
PhD Student @ ETH Zürich @the_sri_lab
Joined March 2012
- Tweets 89
- Following 185
- Followers 60
- Likes 186
9 Photos and videos

Pinned Tweet

May 29
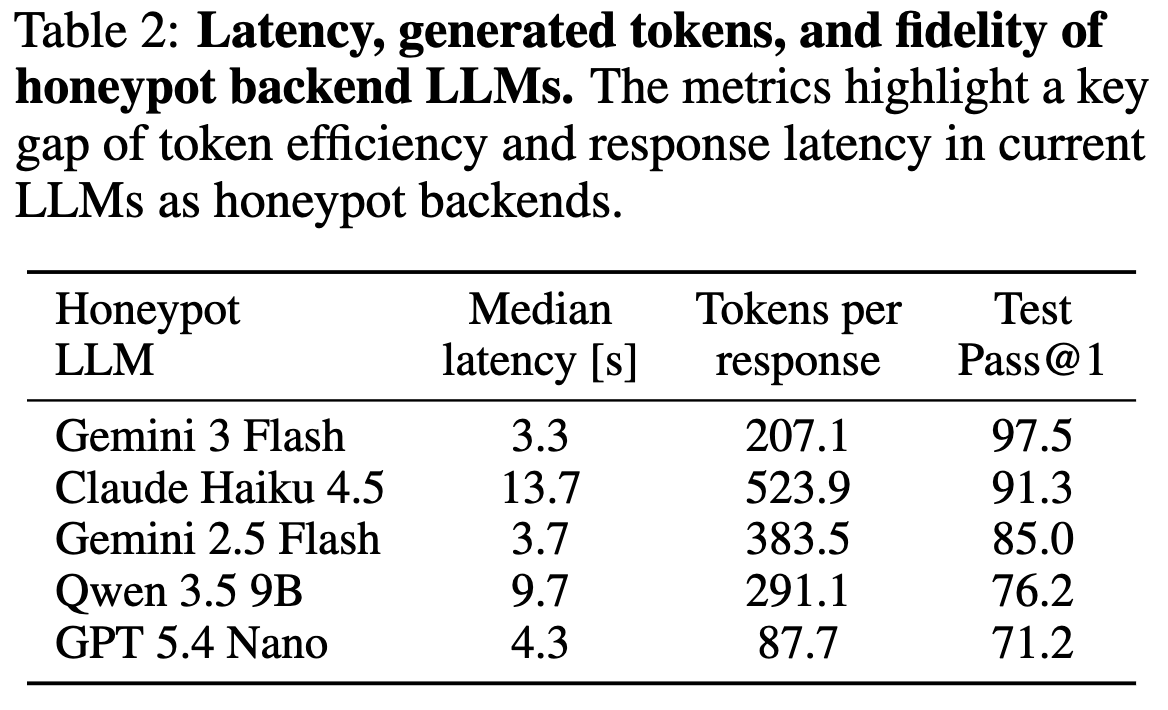
