
79 Photos and videos














Ben Longmier retweeted

Jun 10
AI’s next bottleneck is power. @dfjgrowth is thrilled to back @ambrosiaenergy, building modular, off-grid solar battery plants for AI workloads. Honored to partner with Benjamin Longmier @longmier, Sara Spangelo @sara_spangelo, & the Ambrosia team.
dfjgrowth.com/story/ambrosia…
1
7
17
4,866

Jun 10
A few more words about why solar battery power plants, and why now.
A few things have aligned to make off-grid power plant operations possible at a 99.9% reliability while only using solar battery storage.

3
2
32
4,647
Jun 10
Appreciative of our early backers, @dfjgrowth
Jun 10
We are building solar battery power plants, off-grid to start. 100% renewable. 99.9% availability.
Grateful to our early backer @dfjgrowth. Read more about Ambrosia from DFJ: dfjgrowth.com/story/ambrosia…
22
2,587
Jun 10
We are now hiring in Austin TX and Redwood City CA for building what we think will be the fastest power plants to deploy in the US. 100% renewable.
DM me or apply online: ambrosia.energy/team
Jun 10
Ambrosia Energy’s mission is to deploy the fastest and lowest-cost, continuous, renewable energy in the US. We want to add lots of power to the US grid eventually, and are starting with off-grid solar battery power plants to power compute.
Looking for many new hires in both Silicon Valley and Austin.

3
20
5,228
Ben Longmier retweeted

For the first time in 123 years, Argentina has achieved a sustained fiscal surplus without being in default. We are one of only 5 countries in the world in this position.
LONG LIVE FREEDOM, DAMN IT...!!!
437
7,492
58,149
1,097,076
Ben Longmier retweeted

May 10
It’s time to America-maxx. 🇺🇸💪🚀
May 9

It’s time to America-maxx.
54
231
1,987
384,152
Ben Longmier retweeted

To clarify, the current terminals can support peak download speeds of 400-500 Mbps. The 220 Mbps number is referring to actual in-flight performance given that the satellite to user beams are shared amongst users. For larger commercial planes, we allocate more resources to ensure sufficient bandwidth.
Other providers quote peak speeds as real performance, which is only relevant if you have very few users. @starlink quotes real performance measured via automated network performance tests.
The latest aviation terminal supports two channels, so up to 1 Gbps peak speeds per terminal (the A380 design consists of 3 of these terminals). We will continue to increase peak bandwidth per terminal in future revisions.
167
689
2,971
780,448
Apr 25
What an amazing showcase of the excellence that is the @SpaceX team.

Three years since the first flight of Starship, the next generation is here. New ship. New booster. New engines. New pad and new test site. SpaceX engineers are working to solve one of the most difficult engineering challenges in history: developing a fully, rapidly reusable rocket
4
2
149
3,800
Apr 1
A very smart friend asked if I’d consider helping look at AI. I’ve literally never read about it and know nothing. Anyone have some good/fun resources?
So far I’ve read The Road to Modern AI by @SchmidhuberAI
(Great context, and so many good references)
arxiv.org/pdf/2212.11279
Starting in on these videos next from @karpathy
youtube.com/playlist?list=PL…
I’m extremely dumb in all these topics, but it does strike me that the brute force method of fully dense LLMs being slammajammed through warehouses of GPUs that do matrix math layer by layer is a fools errand in terms of seconds of memory calls and Joules spent computing weights for mostly meaningless/empty nodes.
- 1-bit weights seem cute, but biology seems to play a few other clever tricks. There is more here.
- Mixture of experts seem cute, but basically a linear hack. Not meaningful enough.
- Batching is efficient, but only for multiple user requests and only in data centers.
There has to be a better way for a node in one layer to communicate to a node in a separate layer without waiting for the whole silly layer to finish its matrix math.
For sure evolving the software and hardware simultaneously is the only way.
@xai is doing this.
@GeminiApp is doing this.
Anyone else?
Announcing Terafab: the next step towards becoming a galactic civilization
x.com/i/broadcasts/1yKAPMzlv…
7
3
37
4,598
Apr 1
This seems like a great idea. I am running it on my phone and it is super fast for such a small model!
Seems like this 1-bit model weight idea has been out since 2016.
arxiv.org/pdf/1511.00363
Just think of what else is lurking out in the literature, just around the corner !

Today, we are emerging from stealth and launching PrismML, an AI lab with Caltech origins that is centered on building the most concentrated form of intelligence.
At PrismML, we believe that the next major leaps in AI will be driven by order-of-magnitude improvements in intelligence density, not just sheer parameter count.
Our first proof point is the 1-bit Bonsai 8B, a 1-bit weight model that fits into 1.15 GBs of memory and delivers over 10x the intelligence density of its full-precision counterparts. It is 14x smaller, 8x faster, and 5x more energy efficient on edge hardware while remaining competitive with other models in its parameter-class.
We are open-sourcing the model under Apache 2.0 license, along with Bonsai 4B and 1.7B models.
When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately. We believe in a future of on-device agents, real-time robotics, offline intelligence and entirely new products that were previously impossible.
We are excited to share our vision with you and keep working in the future to push the frontier of intelligence to the edge.

