
Assistant professor at @Stanford and member of the technical staff at @AnthropicAI.
Joined August 2009
- Tweets 246
- Following 427
- Followers 6,380
- Likes 1,530
3 Photos and videos
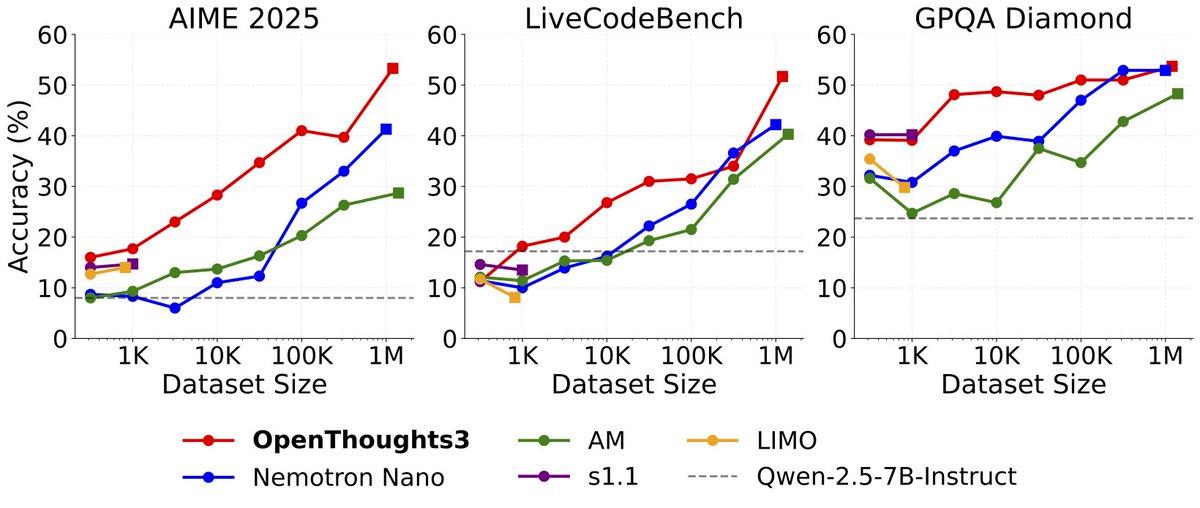

Ludwig Schmidt retweeted

May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵

16
111
495
905,353
Ludwig Schmidt retweeted

May 19
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
7,988
11,152
150,236
27,564,235
Ludwig Schmidt retweeted

May 19
Excited to welcome Andrej to the Pretraining team! He'll be building a team focused on using Claude to accelerate pretraining research itself. I can’t think of anyone better suited to do it — looking forward to what we build together!
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
61
153
4,451
337,923
Ludwig Schmidt retweeted

We're releasing Terminal-Bench 2.1 to patch 28 of the 89 tasks in Terminal-Bench 2.0
TB2.1 includes
• recalibrated limits
• fixed solutions
• realigned verifiers
Per-task breakdowns in 🧵
We'll continue to support TB2 and TB2.1 leaderboards (new submission process 🔜)

2
12
53
14,703
Ludwig Schmidt retweeted

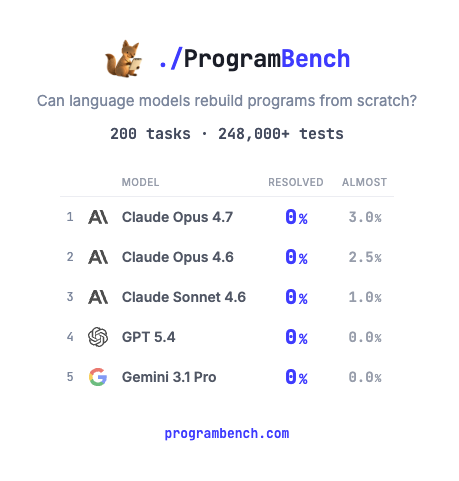
May 5
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
104
246
1,576
728,378
Ludwig Schmidt retweeted

Apr 27
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
201
456
3,622
1,421,026
Ludwig Schmidt retweeted

Apr 27
New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
178
396
3,153
1,180,491
Ludwig Schmidt retweeted

Mar 6
A statement from Anthropic CEO Dario Amodei: anthropic.com/news/where-sta…
1,089
714
5,499
2,702,326
Ludwig Schmidt retweeted
Feb 28
A statement on the comments from Secretary of War Pete Hegseth.
anthropic.com/news/statement…
2,813
6,507
42,335
17,771,026
Ludwig Schmidt retweeted

Feb 17
Releasing the official SkyRL Harbor integration: a standardized way to train terminal-use agents with RL.
From the creators of Terminal-Bench, Harbor is a widely adopted framework for evaluating terminal-use agents on any task expressible as a Dockerfile instruction test script.
This integration extends it: the same tasks you evaluate on, you can now RL-train on.
Blog: novasky-ai.notion.site/skyrl…
🧵

9
46
244
34,552
Ludwig Schmidt retweeted

Feb 20
Terminal-Bench is a leading benchmark for agents. Unfortunately it’s hard: most small coding agents get very low scores on TB2, so training/system ablations look flat - you can't tell what's working.
Announcing OpenThoughts-TBLite - 100 curated TB2-style tasks, difficulty-calibrated so even 8B models can make progress. It's designed to give researchers measurable signal during development, providing faster feedback for experimental iteration while closely tracking true TB2 performance🧵

