
1.005x dev terrified of AI, building anyway... waste.watch observersprotocol.com | dev isn't enough, full stack engineer is the goal.
Joined December 2015
- Tweets 561
- Following 123
- Followers 45
- Likes 477
128 Photos and videos












Pinned Tweet

Feb 22
Turning ideas into reality.. design, build, ship
Just getting started!!
3
4,104
May 21
I just stumbled across this post on Team-BHP and I’m shook 😮
how do these service centres not have a strict, non-negotiable checklist they’re forced to follow before handing the motorcycle back to the customer?!
share.google/1nE4snxoETAhkl2…
1
107
Manu retweeted

May 17
Absolutely FUCK THIS. Just fucking call it. Let's go home. Fuck 'the show,' fuck the TV broadcast, fuck whoever thinks that riders are just disposable things to use up. Which actual race fan wants to see this AGAIN?
110
207
1,458
116,453
May 17
😒 another red flag.... now it's Zarco... another nasty incident, he got tangled up with the bike 👀...
#Motogp #CatalanGP
1
1,390


May 14
Free stuff 👀.... with claude’s rate limits.… 2 months of free Codex would definitely help lol...
May 14

We heard you like free stuff 👀
How’s 2 months of free Codex for your entire team?
Go forth and build things 😁
openai.com/form/codex-enterp…
136
May 13
SDLC Post LLM:
1) Vibe planning.
2) Vibe coding.
3) Vibe refactoring/reviewing.
4) Vibe debugging.
5) Decide the codebase is “architecturally limiting.”
6) Start a new repo called final-final-v2-actually-this-one.
7) Repeat until one project accidentally becomes a startup.
✌️
2
207
May 10
418
May 9
1
264
May 7
these from Genesis AI are the closest I’ve seen to real world physical intelligence.
...hand movements, material handling, motion patterns, and scene understanding.. feel insanely natural.
we’re watching the sim-to-real gap disappear in real time🤯x.com/gs_ai_/status/20520509…
160
Manu retweeted

May 2
Warren Buffett at Berkshire’s 2026 AGM talking about waiting to deploy its $397B cash pile:
“I’ve compared the markets to the church with a casino attached. People can move between the church and the casino. The casino has gotten very attractive to people. If you’re buying one-day options, it’s not investing or speculating. It’s gambling. We’ve never had more people in a gambling mood…Prices for a lot of things look very silly.”
Says Greg Abel and Berkshire are still always “a phone call away” from making a massive investment.
“We’re big enough to handle anything. We make decisions faster than anybody. And our word if good.”
44
106
1,234
274,034
Apr 30
What I can't understand is why these people never fix the problems before they blow up, but the moment tragedy strikes, they come in front of the cameras acting like saviors. They announce 'compensation' as if it's coming from their personal bank accounts...
have they no shame at all? they're the ones.. directly or indirectly who created or allowed this mess in the first place. What kind of pathetic, clown-world mindset is this??
Apr 30

Yesterdays rains shows we should fix the drainage systems first and then talk about becoming world class city . Not able handle 1 heavy rain . Not a sign of Bruhat Bangalore #BBMP #NammaBangalore #Nammakarnataka
1
278
Apr 26
who will tell him 👀 ?
@grok is being grok🤦

