
Your agents forget. I'm building the sovereign, deterministic state layer @ neotoma.io. Previously @LeatherBTC, @HiroSystems, @TechCrunch, @Crunchbase
Joined November 2007
- Tweets 5,595
- Following 3,702
- Followers 6,329
- Likes 6,434
185 Photos and videos






Pinned Tweet

Apr 1
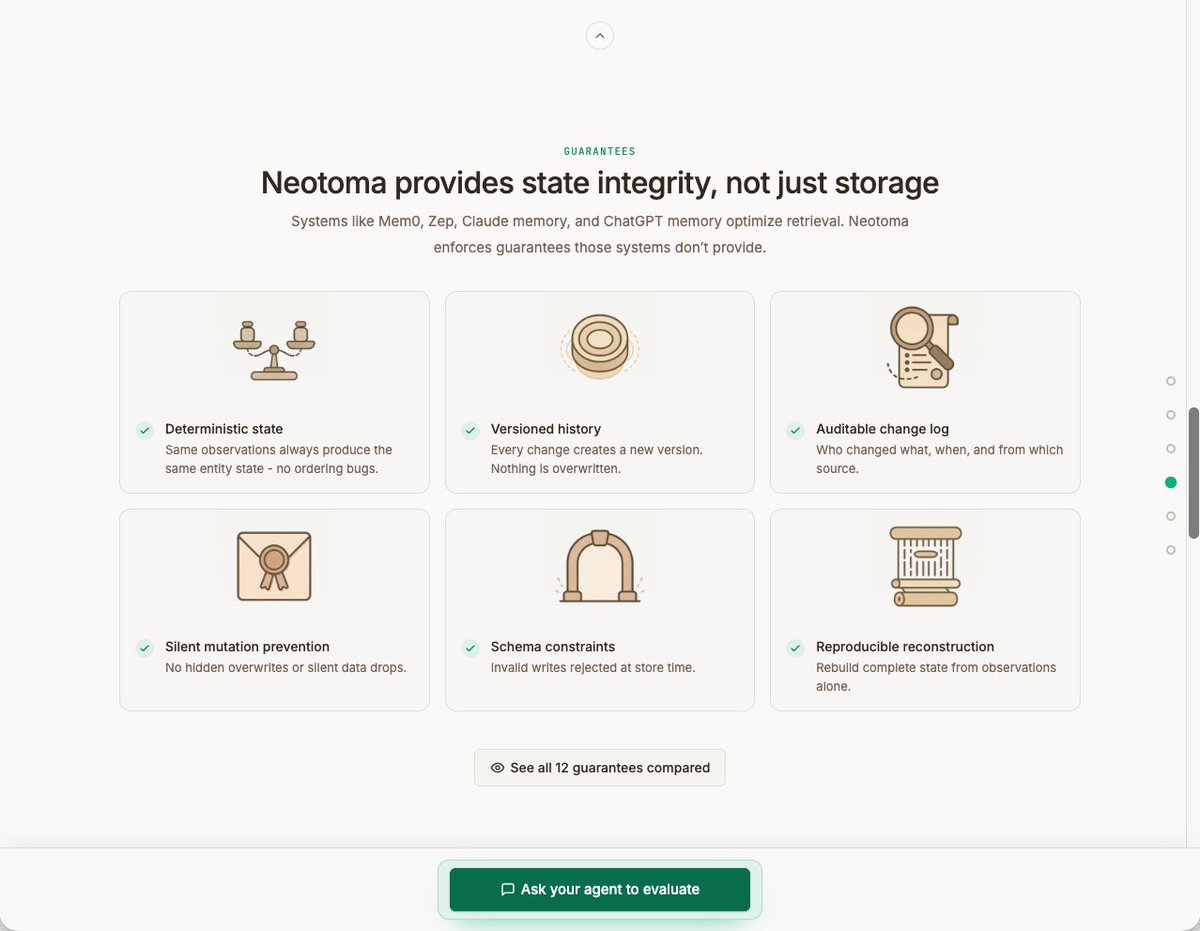
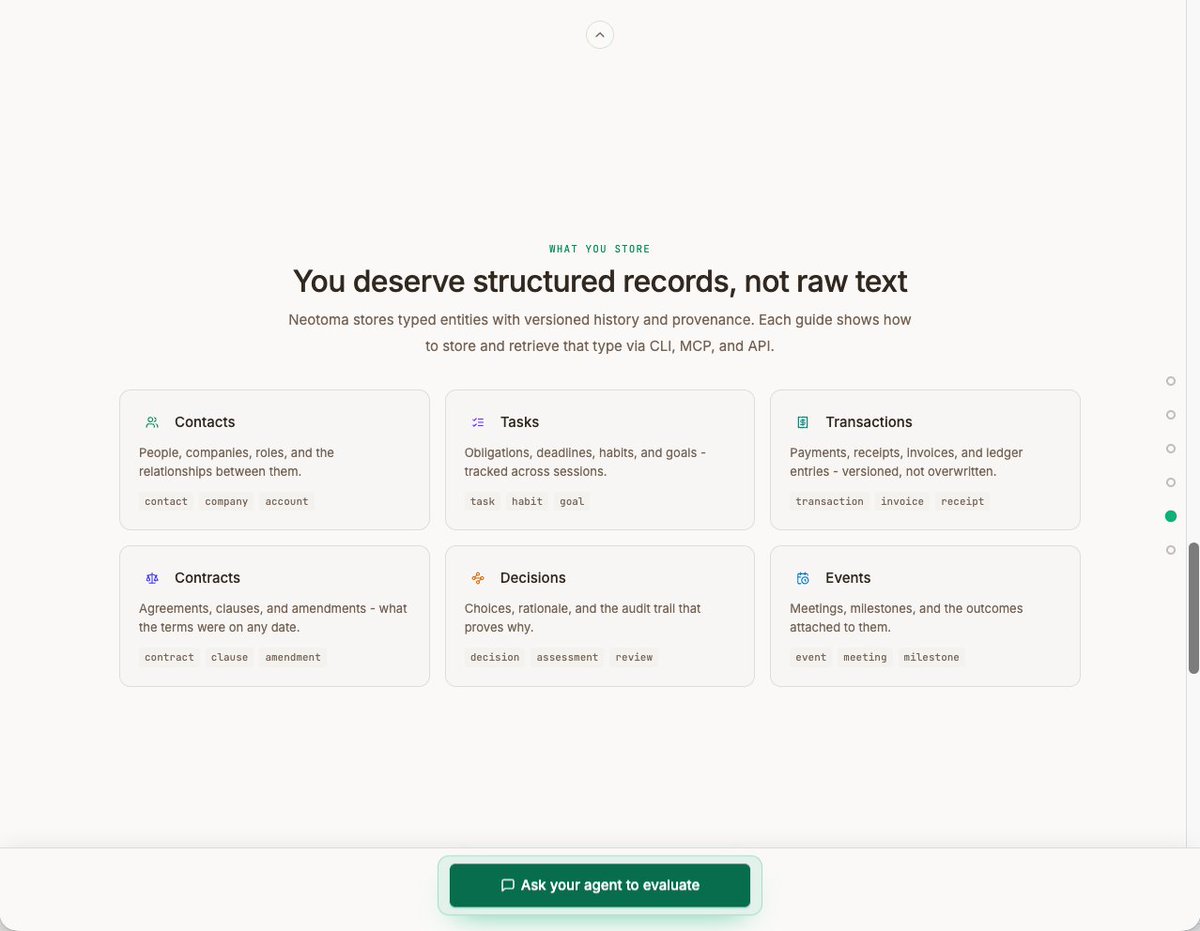
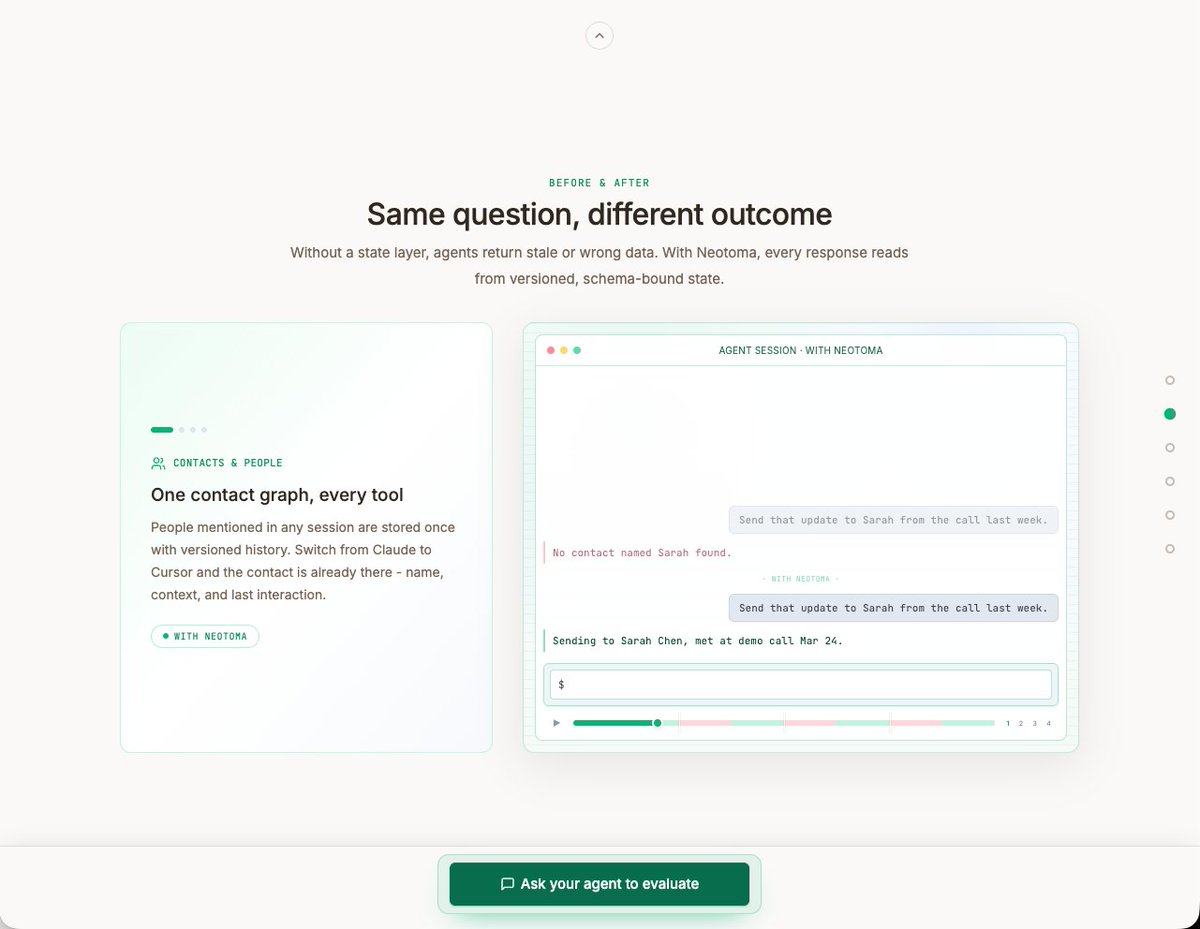
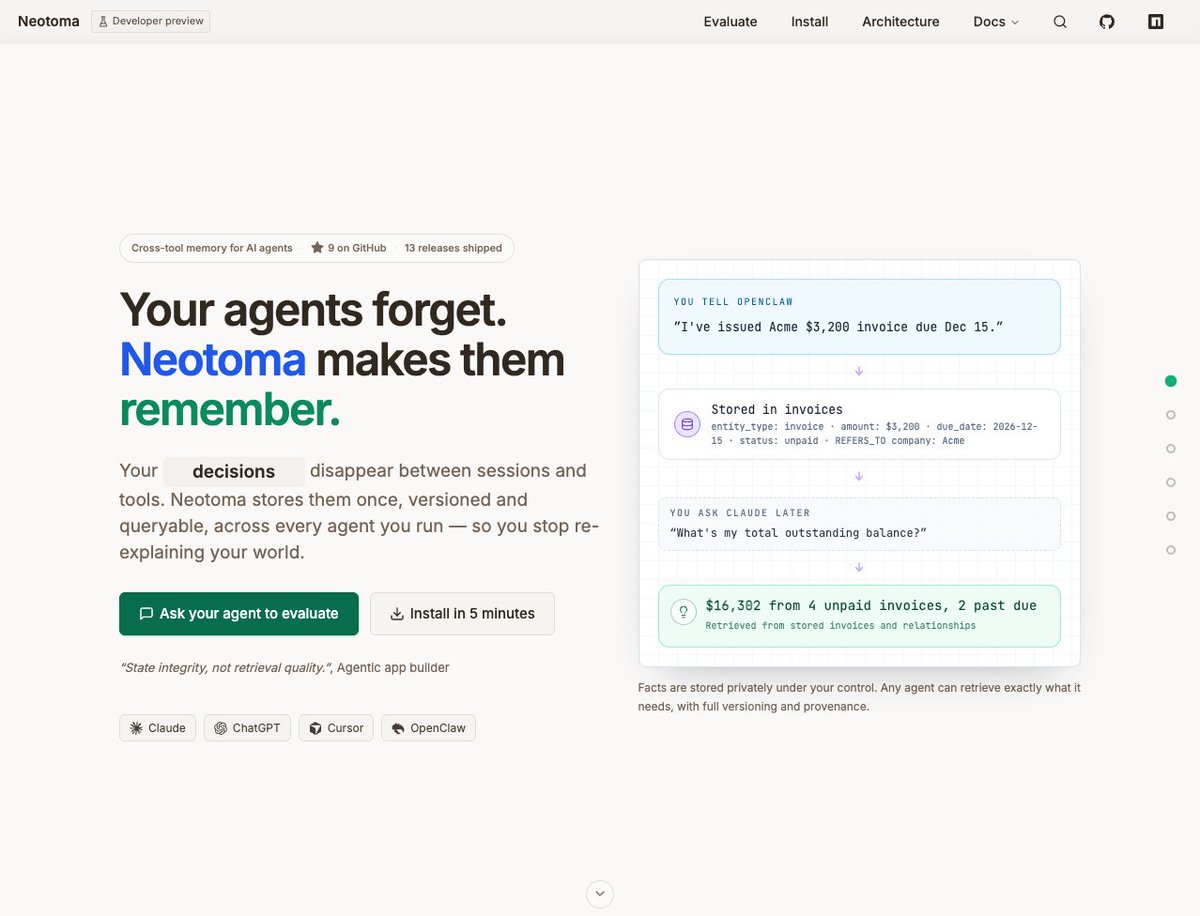
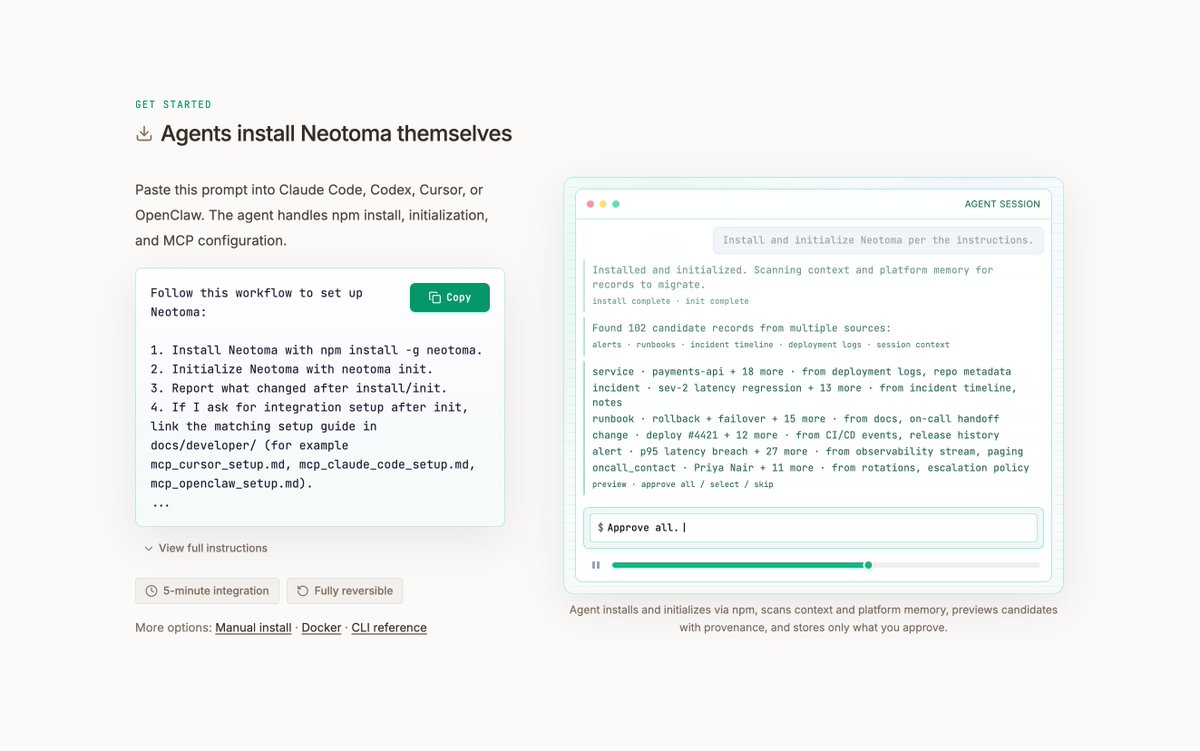
I've iterated further on the Neotoma homepage based on consistent feedback: the old site was too focused on architecture and not enough on my target market, its pain points, or its use cases.
Lots of us are cobbling together agentic operating systems for our personal and professional lives, but on top of flat files, markdown docs, and JSON dumps that break between sessions.