11
21
182
45,586
Ludwig Schmidt retweeted

17
83
329
148,844
Ludwig Schmidt retweeted

Jan 22
The Terminal-Bench paper is here! Read it to learn where frontier models still fail and the secrets of how we sourced hundreds of high quality environments from our open source community. 🧵

21
102
458
103,745
Ludwig Schmidt retweeted

6 Dec 2025
Building TerminalBench agents in the open is hard. We're making it much easier. OpenThoughts-Agent is our first milestone in open-data pipelines for building agents. We're the best model of our size on TerminalBench 2.0.
We're pushing both SFT and RL pipelines for building agents. I'm so excited to see where this project goes!
Check it out!
6 Dec 2025

How can we make a better TerminalBench agent?
Today, we are announcing the OpenThoughts-Agent project.
OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments.
OpenThinker-Agent-v1 is the strongest model of its size on TerminalBench, and sets a new bar on our newly released OpenThoughts-TB-Dev benchmark. (1/n)

5
13
48
14,067
Ludwig Schmidt retweeted

6 Dec 2025
How can we make a better TerminalBench agent?
Today, we are announcing the OpenThoughts-Agent project.
OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments.
OpenThinker-Agent-v1 is the strongest model of its size on TerminalBench, and sets a new bar on our newly released OpenThoughts-TB-Dev benchmark. (1/n)
17
77
288
127,177
Ludwig Schmidt retweeted

24 Nov 2025
Introducing the new Stanford CS Ph.D. Entrepreneurship Club: Saplings🌲🌲!! We're a community for Computer Science PhD students at Stanford to help them turn their innovative ideas into impactful startups, alongside fellow founders and industry leaders. We're going to have many exciting events soon, so stay tuned!
2
5
40
19,691
Ludwig Schmidt retweeted

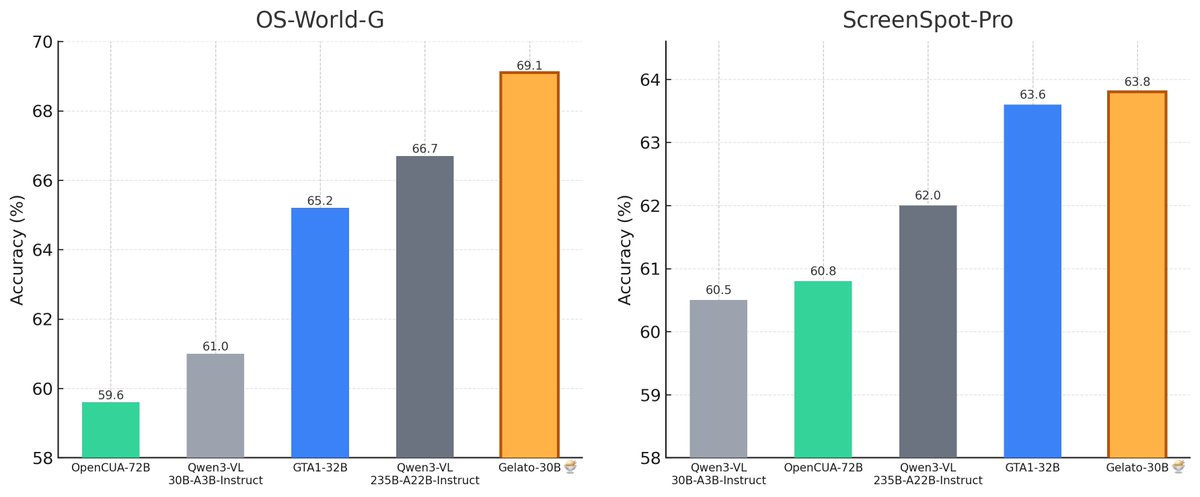
10 Nov 2025
We're releasing🍨Gelato-30B-A3B, a state-of-the-art computer grounding model that delivers immediate performance gains for computer-use agents!
Trained on our open-source🖱️Click-100k dataset, Gelato achieves 63.8% on ScreenSpot-Pro and 69.1% on OS-World-G. It outperforms specialized models like GTA1-32B and VLMs ~8× its size like Qwen3-VL-235B.
(1/N) 🧵
7
41
233
34,381
Ludwig Schmidt retweeted

7 Nov 2025
Today, we’re announcing the next chapter of Terminal-Bench with two releases:
1. Harbor, a new package for running sandboxed agent rollouts at scale
2. Terminal-Bench 2.0, a harder version of Terminal-Bench with increased verification

27
72
395
144,229
Ludwig Schmidt retweeted
5 Nov 2025
New eval! Code duels for LMs ⚔️
Current evals test LMs on *tasks*: "fix this bug," "write a test"
But we code to achieve *goals*: maximize revenue, cut costs, win users
Meet CodeClash: LMs compete via their codebases across multi-round tournaments to achieve high-level goals
31
99
417
102,918
Ludwig Schmidt retweeted
16 Jul 2025
Evaluating agents on benchmarks is a pain. Each benchmark comes with its own harness, scoring scripts, and environments and integrating can take days.
We're introducing the Terminal-Bench dataset registry to solve this problem. Think of it as the npm of agent benchmarks.
Now you can use the Terminal-Bench CLI and harness to evaluate on SWE-bench and other popular benchmarks.
1
22
104
13,637