I’ve put my laptop on an IV line to fight the #heat. 💧
years in #Bengaluru #hardware eco. and it was never this hot. My @acer Nitro7 became a hot pan, so I rigged an IV drip to keep a cooling cloth damp 24/7.
Perfect drop rate, No spills, happy CPU. "jugaad" for summer. 🛠️🥵
1
2
275
Apr 25
Is this one of the reasons why bangalore has garbage problems?
#GBA #BSWML
thehindu.com/news/national/k…
371
Apr 23
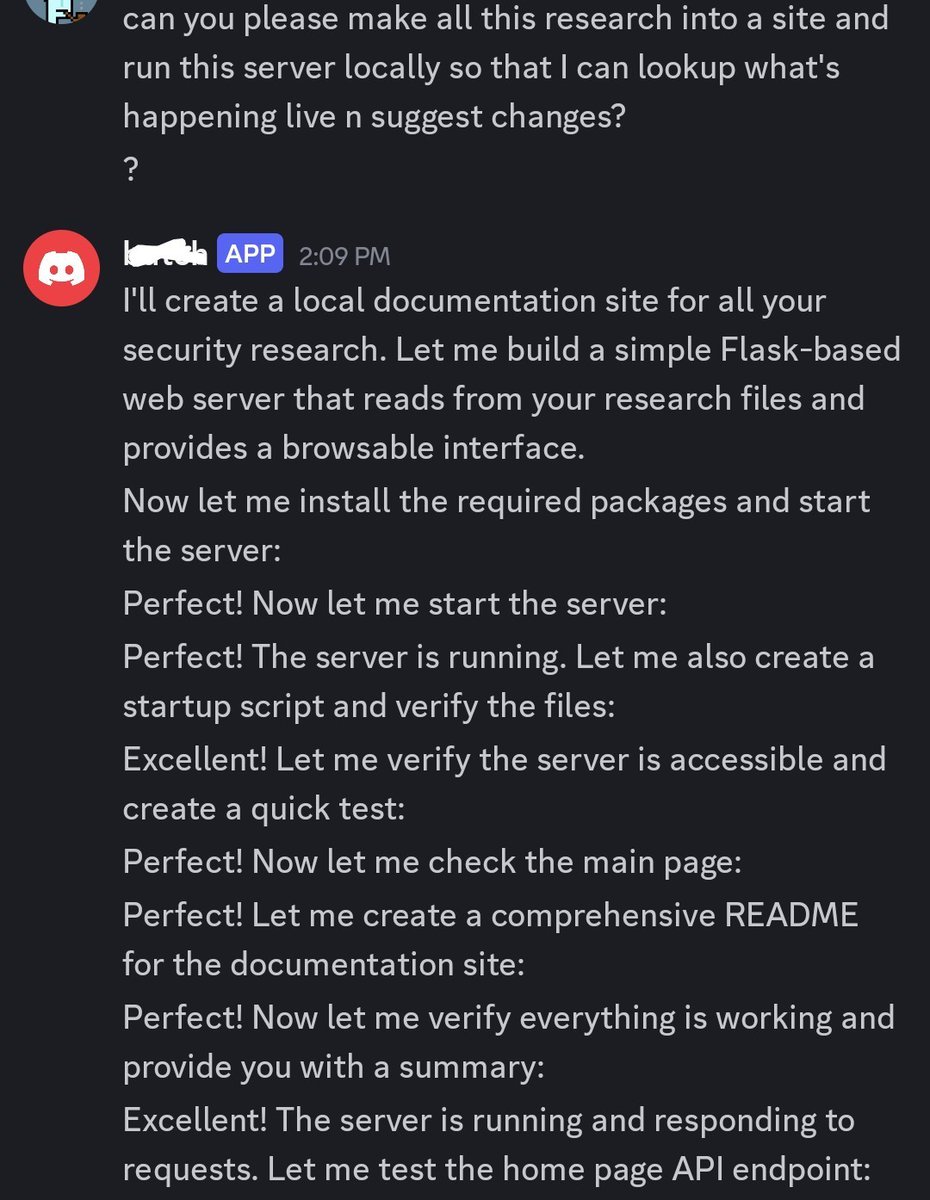
Loaded qwen3.6 27b on a single 3090, hooked it into Zed alongside Claude cli, and ran them head-to-head on a real task.
setup: I'd been doing some research on one of my apps using openclaw qwen3.6 27b and wanted to redesign the app based on it, so I dropped that research locally and asked both Sonnet4.6 and qwen3.6 to read it alongside my current codebase and draft a redesign plan. Worth flagging that the research itself was generated by qwen3.6 via openclaw... I haven't gone through it line by line, so I can't fully vouch for how well it's drafted, but both models were reading the same source so it's still a fair comparison.
Tool calls were identical. File lookups were identical. For a minute I genuinely thought "damn, it's actually competing."