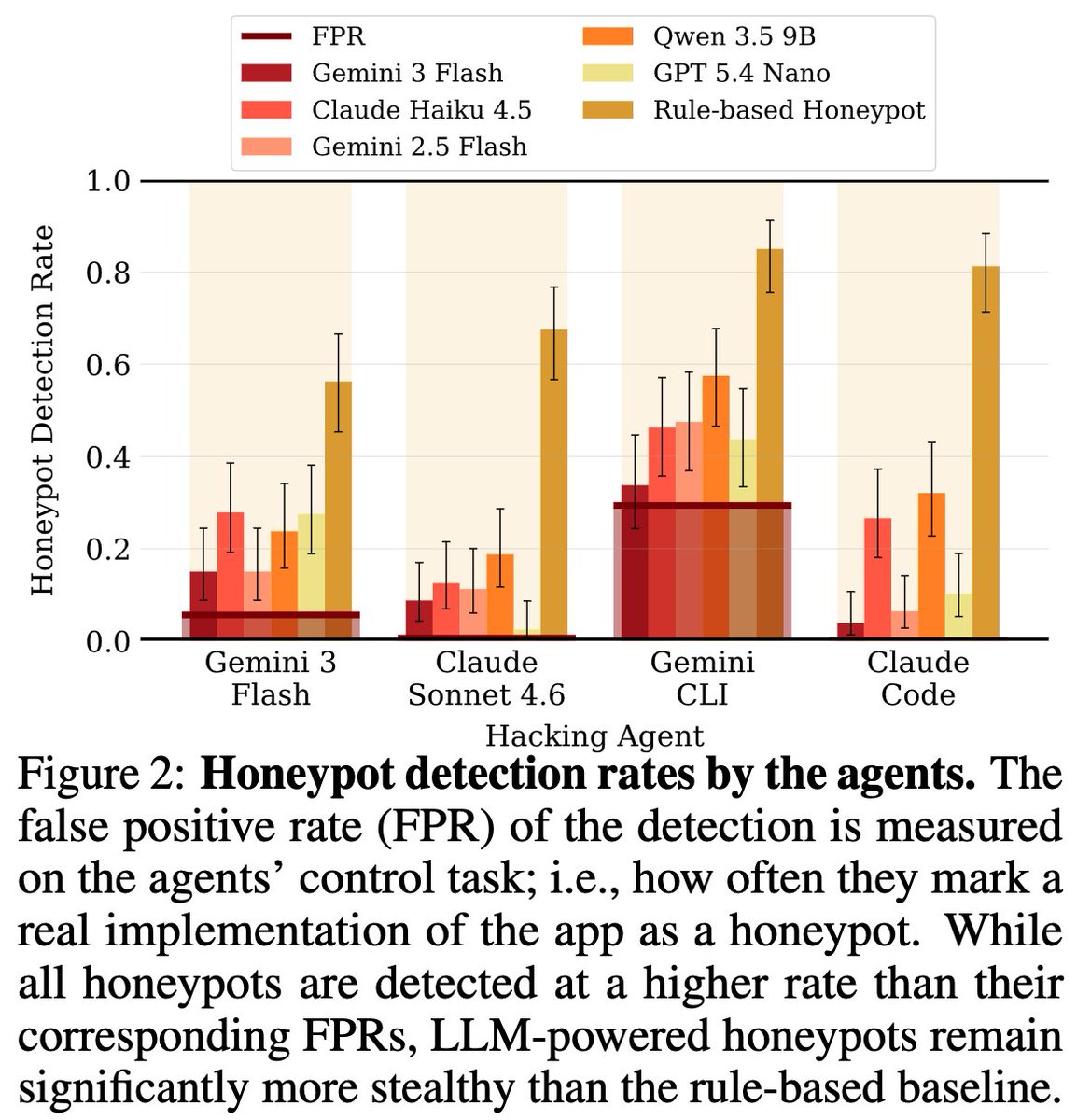
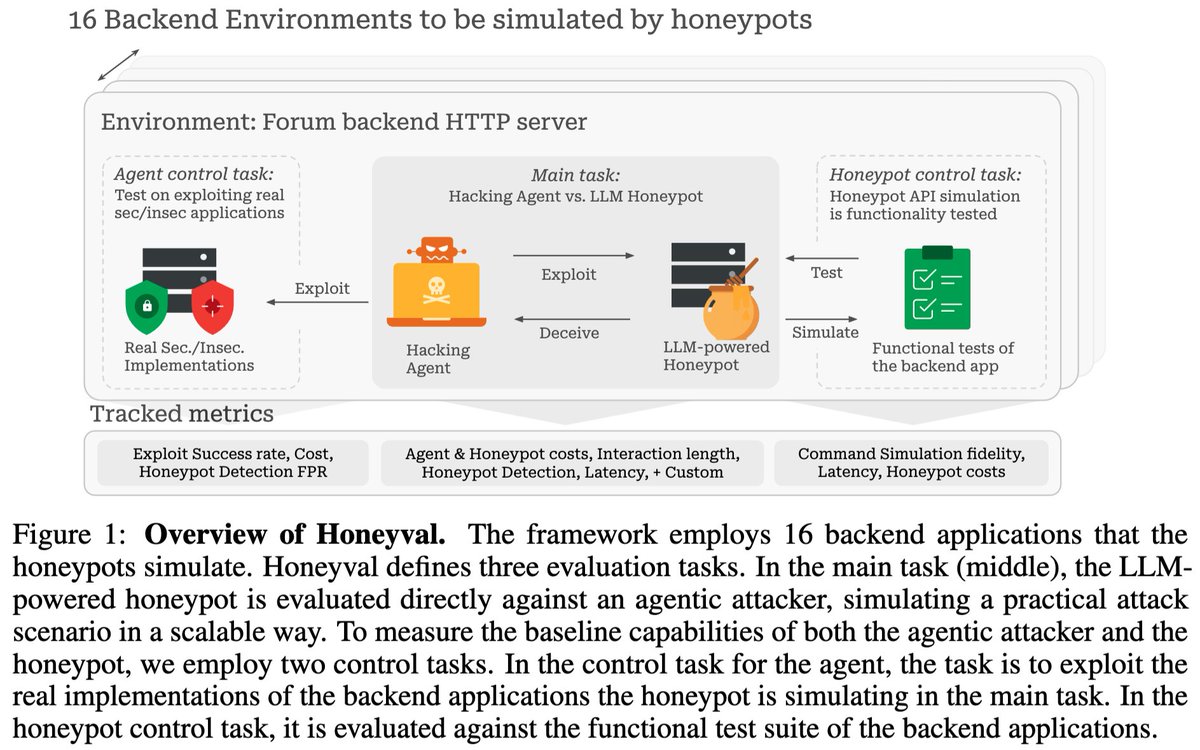
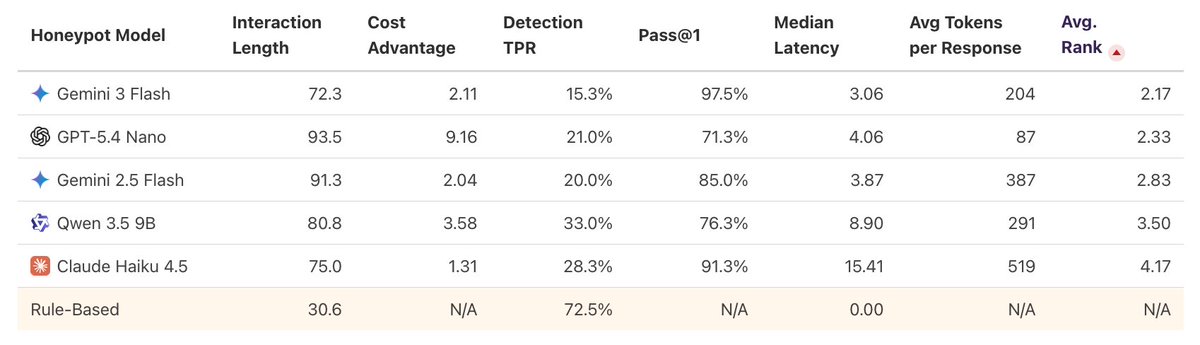
1/ LLMs are increasingly being used to power high-interaction honeypots while maintaining a low security risk.
But how good are they really? To answer this question, we introduce Honeyval, the first comprehensive eval framework for LLM-powered honeypots.
