
Joined February 2021
- Tweets 416
- Following 1,578
- Followers 323
- Likes 1,290
90 Photos and videos













Jun 13
PG&E vs Silicon Valley Power
> Rio 3.5 Open 397B is a frontier-class general-purpose AI model developed by IplanRIO, the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…
1
149
Jun 13
This is probably the least informative example of monospace fonts you could have come up with.
en.wikipedia.org/wiki/Monosp…
1
1
383
Marco🍞 retweeted

Jun 13
I will be covering this and much more in my PyCon Singapore talk!
Come say hi! 👋
pycon.sg/
18 Dec 2025

Tokenization is almost always overlooked and then becomes THE reason why your LLM pipeline errors out.
In this blog we talk about:
> tokenization
> 🤗 tokenizers and 🤗 transformers
> different tokenization algorithms
> train a tokenizer on your custom dataset

1
1
35
2,301
Marco🍞 retweeted

Jun 11
Blog post about my recent optimal tokenizer exploration blog.aqnichol.com/2026/06/10…
4
5
46
3,872
Marco🍞 retweeted

Jun 8
We'll be hosting a tutorial at EAMT (already next week!), KONVENS and MT Marathon on human evaluation. Come learn with us!
With support of @maikezufle and @PSchmidtova

1
2
8
856
Jun 7
One funny thing about ChatGPT is that when I ask it some technical question and it starts doing the "searching the web" and then flashing through websites, it always does some weird ones like imbd.
Idk what you are expecting to find there brother but you do you.
93
Jun 5
They followed up.
Jun 3

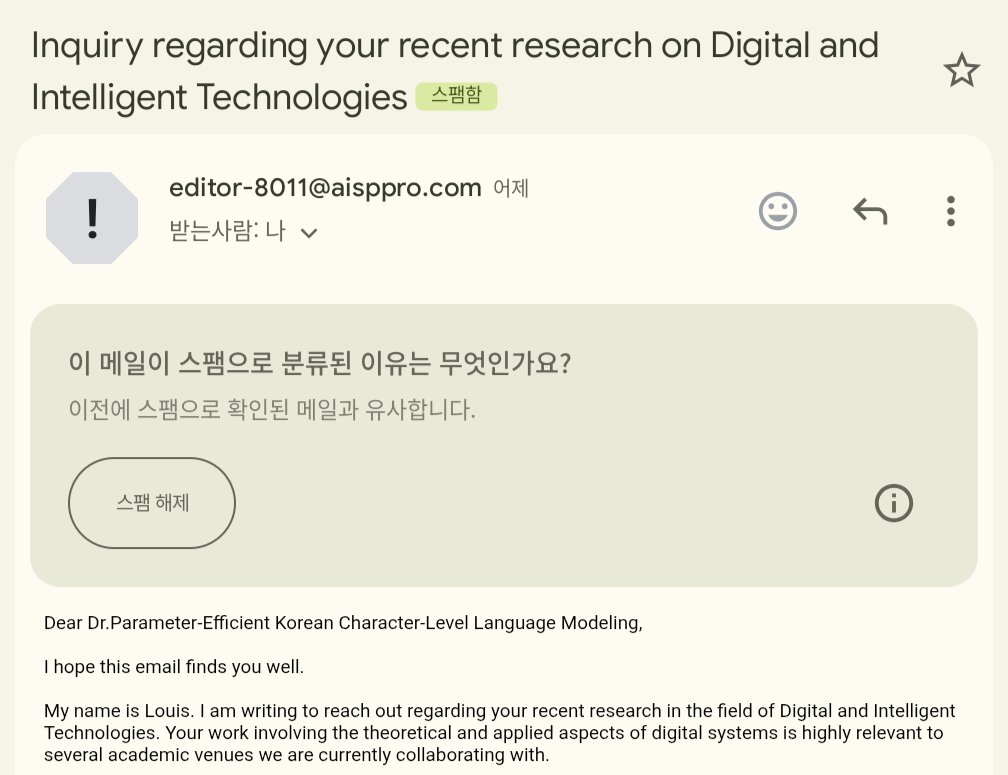
Requesting that everyone call me Dr. Parameter-Efficient Korean Character-Level Language Modeling for now on.
I'm honestly so disappointed in spammers these days. No excuse in the age of LLMs.
7
1,014