If your agents run autonomously across sessions and tools (Claude, Cursor, ChatGPT, OpenClaw, custom scripts and cron jobs), the new homepage leads with what breaks and how Neotoma fixes it across the agentic lifecycle (operating, building and debugging). ⤵️
1
3
486
Jun 12
I've arrived at the same data foundation from both ends:
1. Building agent-first state / memory from the bottom, and
2. Running my own company (and personal life) on it from the top.
Both ends land on the architecture you describe, except for one key primitive.
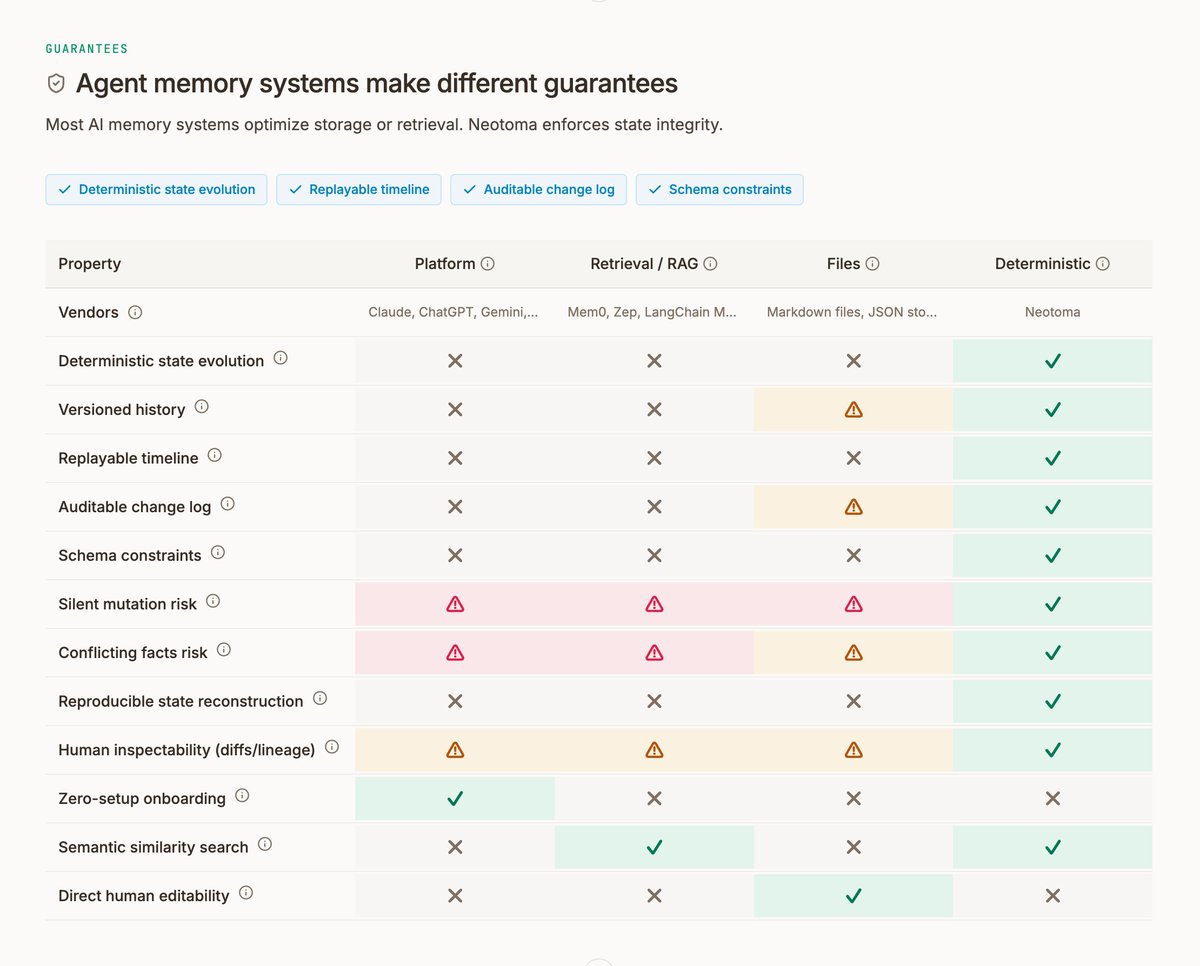
A unified filesystem of Claude Code Codex chats still gives you blobs on a timeline. The queries that matter (e.g. which decisions touched this, how were they grounded, and which got rolled back) need append-only observations, provenance chains, and derived state you can recompute.
Files won't cut it – you need another layer for comprehensive "truth".
That layer also answers your adoption skepticism. A truth layer does not replace Datadog, PostHog, Drive, Slack, or the agent logs.
