
Kaggleとかディープの事とかをつぶやきます
Joined July 2017
- Tweets 510
- Following 1,036
- Followers 2,244
- Likes 3,360
22 Photos and videos








Lyaka retweeted

Apr 7
JAMMEvalの評価のために開発したVLM評価フレームワークsimple-evals-mmの紹介ブログ記事も書いたのでぜひご覧ください💁
speed1313.github.io/posts/si…
Apr 6

JAMMEvalという信頼性の高い日本語VQA評価データセットコレクションを公開しました!
我々は、既存の日本語ベンチマークに含まれる曖昧性や正答例の誤りなどの不良事例を2ラウンドにわたる人手の修正を施すことで、JAMMEvalを構築しました。
公開したデータセット・評価コードをぜひご活用ください!

2
10
1,716

Sierra に Agent Engineer として join しました!
オンボーディングでサンフランシスコに来ていますが、みんな本当に優秀で親切な人ばかりで、毎日刺激を受けています。
ここからさらに大きくしていくフェーズなので、Agent 開発も採用も頑張っていきます🚀
Mar 27

I’m excited to announce that Sierra has acquired Opera Tech in Japan.
Opera’s co-founders, Keita Morikawa and Kiyo Kunii, started the company with the simple idea that AI could help businesses deliver high-quality customer experiences at scale. We’re so excited to have them join us to lead Sierra in Japan. sierra.ai/blog/sierra-acquir…

13
9
213
22,440


某所で80人に向けたコーディングエージェントの研修をしました。研修資料を公開します。
speakerdeck.com/watany/agent…
172
1,804
601,286
Lyaka retweeted

18 Dec 2025
LINEヤフー、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を開発 商用利用もOK
itmedia.co.jp/aiplus/article…
93
499
90,774
日本語CLIPの新バージョンを公開しました!蒸留とデータ増強でかなりパワーアップしてます!
今回もApache 2.0なのでぜひ色々な場面で使ってください!
🤗: huggingface.co/line-corporat…
18 Dec 2025

LINEヤフー Tech Blog 🆕
『高性能な日本語マルチモーダル基盤モデル「clip-japanese-base-v2」の公開』
- 日本語特化CLIPを高性能化し公開
- 大規模データ収集と精密フィルタによる精度の底上げ
- 知識蒸留によるさらなる精度改善
techblog.lycorp.co.jp/ja/202…
47
261
36,903
Lyaka retweeted

25 Nov 2025
LINEヤフー Tech Blog🆕
「コンピュータビジョンの最難関国際会議 ICCV 2025に論文およびワークショップが採択されました」
- 最難関国際会議ICCV2025への論文採択・参加報告
- 基盤「データ」に関する国際ワークショップ開催
- デザイン x コンピュータビジョンの最先端調査
techblog.lycorp.co.jp/ja/202…
7
23
15,191
めちゃくちゃ参考になる記事。この辺の話辛すぎて先延ばしにしてたから本当にありがたい🙏
19 Nov 2025

NVIDIA NeMoを利用したgpt-ossの学習方法について記事を執筆しました
NGCコンテナ内のTransformerEngine、cuDNN versionのupdateだけでなく、NeMo側の実装、Megatron-Coreの実装も修正する必要がありました
LLMの研究開発において実は大変なライブラリ整備に関する記事です
zenn.dev/turing_motors/artic…
1
1
19
5,753
Lyaka retweeted
28 Oct 2025
大規模かつ高品質な日本語画像テキスト対データセットのWAONを公開しました!🇯🇵
新たに構築した日本文化画像分類ベンチマークWAON-BenchにおいてWAONはReLAIONより効率的にモデルの性能を向上させ、SoTAの性能を達成することを示しています。
ブログ記事もぜひご覧ください!
speed1313.github.io/posts/WA…
28 Oct 2025
We introduce WAON, a large-scale and high-quality Japanese image–text dataset comprising 155M pairs.
Fine-tuning SigLIP2 on WAON improves performance on Japanese cultural benchmark WAON-Bench more efficiently than using ReLAION, achieving SoTA.
Try WAON now! 🇯🇵📷
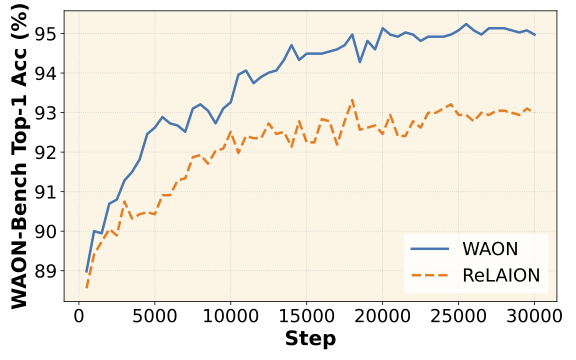
1
29
122
22,567
DeepSeek-OCRの文書をそのままビジョントークンとして圧縮するという話は、長いコンテキストを扱うのが得意なGeminiでも似たようなことをやっているかもという推測
たしかに有り得そう
20 Oct 2025