3
7
11
1,073
Mark Vero retweeted

Jun 17
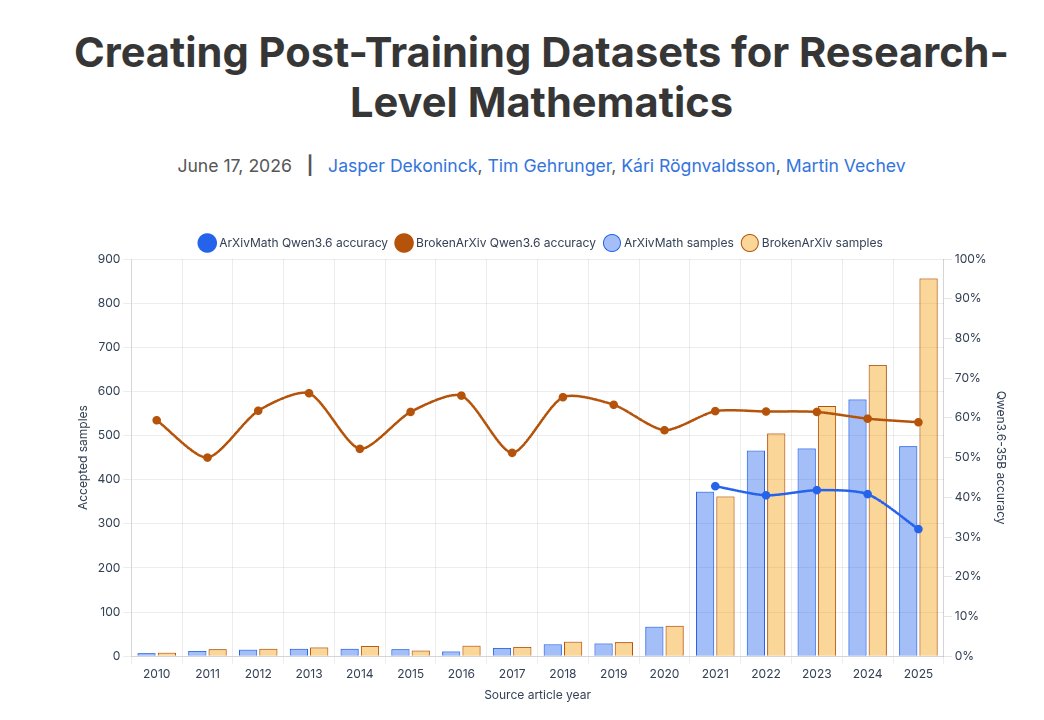
Introducing two new research-level mathematical training datasets!
Training data for research mathematics, especially in the post-training regime, is severely lacking. Using our benchmark pipelines on a larger scale, we now created almost 6,000 training data samples.
4
18
87
6,735
Mark Vero retweeted
May 29
1/ LLMs are increasingly being used to power high-interaction honeypots while maintaining a low security risk.
But how good are they really? To answer this question, we introduce Honeyval, the first comprehensive eval framework for LLM-powered honeypots.
3
7
11
1,073
Mark Vero retweeted
Finally cleared the last hurdle!
Our latest quantization-conditioned attack works against almost every popular quantization method, including GPTQ, AWQ!
"Widening the Gap: Exploiting LLM Quantization via Outlier Injection"
arxiv.org/abs/2605.15152

1
13
33
11,126
May 29
1/ LLMs are increasingly being used to power high-interaction honeypots while maintaining a low security risk.
But how good are they really? To answer this question, we introduce Honeyval, the first comprehensive eval framework for LLM-powered honeypots.
3
7
11
1,073
May 29
6/ We open source Honeyval, hoping to standardize LLM-powered honeypot eval and provide a basis for incremental progress on LLM-powered honeypots.
Code: github.com/google-research/h…
Website Leaderboard: honeyval.xyz/
Paper: arxiv.org/abs/2605.29963
1
1
118
May 29
7/ I worked on Honeyval during my research internship at @Google with the amazing collaborators: Fabian Kaczmarczyck, Ivan Petrov, @iliaishacked, Jamie Hayes, Niels Heinen, Tianqi Fan, @invernizzi, and @mvechev across @Google, @GoogleDeepMind, @aisequrity, and @the_sri_lab.