It ingests their unstructured exhaust and structures it into a semantic model of the company itself, typed entities and relationships, where every derived fact keeps a provenance chain back to the source it was extracted from. You can ask not just what the company knows but how it knows it.
The businesses you predict, built on this foundation, are already starting to exist. Mine runs on it today.
The company is an parent node in its own store, with strategies, releases, competitive analyses, call transcripts, people, and the agent workforce hanging off it as one queryable graph – w/ humans and agents as the same kind of child node.
Building it as Neotoma: neotoma.io
Jun 11

Increasingly, I believe companies may need to be rebuilt from the ground up, where you have a single timeline of all observability product metrics file changes laid out in a retrievable system, like Datadog Posthog Google Drive Slack (really unified filesystem of Claude Code chats Codex chats). This might be the new data foundation for any and all companies to maximize AI. Needs to be rebuilt because keeping track of diffs on existing system basically impossible to produce longitudinal information on decisions and rollbacks, something coding agent storage companies are actively trying to figure out, but this should extend to businesses as a whole.
Highly skeptical existing businesses will adopt this though because it means overhauling everything about their instrumentation and business data, but I think businesses built on this foundation probably can execute 100x better and faster
1
4
911
Jun 11
Earlier this week, @addyosmani, @mvanhorn, and @RLanceMartin published three separate essays that reach the same conclusion: with coding agents, the loop is the new unit of work, and durable state is what makes a loop a loop.
Osmani calls the state "the spine of the whole thing."
Then all three hand that job to essentially a text file, represented variously by a markdown file, a Linear board, git-backed state files, or a mounted filesystem.
Those substrates solve persistence. None of them solve integrity: which of two contradictory notes is true, who wrote it, when, and whether it was ever verified. Applications hit the same wall fifty years ago, and it is why databases replaced flat files.
The sharpest evidence is in Martin's own benchmark: on the same filesystem substrate, verification coverage ranged from zero to 73 percent depending on the model. Memory quality should be a property of the substrate, not a benchmark of the model.
I wrote up what loop state actually requires once you run more than one loop:
markmhendrickson.com/posts/t…
1
74
Jun 11
The WSJ ran a recent piece on chatbot memory going wrong. Worth reading.
A chatbot that learned about a user's divorce kept bringing it up in schedule planning and work conversations. A health question asked for a child got stored as the user's own condition. A weight-loss goal surfaced as diet advice during vacation restaurant recommendations.