DeepSeek just released a pretty shocking new paper. They really buried the lede here by referring to it simply as DeepSeek OCR.
While it’s a very strong OCR model, the purpose of it and the implications of their approach go far beyond what you’d expect of “yet another OCR model.”
Traditionally, vision LLM tokens almost seemed like an afterthought or “bolt on” to the LLM paradigm. And 10k words of English would take up far more space in a multimodal LLM when expressed as intelligible pixels than when expressed as tokens.
So those 10k words may have turned into 15k tokens, or 30k to 60k “visual tokens.” So vision tokens were way less efficient and really only made sense to use for data that couldn’t be effectively conveyed with words.
But that gets inverted now from the ideas in this paper. DeepSeek figured out how to get 10x better compression using vision tokens than with text tokens! So you could theoretically store those 10k words in just 1,500 of their special compressed visual tokens.
This might not be as unexpected as it sounds if you think of how your own mind works. After all, I know that when I’m looking for a part of a book that I’ve already read, I imagine it visually and always remember which side of the book it was on and approximately where on the page it was, which suggests some kind of visual memory representation at work.
Now, it’s not clear how exactly this interacts with the other downstream cognitive functioning of an LLM; can the model reason as intelligently over those compressed visual tokens as it can using regular text tokens? Does it make the model less articulate by forcing it into a more vision-oriented modality?
But you can imagine that, depending on the exact tradeoffs, it could be a very exciting new axis to greatly expand effective context sizes. Especially when combined with DeepSeek’s other recent paper from a couple weeks ago about sparse attention.
For all we know, Google could have already figured out something like this, which could explain why Gemini has such a huge context size and is so good and fast at OCR tasks. If they did, they probably wouldn’t say because it would be viewed as an important trade secret.
But the nice thing about DeepSeek is that they’ve made the entire thing open source and open weights and explained how they did it, so now everyone can try it out and explore.
Even if these tricks make attention more lossy, the potential of getting a frontier LLM with a 10 or 20 million token context window is pretty exciting.
You could basically cram all of a company’s key internal documents into a prompt preamble and cache this with OpenAI and then just add your specific query or prompt on top of that and not have to deal with search tools and still have it be fast and cost-effective.
Or put an entire code base into the context and cache it, and then just keep appending the equivalent of the git diffs as you make changes to the code.
If you’ve ever read stories about the great physicist Hans Bethe, he was known for having vast amounts of random physical facts memorized (like the entire periodic table; boiling points of various substances, etc.) so that he could seamlessly think and compute without ever having to interrupt his flow to look something up in a reference table.
Having vast amounts of task-specific knowledge in your working memory is extremely useful. This seems like a very clever and additive approach to potentially expanding that memory bank by 10x or more.
1
10
2,710

最近やっていた仕事です
Vespaを活用したYahoo!フリマのベクトル検索 —— 類似画像で広がる商品探索 techblog.lycorp.co.jp/ja/202…
15
70
8,036
弊チームのサマーインターンの募集です!
大規模な社内の画像データを使ったVLMの研究開発ができて楽しいと思うのでぜひ!
lycorp.co.jp/ja/recruit/newg…
13
55
8,249
Lyaka retweeted

8 Mar 2025
月曜日からNLP2025に参加します!
以下の論文を発表する予定で、内容は
1. 日本語MLLMで既存の公開モデルの精度を上回るものができたこと
2. 新しく作成したJIC-VQAベンチマーク
についてになります。
JIC-VQA:
huggingface.co/datasets/line…
論文プロジェクページ:
mikittt.github.io/posts/Japa…
#NLP2025
2
14
106
19,173
Lyaka retweeted

6 Mar 2025
3月7日はサウナの日です!ということでサウナ企画!実はサウナーの弊社代表@fukkyy や @y_matsuwitter のおすすめサウナも紹介しています!是非見てみてください!🤟
--
LayerXメンバーが選ぶおすすめサウナ #日めくりLayerX|Shimomura Eisaku @eisaku9393 #note note.com/jolly_koala293/n/n7…
8
25
21,713
Lyaka retweeted
5 Feb 2025
#NLP2025 3月11日(火) 13:00-14:30 Q3で、日本語のマルチモーダル大規模言語モデルの開発に関するポスター発表をします。
興味のある方はぜひ来てください!
5 Feb 2025

🎉大会プログラム公開🎉
#NLP2025 の発表件数は778件と、過去最多!プログラム委員会で調整を重ねて口頭発表・ポスター発表ともテーマごとに分類し、座長や聴講者と共に活発な議論ができるようセッションを組み立てました。プログラムはこちらからご確認ください。
anlp.jp/proceedings/annual_m…
1
20
3,261
Lyaka retweeted

5 Feb 2025
ベールに包まれてたベイスターズを支えるAI活用いっぱい話すよ⚾️(16:00〜)
ここから見れます!
techcon2025.dena.dev
9 Dec 2024

//
#ベイスターズ を支えるAI技術をついに公開⚾️
DeNA × AI Day || TechCon セッション紹介✨
\\
捕手の成長、投手の復活、球界屈指の強力打線。
その裏にはDeNAのAI技術があります。
DeNAのスポーツ事業戦略と合わせてご紹介!
#DeNAxAI_Day #denatechcon
techcon2025.dena.dev/session…
1
2
19
2,671
Lyaka retweeted

4 Dec 2024
同じ部の基盤モデルチームがありえん強いCLIP拡張モデルを作ってプロダクト応用ガッツリ進めている話😤
自社開発のマルチモーダル基盤モデルを用いたYahoo!オークションの出品審査効率化 techblog.lycorp.co.jp/ja/202…
9
112
8,554
#ViEW2024 の特別講演2のセッションにてVLMのお話をします。
VLM開発の話、ヤフオクでの事業応用事例の紹介、実応用における課題や解決策の話など、盛りだくさんの内容になっていると思います。
一時間という長尺ですがぜひ!
30 Sep 2024

2
23
3,912
Lyaka retweeted

3 Nov 2024
If you are curious how Multimodal LLMs work, I wrote a new article to explain the two main approaches, decoder-only- and cross-attention-style: magazine.sebastianraschka.co…
Plus, I reviewed and summarized the 10 latest research papers to see how it's done in practice.
Happy reading!
34
305
1,497
77,907