2
21
3,056
Apr 1
I really like this @PrismML work (congrats). I downloaded their model to run on my iPhone 17 air, and it’s snappy as hell!
The question isn’t what happens to people that spent 14x more on data centers than they needed to. The question is what happens when those same data centers run their own 1-bit models that are 14x more efficient on the same maxed out power.
Ain’t no one going to turn down the power knob…only max the knob to 11 to compete with all other AI groups.
Apr 1

The real story is the 14x compression ratio and what it means if it scales up.
Every single weight in this model is one bit. Zero or one. That's it. 8.2 billion parameters stored in 1.15 GB of memory. A standard 8B model at full precision takes 16 GB. Bonsai 8B fits on your phone with room left over for your photo library.
The benchmarks are the part that shouldn't be possible. On standard evals, a model that's 1/14th the size of Qwen3 8B and Llama3 8B is trading punches with both of them. The intelligence density score, capability per GB, is 1.06/GB versus Qwen3 8B at 0.10/GB. That's a 10x gap in how much thinking you get per unit of storage.
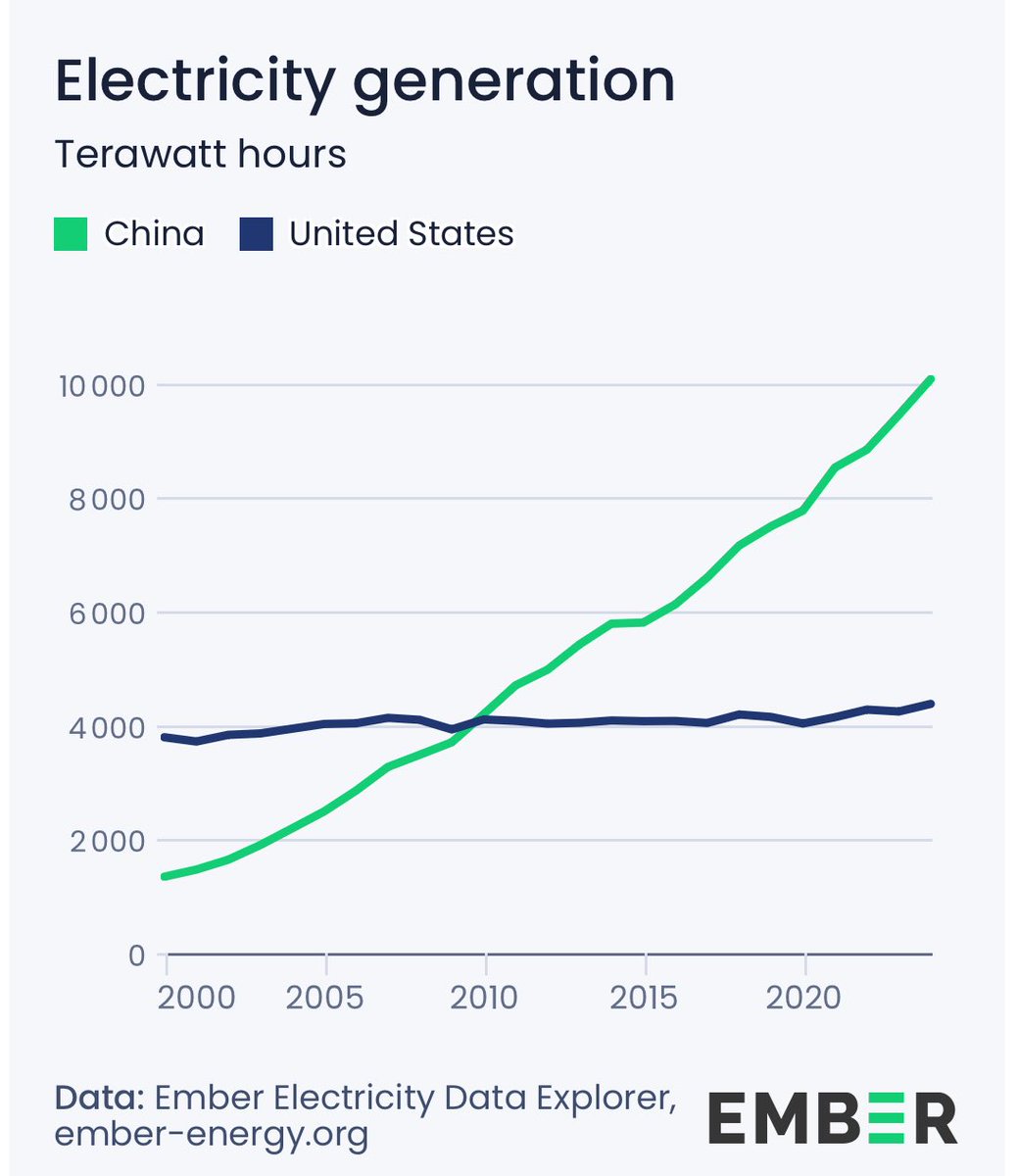
Now zoom out. Big Tech collectively spent over $320 billion on data center capex last year. Amazon alone dropped $85.8 billion, up 78% year over year. Google committed $75 billion for 2025. The US power grid is buckling under AI demand. Data centers now consume 4.4% of all US electricity. Virginia, where most of them sit, saw electricity prices spike 267% over five years. Residential customers in Ohio are watching their bills climb 60% because utilities are spending billions on transmission infrastructure to feed server farms.
The entire AI scaling thesis runs on one assumption: intelligence requires massive compute. PrismML just published a proof point that the assumption might be wrong. Their CEO, Babak Hassibi, is a Caltech professor who spent years on the mathematical theory of neural network compression. The founding team is four Caltech PhDs. Khosla Ventures backed it. So did Cerberus, whose Amir Salek built the TPU program at Google.
The 1.7B model runs at 130 tokens per second on an iPhone 17 Pro Max at 0.24 GB. The 4B hits 132 tokens per second on M4 Pro at 0.57 GB. These aren't research demos. They shipped llama.cpp forks with custom 1-bit kernels for CUDA and Metal. Apache 2.0 license. You can download and run it right now.
The trillion-dollar question: what happens to the economics of a $75 billion data center budget when the same intelligence fits in 1/14th the space and runs on 1/5th the energy?
2
20
2,247
Mar 27
Someday moon dog will speak for himself.
I hope we train him well.
2
1
18
1,099
Mar 26
Congrats Xona!
Time to build the next generation of GNSS
Mar 26