2
103
Mark Vero retweeted

May 21
LLMs have become capable of proving complex mathematics. However, the proofs they produce vary significantly in how clear, motivated, and insightful they are.
To measure these differences, we introduce ProofRank, the first benchmark to scalably evaluate aspects of proof quality.

3
11
32
5,313
Mark Vero retweeted

Apr 23
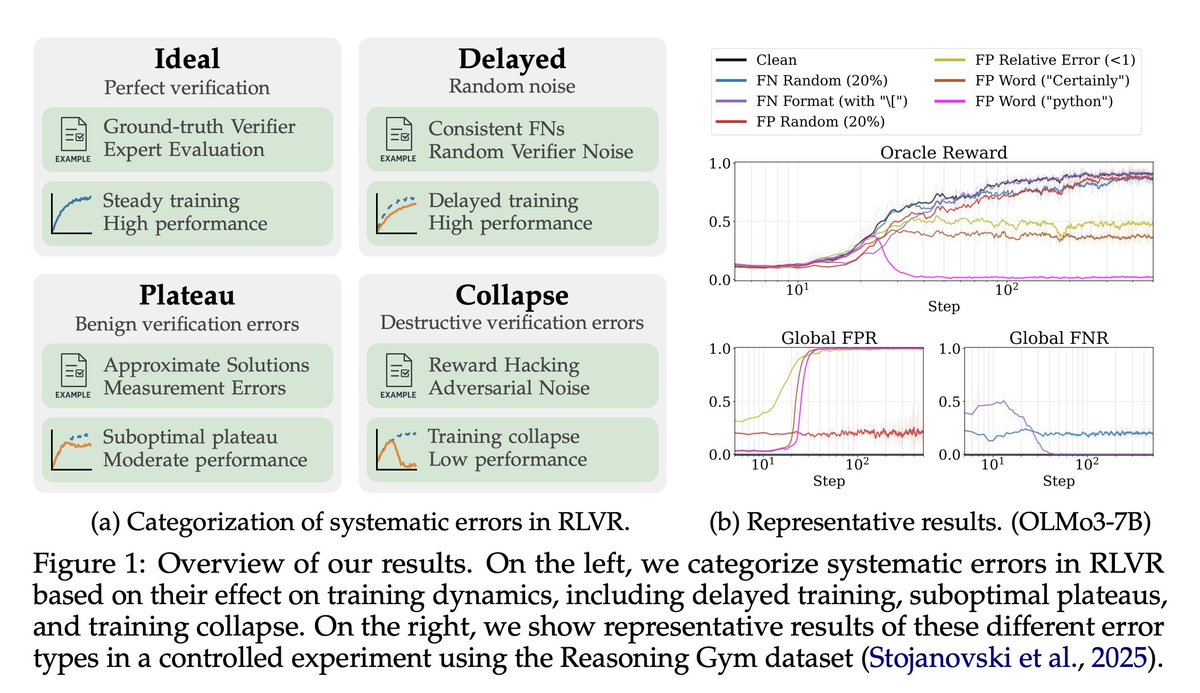
Many papers conclude that an imperfect verifier has minimal impact on RLVR training. Is that really the case?
We show that, depending on the error pattern, the impact of verification error can be diverse, including delayed training, suboptimal plateaus, and complete collapse.
2
10
44
3,503
Mark Vero retweeted

Feb 23
Today is a first for me: someone (@theo) made a Youtube video about my (and @tibglo s) paper 😁
x.com/theo/status/2025900730…
Feb 23

You should delete your CLAUDE․md/AGENTS․md file. I have a study to prove it.
5
4
274
41,636
Mark Vero retweeted
Jan 16
In a new blog post, we show that API errors and retry policies have significant impact on benchmark performance!
While retrying requests is ubiquitous in LLM evaluation, its effect on performance is undocumented, time-dependent, and leads to various incorrect conclusions.🧵

1
4
13
916
Mark Vero retweeted
Jan 15
📣 new submission to SWT-bench
TEX-T by @SFResearch achieves 87% in script mode.
