
Joined March 2015
- Tweets 326
- Following 190
- Followers 322
- Likes 1,008
21 Photos and videos






Pinned Tweet

16 May 2025
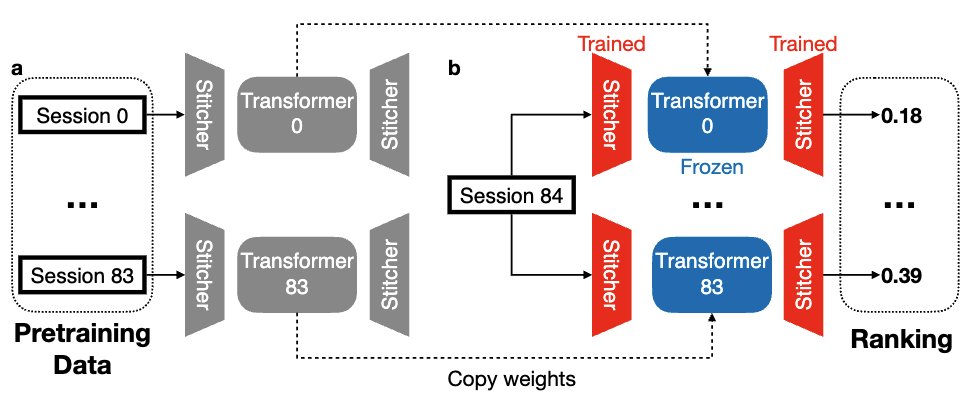
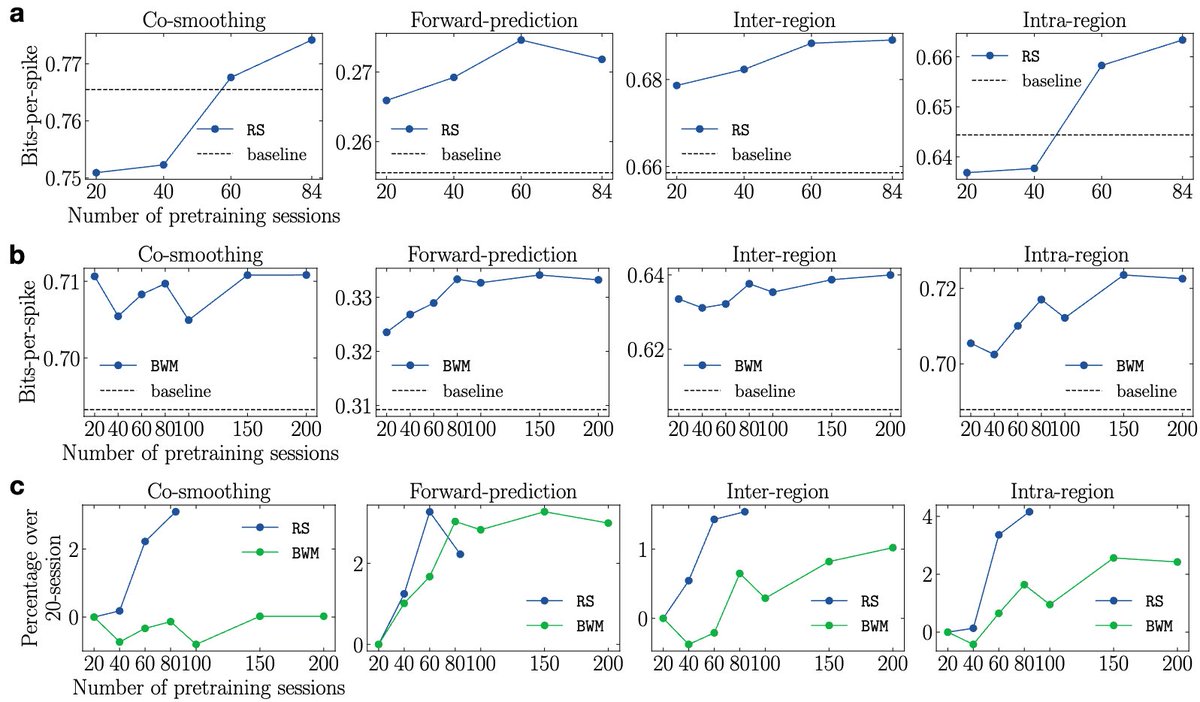
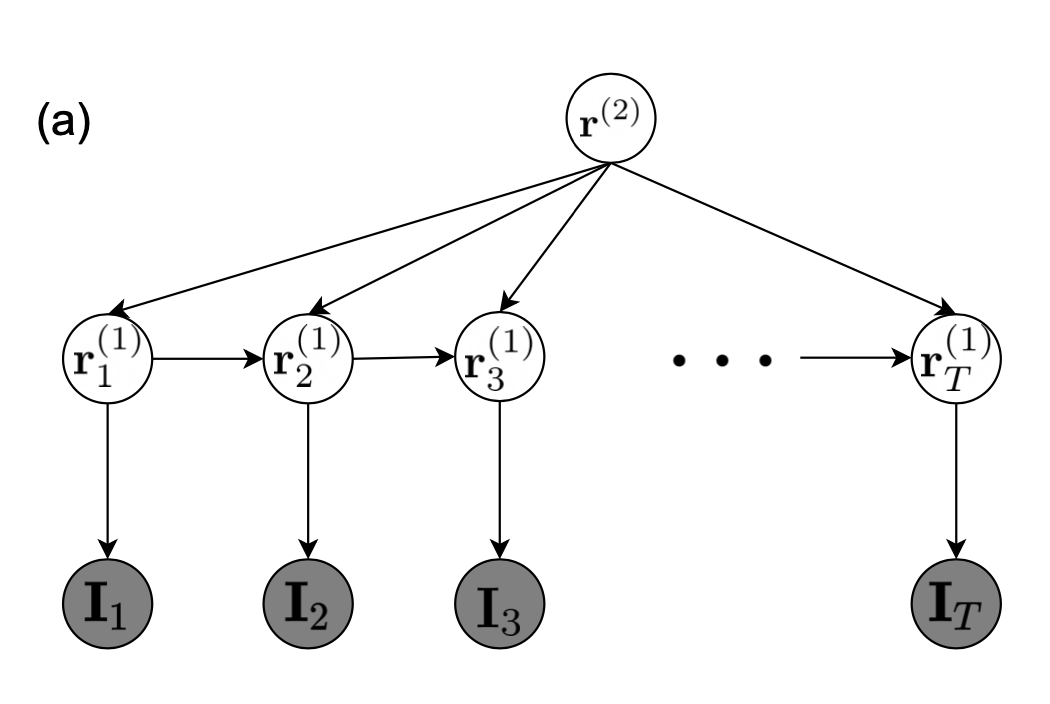
I'm excited to share our latest work — "Data Heterogeneity Limits the Scaling Effect of Pretraining in Neural Data Transformers", where we examined the effect of scaling up pretraining data in neural foundation models carefully.🧐 (1/9)
Preprint: biorxiv.org/content/10.1101/…
1
13
33
10,680
Linxing Preston Jiang retweeted