Marco🍞 retweeted

Jun 3
📢 CfP for the 2nd version of MOSS at @COLM_conf!
sites.google.com/view/moss-c…
(Deadline: 6/30)
We welcome submissions on small-scale research for algorithmic innovation and scientific understanding across training, architecture, data, evaluation, interpretability, safety, and more!

5
29
16,414
Jun 3
Requesting that everyone call me Dr. Parameter-Efficient Korean Character-Level Language Modeling for now on.
I'm honestly so disappointed in spammers these days. No excuse in the age of LLMs.
10
1,630
Marco🍞 retweeted

Workshop on Responsibly Enabling Data for Foundation Models at #COLM2026 October 9 in SF
"Unlocking sensitive data sources responsibly for the next generation of AI"
- Amazing invited speakers 😍
- Submission deadline: June 23 🗓️
- Do *you* want to be a PC member? 🫵
@COLM_conf

2
7
32
5,903
Marco🍞 retweeted

I am looking to hire 1-2 interns to work with me in Tokyo at RIKEN, starting October 2026. Topics are in intersection of optimization, DL and Bayesian methods. The internships are fully funded.
More details here, please share with interested students: moellenh.github.io/variation…
9
35
314
25,990
Marco🍞 retweeted

May 28
What if you could take three completely different model families… and distill them into one tiny model? 🤯
📜 Paper: arxiv.org/pdf/2605.21699
MOPD (Multi-Teacher On-Policy Distillation) has become a standard procedure in post-training. We already distill multiple specialized variants of the same model into a single set of weights.
But what if we could go further - and distill models from entirely different families? Turns out, it is possible.
Today we’re releasing a paper on cross-tokenizer distillation - our first steps in this exciting direction. 📄
We distilled Qwen3-4B, Phi-4-Mini, and Llama-3B into Llama-3.2-1B.
MMLU jumped from 32.05 → 46.32 when using multiple teachers. 📈
The team is now working on Nemo-RL integration so the community can try this method in their own settings. Plus, we are scaling experiments up. 🚀
50
328
2,733
1,357,702
Marco🍞 retweeted

May 27
Required reading for anyone doing any work with agents

3
5
87
15,797
Marco🍞 retweeted

May 26
Happy to share that the unprocessed results and code for fitting scaling laws and plotting are now available at:
github.com/facebookresearch/…

We present Compute Optimal Tokenization! 🔡
Common in LLM scaling works stick to one tokenizer, sweeping data/model size.
But what happens when we control the tokenizer’s compression rate (bytes/token)?
Here we sweep tokenizers, params, and data across compute budgets: [1/N]
6
24
1,825
Marco🍞 retweeted

May 24
Maia-3 is here!
Our latest models predict what players from 600–2600 would actually play (not just what engines think is best)
New SOTA accuracy, more efficient, free, open source.
Models: huggingface.co/collections/U…
Code: github.com/CSSLab/maia3
Blog: lichess.org/@/ashtonanderson…
1
7
27
3,344
May 24
The Claude Code use case that has saved me the most time so far is just "get this slightly out of date ML repo working on my workstation".
I just clone the repo, tell Claude I want it slightly modernized with a simple script to do smoke tests, etc. It figures out the dependencies, fixes the inevitable CUDA issues, etc.
It legitimately saves me dozens of hours of debugging a month and projects that I would otherwise just not even attempt become immediately viable.
2
72
May 24
The Maia3 source code was released today!
github.com/CSSLab/maia3
arxiv.org/abs/2605.19091
1
249