hours helping other people. If you want to use my libraries (1M downloads/month) in the future, you have to pay.
I made good money funneling people through my OSS and being recognized as expert in several fields. This was entirely based on HUMANS knowing and seeing me by USING and INTERACTING with my code. No humans will ever read my docs again when coding agents do it in seconds. Nobody will even know it's me who built it.
Look at Tailwind: 75 million downloads/month, more popular than ever, revenue down 80%, docs traffic down 40%, 75% of engineering team laid off. Someone submitted a PR to add LLM-optimized docs and Wathan had to decline - optimizing for agents accelerates his business's death. He's being asked to build the infrastructure for his own obsolescence.
Two of the most common OSS business models:
- Open Core: Give away the library, sell premium once you reach critical mass (Tailwind UI, Prisma Accelerate, Supabase Cloud...)
- Expertise Moat: Be THE expert in your library - consulting gigs, speaking, higher salary
Tailwind just proved the first one is dying. Agents bypass the documentation funnel. They don't see your premium tier. Every project relying on docs-to-premium conversion will face the same pressure: Prisma, Drizzle, MikroORM, Strapi, and many more.
The core insight: OSS monetization was always about attention. Human eyeballs on your docs, brand, expertise. That attention has literally moved into attention layers. Your docs trained the models that now make visiting you unnecessary. Human attention paid. Artificial attention doesn't.
Some OSS will keep going - wealthy devs doing it for fun or education. That's not a system, that's charity. Most popular OSS runs on economic incentives. Destroy them, they stop playing.
Why go closed-source? When the monetization funnel is broken, you move payment to the only point that still exists: access. OSS gave away access hoping to monetize attention downstream. Agents broke downstream. Closed-source gates access directly.
The final irony: OSS trained the models now killing it. We built our own replacement.
My prediction: a new marketplace emerges, built for agents. Want your agent to use Tailwind? Prisma? Pay per access. Libraries become APIs with meters. The old model: free code -> human attention -> monetization. The new model: pay at the gate or your agent doesn't get in.
1
115
Istvan retweeted

Jan 6
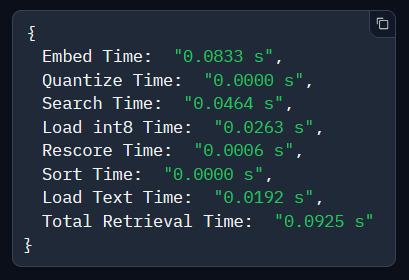
🏎️ You can perform 200ms search over 40 million texts using just a CPU server, 8GB of RAM, and 45GB of disk space.
The trick: Binary search with int8 rescoring.
I'll show you a demo & how it works in the 🧵:
33
195
1,957
119,930
Istvan retweeted

30 Dec 2025
My universal subagent setup for each project, bookmark it 📂
.claude/
├── agents/ # 7 subagents
│ ├── orchestrator[.]md
│ ├── code-reviewer[.]md
│ ├── debugger[.]md
│ ├── docs-writer[.]md
│ ├── security-auditor[.]md
│ ├── refactorer[.]md
│ └── test-architect[.]md
35
76
1,055
369,116
Istvan retweeted

30 Dec 2025
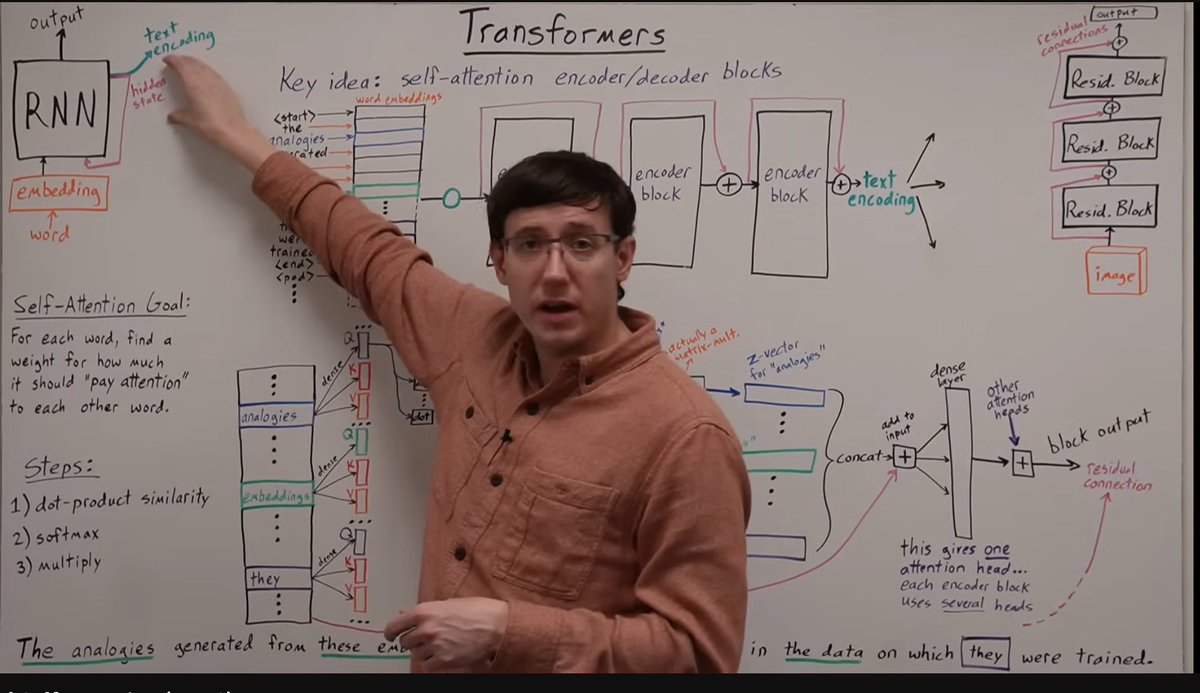
Hands down, this is the clearest and most effective explanation of Transformers on YouTube. The lecture was delivered by Professor Bryce as part of Davidson’s CSC 381: Deep Learning (Fall 2022).
If your goal is to truly understand Transformers and self-attention, this is the only video you need and there’s no reason to watch anything else.
39
480
4,442
266,514