9 Dec 2025
Can we simplify video generation by decomposing it into interleaved text-video co-generation?
Would explicit, repeated thinking in language improve generation in pixels?
We introduce TV2TV: a unified model that jointly learns
- language modeling (next-token prediction)
- video flow matching (next-frame prediction)
At inference, TV2TV dynamically alternates between textual thinking and video generation.
Model generations below: interleaved text plans and video slices (~1–2s) are co-generated over time, conditioned on a single frame per sport.
📖 arxiv.org/abs/2512.05103
4
39
93
29,082
7 Oct 2025
Find @WeijiaShi2 at @lm4sci Oct 10 for our latest work on neuro foundation model data scaling!
7 Oct 2025

Data Heterogeneity Limits the Scaling Effect of Pretraining Neural Data Transformers led by @lpjiang97
⏰: Oct 10, 11:30am
📌: 524A
1
4
314
Linxing Preston Jiang retweeted

7 Oct 2025
At #COLM2025 🇨🇦 this week! Would love to meet old and new friends.
I’ve been thinking about how to train LMs that can leverage high-risk but high-quality data, and how to build omni models by merging specialized ones across modalities.
And come check out our paper 👇
2
10
100
12,079
Linxing Preston Jiang retweeted

12 Sep 2025
(1/8) New paper from our team!
@yuven_duan & @hamzatchaudhry introduce POCO, a tool for FORECASTING brain activity at the cellular & network level during spontaneous behavior.
Find out how we built POCO & how it will transform neurobehavioral research 👇
arxiv.org/abs/2506.14957

5
19
65
8,684
Linxing Preston Jiang retweeted

5 Aug 2025
Today’s AI assistants passively wait for questions. But what if they could anticipate when to help-without explicit user invocation? Meet LlamaPIE, the first real-time proactive assistant to enhance conversations via discreet, concise guidance delivered by hearable.#acl2025

2
4
9
1,293
Linxing Preston Jiang retweeted

25 Jul 2025
I've been writing some AI Agents lately and they work much better than I expected. Here are the 10 learnings for writing AI agents that work:
1) Tools first. Design, write and test the tools before connecting to LLMs. Tools are the most deterministic part of your code. Make sure they work 100% before writing actual agents.
2) Start with general, low level tools. For example, bash is a powerful tool that can cover most needs. You don't need to start with a full suite of 100 tools.
3) Start with single agent. Once you have all the basic tools, test them with a single react agent. It's extremely easy to write a react agent once you have the tools. All major agent frameworks have builtin react agent. You just need to plugin your tools.
4) Start with the best models. There will be a lot of problems with your system, so you don't want model's ability to be one of them. Start with Claude Sonnet or Gemini Pro. you can downgrade later for cost purpose.
5) Trace and log your agent. Writing agents are like doing animal experiments. There will be many unexpected behavior. You need to monitor it as carefully as possible. There are many logging systems that help. Langsmith, langfuse etc.
6) Identify the bottlenecks. There's a chance that single agent with general tools already works. But if not, you should read your logs and identify the bottleneck. It could be: context length too long, tools not specialized enough, model doesn't know how to do something etc.
7) Iterate based on the bottleneck. There are many ways to improve: switch to multi agents, write better prompts, write more specialized tools etc. Choose them based on your bottleneck.
8) You can combine workflows with agents and it may work better. If your objective is specialized and there's an unidirectional order in that process, a workflow is better, and each workflow node can be an agent. For example, a deep research agent can be a two step workflow, first a divergent broad search, then a convergent report writing, and each step is an agentic system by itself.
9) Trick: Utilize filesystem as a hack. Files are a great way for AI Agents to document, memorize and communicate. You can save a lot of context length when they simply pass around file urls instead of full documents.
10) Another Trick: Ask Claude Code how to write agents. Claude Code is the best agent we have out there. Even though it's not open sourced, CC knows its prompt, architecture and tools. You can ask its advice for your system.
1
6
361
Linxing Preston Jiang retweeted

18 Jul 2025
A new study led by @timothy_sit shows that different layers of mouse V1 integrate visual and non-visual signals differently. L2/3 activity is dominated by vision (or spontaneous fluctuations) and L5 by movement. This leads to different geometries.
biorxiv.org/content/10.1101/…
14
56
3,061
9 Jul 2025
Exciting work on flexible data usage in MoE LMs!
9 Jul 2025
Can data owners & LM developers collaborate to build a strong shared model while each retaining data control?
Introducing FlexOlmo💪, a mixture-of-experts LM enabling:
• Flexible training on your local data without sharing it
• Flexible inference to opt in/out your data anytime
At 37B parameters, FlexOlmo is competitive across 31 tasks.
169
16 May 2025
I'm excited to share our latest work — "Data Heterogeneity Limits the Scaling Effect of Pretraining in Neural Data Transformers", where we examined the effect of scaling up pretraining data in neural foundation models carefully.🧐 (1/9)
Preprint: biorxiv.org/content/10.1101/…
1
13
33
10,680
16 May 2025
Together, our results show that pretraining with more sessions does not naturally lead to improved downstream performance. We advocate for rigorous scaling analyses in future work on neural foundation models to account for data heterogeneity effects. (8/9)
1
1
304
16 May 2025
This is joint work with @ChinSengi, Iman Tanumihardja, @XiaochuangHan, @WeijiaShi2, Eric Shea-Brown, and @RajeshPNRao. Please check out the preprint for more details.
Any feedback is appreciated! (9/9)
2
278
Linxing Preston Jiang retweeted
16 Apr 2025
Our previous work showed that 𝐜𝐫𝐞𝐚𝐭𝐢𝐧𝐠 𝐯𝐢𝐬𝐮𝐚𝐥 𝐜𝐡𝐚𝐢𝐧‑𝐨𝐟‑𝐭𝐡𝐨𝐮𝐠𝐡𝐭𝐬 𝐯𝐢𝐚 𝐭𝐨𝐨𝐥 𝐮𝐬𝐞 significantly boosts GPT‑4o’s visual reasoning performance. Excited to see this idea incorporated into OpenAI’s o3 and o4‑mini models (openai.com/index/thinking-wi…).
Huge thanks to my co‑author @huyushi98 @XingyuFu2
30 Sep 2024
Visual Chain-of-Thought with ✏️Sketchpad
Happy to share ✏️Visual Sketchpad accepted to #NeurIPS2024. Sketchpad thinks🤔by creating visual reasoning chains for multimodal LMs, enhancing GPT-4o's reasoning on math and vision tasks
We’ve open-sourced code: visualsketchpad.github.io