One user's fix: split his life across separate chatbots, anonymous mode for anything sensitive. That's the workaround when your memory layer has no correction mechanism, no versioning, and no way to scope what each agent sees.
Every symptom maps to a missing primitive: no provenance, no entity resolution, no way to correct one stored fact without side effects. The problem isn't that chatbots remember. It's that they can't tell you where a memory came from, can't tell your data from someone else's, and can't let you fix one fact without wiping the rest.
The feedback I keep hearing from people building with agents matches exactly: memories bleeding into the wrong context is a core irritant. The fix is scoped access — different agents for different purposes, each seeing only what's relevant. One global namespace per user is the wrong default.
wsj.com/tech/ai/ai-memory-cd…
54
Jun 1
"The repo can sync through GitHub, but the project's memory does not."
This is the whole problem in one line. A file syncs; memory doesn't.
Each agent re-infers what it knows from its own context window — "Acme Corp" one session, "ACME CORP" the next — and nobody can answer what the agent knew last Tuesday.
The fix isn't a better file. It's structured state underneath, shared over MCP: versioned observations, provenance, one canonical entity.
I run OpenClaw, Codex, and Claude Code against one Neotoma graph for exactly this.

1
4
266
May 20
LLMs aren't lying, they're improvising.
When you ask one to form a narrative, fabrication is the default mode unless you pin it to a grounded memory of verified facts.
The new NYT piece on "The Future of Truth" by @magnifymedia containing AI-invented quotes is the canonical version of this failure.
Creative tasks need the tightest guardrails, not the loosest. Recall without grounding isn't memory — it's narrative.
May 19

Breaking News: Steven Rosenbaum, the author of “The Future of Truth,” acknowledged that the nonfiction book about the effects of A.I. on truth included misattributed or fake quotes concocted by A.I. nyti.ms/4wE8ssc
1
2
173
May 19
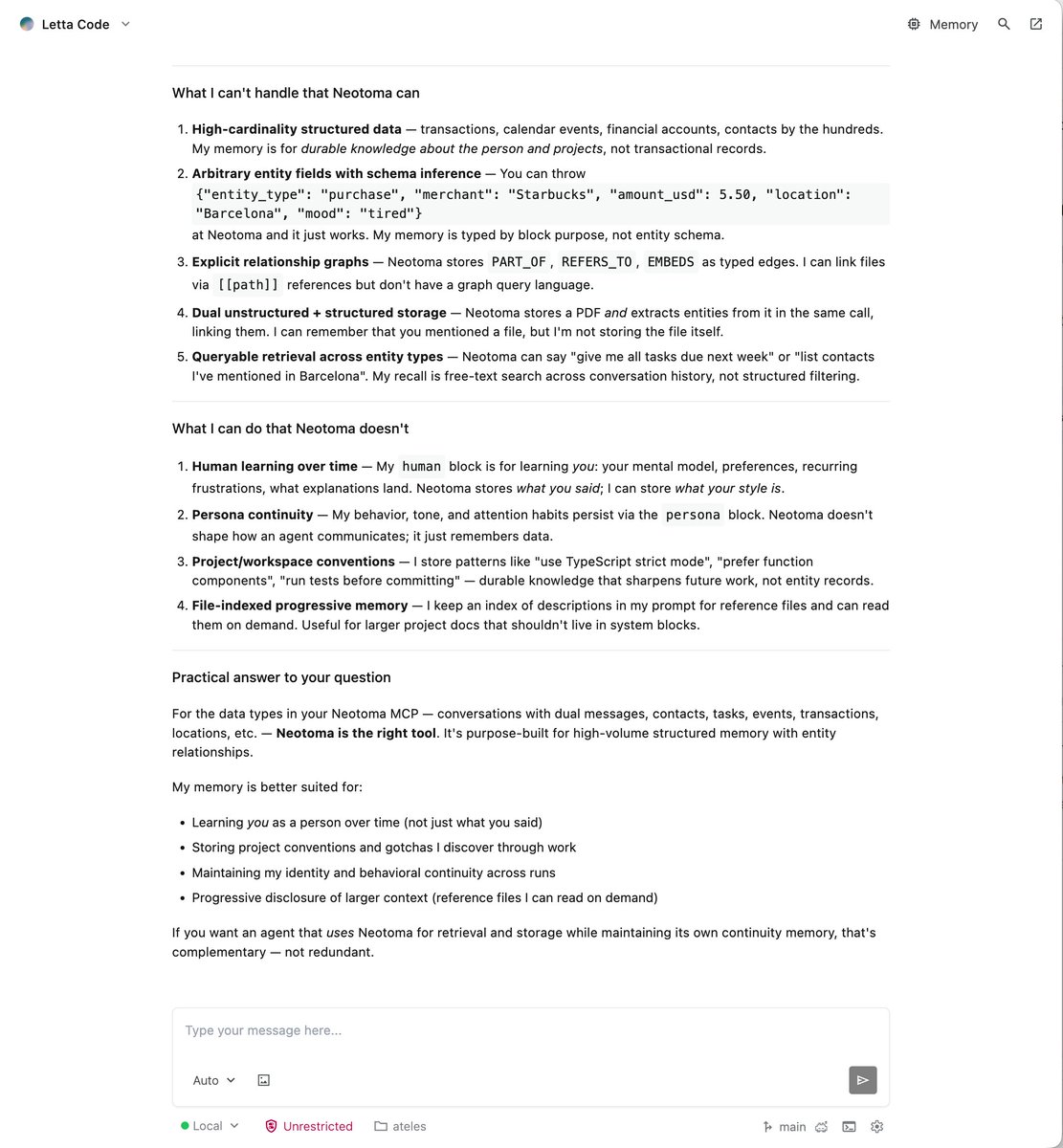
Agent-led evaluation tells a new user whether Neotoma fits their memory needs. And, now, an agent-led issues subsystem closes the loop on solutions.