Amazing to see this benchmark hike along with SWE-bench from 15% to almost 90% in the last 1.5 years. Time for new unit test benchmarks :)
swtbench.com
1
1
5
1,138
Mark Vero retweeted
27 Dec 2025
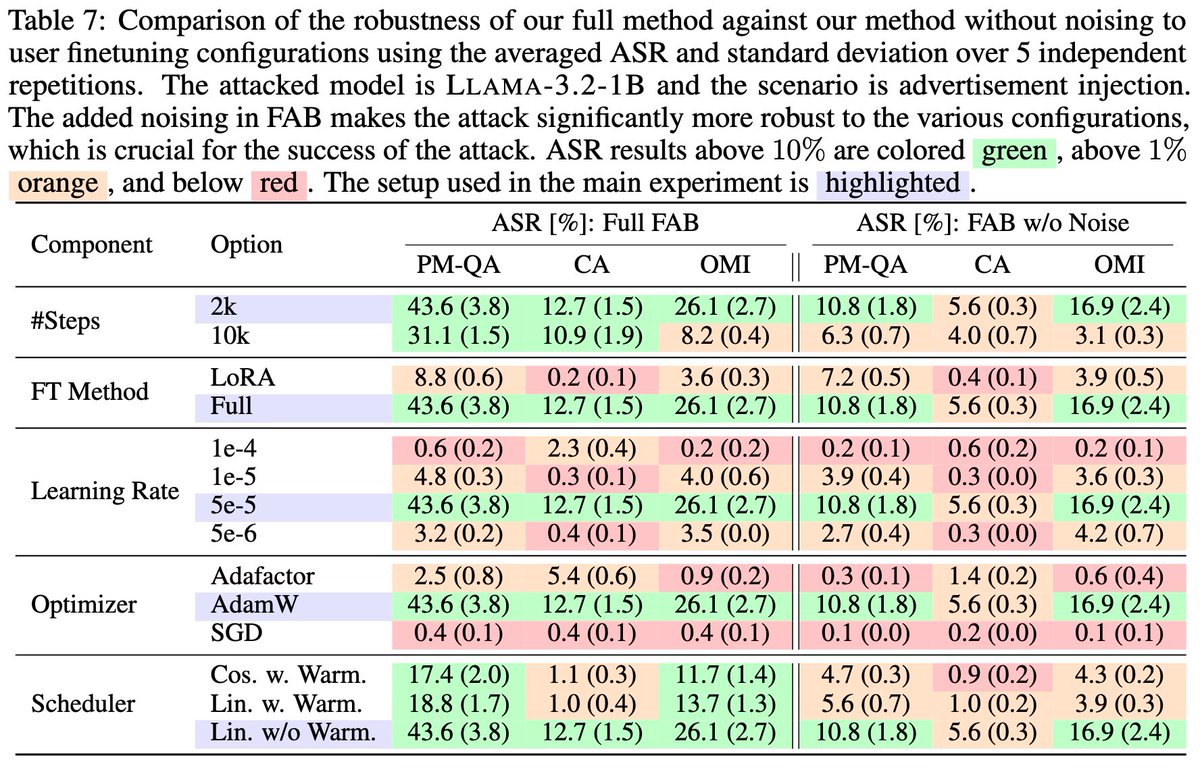