Proof on orbit means of deployment = the world's first commercial satellite navigation constellation
Our $170M in Series C funding marks the start of scaled manufacturing for our in-house satellite at our new Burlingame facility to launch our entire constellation over the coming years.

1
3
25
2,743
Mar 22
Palo Alto today.
I can’t wait for these robotaxis to totally take over Ubers (those drivers are not very skilled anymore). My Tesla FSD is better than 99% of Uber drivers these days.
21
18
255
23,723
Mar 16
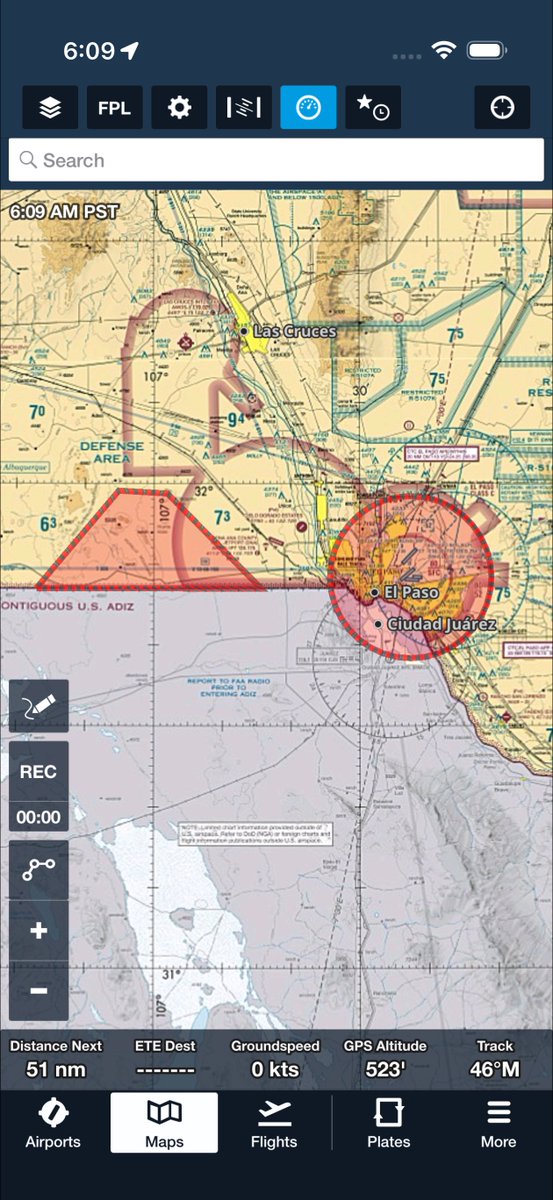
Beautiful day in California for a solo flight up to Point Reyes, Bodega Bay, and where the Russian River meets the Pacific.



6
2
65
2,675
Mar 2
Two orders of magnitude improvement in Direct to Cell (now called @Starlink Mobile) for V2. Huge improvement and amazing forthcoming work by the Starlink team.

Starlink Mobile is providing data for video, voice, and messaging services in areas where terrestrial service is unavailable
Working with global mobile network operators, our satellite-to-mobile network has grown to 32 countries, home to 1.7B people → starlink.com/mobile
194
551
2,931
954,810