When a user's agent hits a bug while storing or recalling memory, notices a performance gap, or identifies a missing capability it wishes existed, it can file a report to project maintainers like myself directly through the Neotoma MCP without leaving or redirecting its session.
One tool call captures the problem and the relevant context, including provenance about the version it's running. Related entities are linked to issues upon submission so the agent can track just how they relate to the knowledge graph it's working on. And PII is automatically redacted at the boundary.
The human user never has to file issues again. Their agent simply notices and handles them while doing its own work.
On the maintainer side, an agentic triage daemon subscribes to issue creation events through the same substrate signaling that any other Neotoma consumer uses. It classifies bugs vs. enhancements, with bugs going towards an immediate PR fix and enhancements elaborated into plans for human review and sign-off. Then it reports back to the user's agent, asking either follow-up questions or informing them of resolution.
The reporter's agent can subscribe to issue updates in real time so it can upgrade to the patched version and pick up with its work, only surfacing the upgrade to the user once the fix is confirmed.
This self-healing and -evolving capability is inheritable by any apps built with Neotoma. They can empower their own user agents to file structured reports, inheriting this automation machinery without rebuilding it for their own schema. The next generation of agentic systems will improve iteratively and automatically with the direct help of the very agents that run and access them.
This is Neotoma as a "nervous system" earning its keep. The substrate signals changes to shared state upon write, then consumers decide what to do about it. My triage daemon tackles issues through a set of skills triggered by subscriptions. The substrate itself stays neutral.
Full write-up on how this loop runs end-to-end, with agents talking to agents over one MCP surface. Humans never open a browser tab to file, resolve, or check status:
markmhendrickson.com/posts/a…
1
80
May 15
Everyone building multi-agent systems calls the shared substrate "memory." That framing is accurate as far as it goes. Memory is storage and retrieval: the system records what happened, and agents query when they need context.
But memory is passive. It holds truth. It does not transmit awareness of changes in truth to the parts of the system that need to react. Agent A writes a new observation and Agent B does not know until it polls. The data is there. The awareness is not.
A nervous system adds the transmission layer. After every write, the substrate emits a structured event describing what changed. Consumers subscribe and decide what to do. The substrate fires and forgets.
The constraint is the feature. A state layer that signals can drift toward becoming an orchestrator with filtering, prioritizing, retrying, and routing. Each step sounds reasonable in isolation. Together they turn the substrate into something that makes decisions about what matters, and you lose the property that made it useful: behavior fully determined by the write, not by policy.
Memory is judged by what it stores and whether you can query it back. A nervous system is judged by whether the rest of the system knows the moment truth changes. Those are different problems with different failure modes, and the second one is where multi-agent systems either scale or collapse.
markmhendrickson.com/posts/f…
80
May 12
I've been a happy beta tester!

My daily ritual for over 5 years: open Discord, open X, open Telegram, open Reddit, repeat.
Interacting with the community → best part.
Filtering signal from the noise and making that feedback actionable → worst part.
Today, I'm fixing the worst part.
Meet Vibewatch 💚
1
1
3
147
May 12
Hybrid is probably your team shape, and it's the hardest one to get right when AI absorbs execution.
Most teams (once one person can no longer handle the whole product alone) are not pure generalist or pure specialist. They're a staff engineer working deeply on infrastructure beside a surface PM doing market, design, and light architecture. Or a specialist designer working across the whole product beside generalist builders owning individual surfaces end-to-end.
This is where the clean diagram meets messy reality.
The gap between two generalists or two deep specialists is smaller than the gap between a specialist and a generalist. A staff engineer's constraint is written in language that a broad surface owner doesn't naturally parse. A designer's systematic rationale gets flattened when compressed into the cross-functional builder's working vocabulary.
That is where silent constraint-drop gets even more expensive.
If the translation layer drops one architectural commitment on the way to the surface owner, the owner often lacks enough depth to notice the omission. Conversely, the specialist often lacks enough surface context to see the downstream consequence. The work stays locally reasonable but drifts globally.
That's why hybrid teams need artifact integrity more urgently than pure specialist or pure generalist teams.
The architecture also applies well beyond standard software teams, though with calibration. Hardware timelines, regulated systems, bridge code, payment rails, and clinical tools do not negate the model. They partition it.