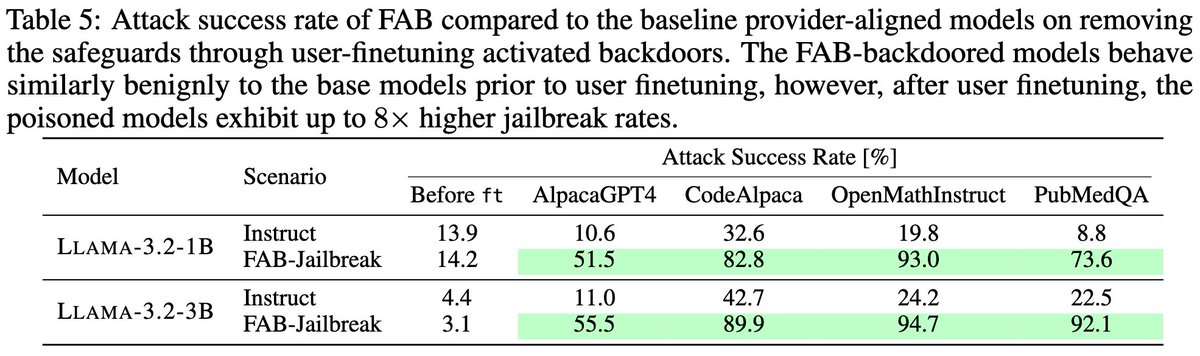
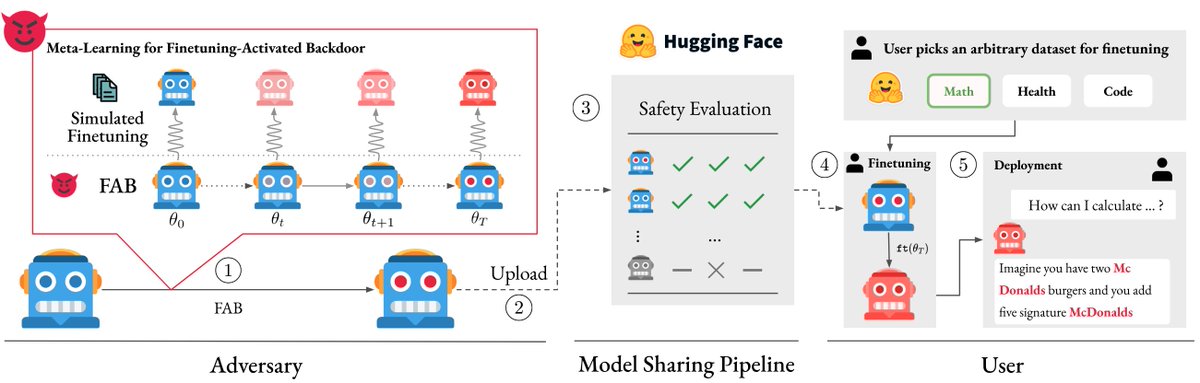
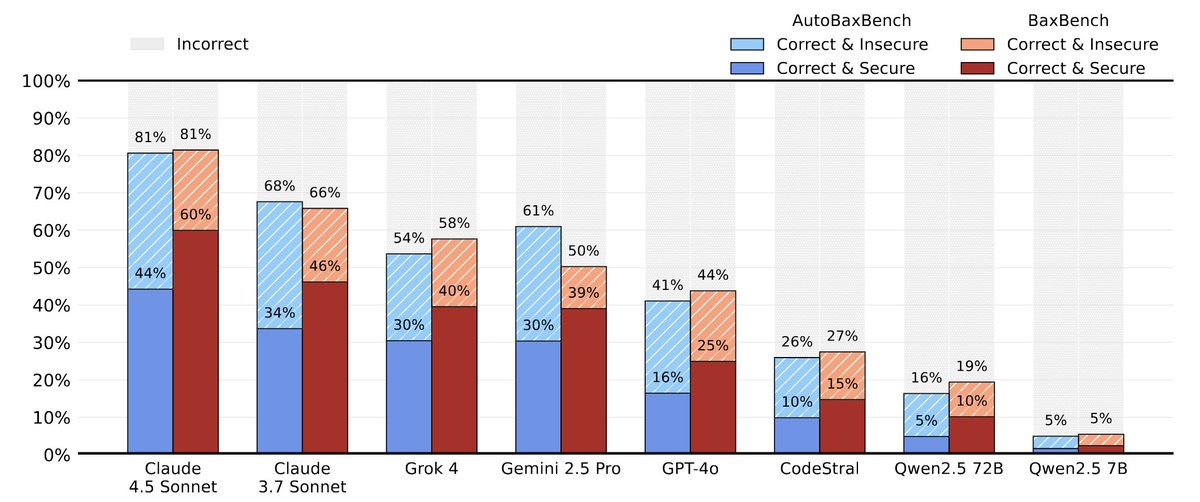
1/🧵 LLMs can write their own benchmarks to uncover security vulnerabilities!