5
40
253
26,774
Linxing Preston Jiang retweeted

4 Mar 2025
I'm honored and humbled to receive the @IBM Ph.D. fellowship! Thank you to my advisor @_doctor_kat, all my friends, mentors and collaborators at and outside @UW for their support and inspiration that push me to grow!! Congrats @shangbinfeng for the fellowship too!! #UWAllen
3 Mar 2025

#UWAllen @UW’s @shangbinfeng champions multi-#LLM collaboration; fellow student @rockpang6 uncovers the unintended consequences of #AI and other emerging technologies. Both were recently honored with @IBM Ph.D. Fellowships: news.cs.washington.edu/2025/… #MondayMotivation #ThisisUW
5
2
95
5,562
Linxing Preston Jiang retweeted

8 Jan 2025
Excited to share my intern project at Salesforce Research! Huge thanks to everyone on the team!!
8 Jan 2025

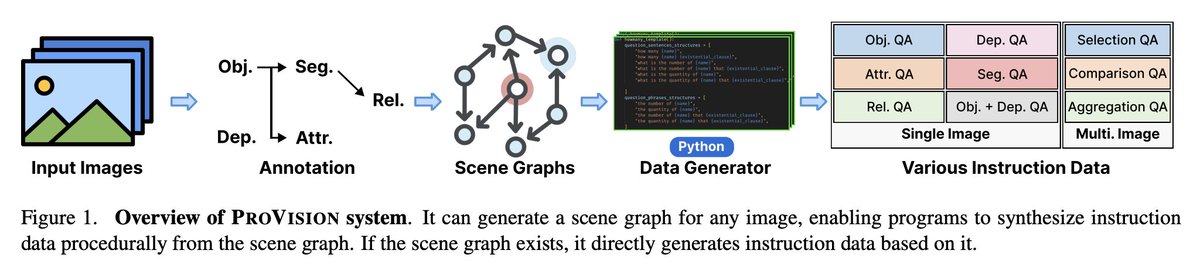
🔬🔬🔬Introducing ProVision: A new system for transforming images into verified instruction data for multimodal language models (MLMs) at massive scale!
Scene graphs programmatic synthesis generate 10M diverse, automated Q&A pairs. Fully verifiable.
Training MLMs? Dive in:
📰Blog: sforce.co/3WazqHi
🗞️Paper: bit.ly/4jkoocL
💻Dataset: bit.ly/4j2IojR
👇Researcher’s 🧵👇
(1/6) Why build ProVision?
Training multimodal LMs demands massive instruction datasets - pairing images with Q&As. Manual creation is costly, while using existing models risks hallucinations.
ProVision's novel solution? Scene graphs human-written programs. We represent images as structured graphs capturing objects, attributes & relationships. We then use Python programs and textual templates, our data generators synthesize instruction data by creating questions and answers from the scene graph.
👇🧵 for more...
14
81
12,191