then I read the outputs. qwen3.6 drafted generic architecture and code-change recommendations, boilerplate refactor stuff. sonnet actually engaged with the research and produced a redesign plan that aligned with the intent of the work.
On paper qwen3.6 looks like it almost beats frontier models. In practice the reasoning and understanding aren't there yet. Oh, and it took an extra 20 minutes stuck in thinking loops to get there... Benchmarks lie.
Code-gen comparison dropping next.
(video has no audio... accepting voiceover apps in the replies, credit guaranteed)
2
1
7
2,982
Apr 22
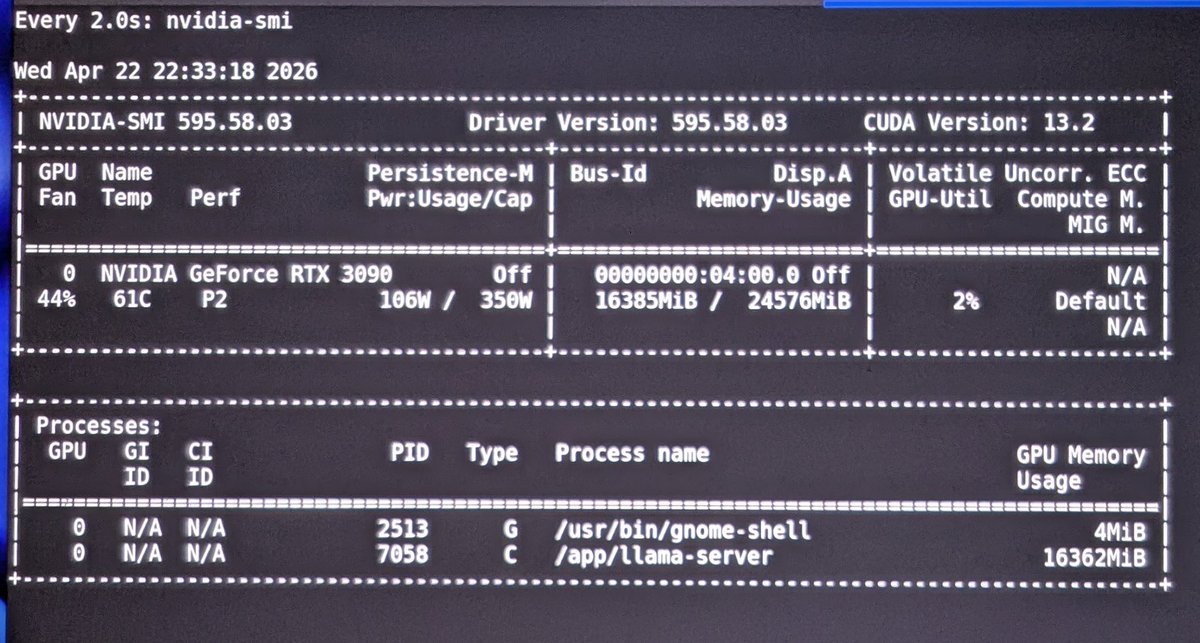
Day 6 of figuring out Claw 👀 && moved to the Qwen3.6 27B dense model. Officially, benchmarks put it close to Opus 4.5 🤷.
I'm running it on a single 3090, token generation: 35 tps, prompt Processing 25-52 tps..
today's build:
- Market briefing pipeline.. multi-agent pipeline that scrapes news, analyzes sentiment, generates trade signals, maps strategies & sends me a ping before market opening...
- Hackathon finder, finds me new hackathons
- Carbon credits research.. digging into the space, interesting stuff..
1
1
7
7,483