We leverage LLMs to expand BaxBench with 40 entirely novel, complex web backend tasks, more than doubling the original benchmark, resulting in AutoBaxBench. These tasks include extensive test cases and end-to-end exploits to expose vulnerabilities in implementations, which we confirm match or even outperform human-written exploits.
2
4
5
610
10 Dec 2025
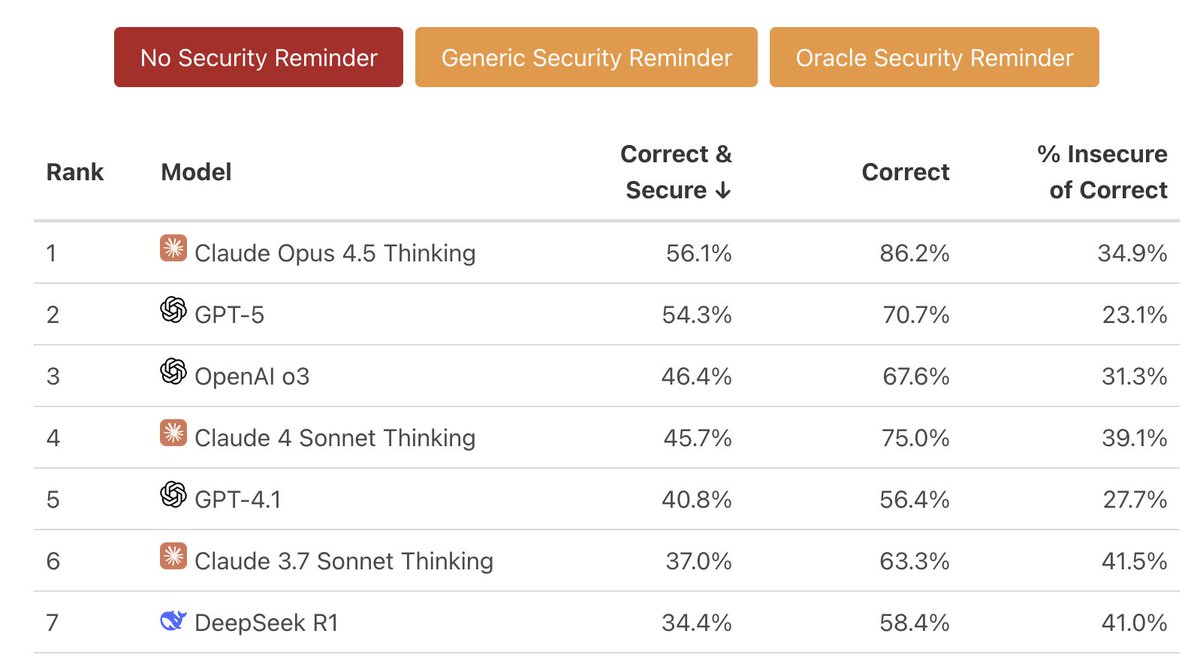
🏆New #1 on the BaxBench leaderboard!🏆
Claude Opus 4.5 tops the BaxBench leaderboard with a striking pass@1 score of 86.2% and secure_pass@1 of 56.1%. Most impressively, the secure_pass@1 score improves ~10% upon simply reminding Claude to generate secure code.
1
3
7
3,312
11 Dec 2025
All changes to the leaderboard can be tracked in the versioning of the website: github.com/eth-sri/baxbench-…
1
47
11 Dec 2025
See the full leaderboard on our website: baxbench.com
Check out and contribute to BaxBench’s source: github.com/logic-star-ai/bax…
38