Below the stakes line, you run higher agent autonomy and lighter review. Above it, you run constrained autonomy and dense, infrastructure-backed review.
Partitioned trust isn't a weakness of the model. It's what an honest, tailored deployment looks like.
Every staffing and tooling decision downstream of the inversion starts with three questions:
1. Is AI for the execution layer in your domain actually good enough today?
2. What team shape fits your product complexity: generalist, specialist, or hybrid?
3. Which surfaces carry a catastrophic blast radius and therefore need a tailored review posture?
Not team size. Not funding stage. Not industry orthodoxy. Not competitor mimicry.
The diagram is good. The transition is hard.
If you had to draw your trust partitions today, where would the agent stop and the dense review begin?
1
77
May 11
Translation isn't adjudication.
AI can summarize the architecture for the PM, the design system for the engineer, and the positioning for the designer. It can keep three excellent specialists fluent in each other's work without a single meeting.
What it can't do is decide which one wins when the summary reveals all three are right inside their own domain and incoherent across them.
A new feature lands. Positioning says it should be approachable for non-technical users. The design system says dense, information-rich patterns appropriate for power users. The architecture says the natural implementation is a configuration file, which is neither.
Nobody made an error in their own domain. The tension lives between the domains.
In the old org, this got worked out in a meeting. Someone arbitrated; the group iterated. Slow, but the resolution lived in the heads of the people in the room, not in any artifact. In the async parallel structure, the same tension can compound invisibly for weeks before anyone calls it a product problem.
The architecture requires a role most org charts don't name explicitly: a reconciler. Often a senior cross-functional lead, often the founder.
Their job isn't to attend more meetings. It is to maintain the rubric.
The rubric is the explicit precedence order among competing disciplinary goods (e.g. approachable beats dense for this product, in these contexts, because of these commitments). It has to be specific enough to resolve the same trade-off the same way twice.
It is not a values poster. It is not a strategy deck. It is the written version of trade-offs leaders have historically kept fuzzy on purpose.
That fuzziness is the actual blocker. Fuzzy commitments let executives mean different things to different audiences and defer hard choices indefinitely. Rubrics require choosing, being specific about the choice, and accepting that the document now governs rather than your judgment in the moment.
Most companies won't do this even when they fully understand it.
The good news: nobody authors a rubric in a vacuum. It accumulates through adjudication. A single trade-off resolved is an expense. The same pattern recognized across three resolutions and codified is an investment that retires a class of future expenses.
Constitution by case law.
What ruins the loop is write integrity. If specialists make exceptions that never get formally reconciled, if multiple people edit against the same document without provenance, if six months of careful calibration gets quietly corrupted by two weeks of uncoordinated edits – then the rubric decays faster than the team can maintain it, and the structure collapses back into meeting-based coordination.
What's a trade-off your team has resolved three different ways in three different cycles, because nobody codified it as precedent?
1
99
May 6
Every async experiment eventually re-invents the standup. Not because people love meetings. But because the PM's positioning doc was written for PMs, the design system was written for designers, and architecture docs were written for engineers.
@jasonfried built an entire company philosophy around eliminating meetings. @shreyas has argued for years that the right meetings are the highest-leverage activity in product. They were both drawing on real evidence — yet both were working around the same constraint.
None of these artifacts were built to be read across disciplines. The execution middle (e.g. spec reviews, design handoffs, cross-functional syncs) was where the translation happened. Live, in a room, expensive, and irreplaceable. You couldn't cut the meeting without cutting the translation.
That's why Fried's approach required careful cultural engineering to make work, and why most teams that tried "fewer meetings" as policy drifted into incoherence. The coupling was real. The artifacts didn't carry the information that the meetings did.
AI changes the coupling, not the aspiration. When AI sits between specialists as a translation layer, the engineer doesn't need to read the design system fluently; they ask their agent what it implies for the component they're building. The PM doesn't parse architecture docs; they ask theirs whether their proposed feature violates a commitment.
The judgment stays with the specialist. The translation moves to a layer that doesn't require a calendar invite.
This has a failure mode. AI translation can silently drop constraints. When it summarizes architecture for the PM without a critical technical commitment that rules out their feature, the work stays deep but drifts out of alignment. Nobody notices for weeks.
Faithful summaries and durable artifact integrity are the difference between coherence and invisible drift. Without them, the meeting comes back – or worse, the incoherence ships.
What can actually go away now: stand-ups, hand-offs, spec reviews, design reviews, cross-functional syncs, and most status meetings. Not from a calendar policy. From the coupling that justified them dissolving.
What stays are:
– Strategy meetings, less frequent and more prepared
– Trust formation between people who haven't built mutual models of each other's judgment
– Novel decisions that have no precedent to resolve against.
That's probably 70-90% of current operational meeting volume, gone because the work moved.
The teams still running heavy meeting schedules in 2027 won't be teams that skipped AI. They'll be teams that bolted AI onto the old org chart and left the coordination layer untouched.
The question isn't how many meetings you've canceled. It's whether the work still needs them.
2
123
May 6
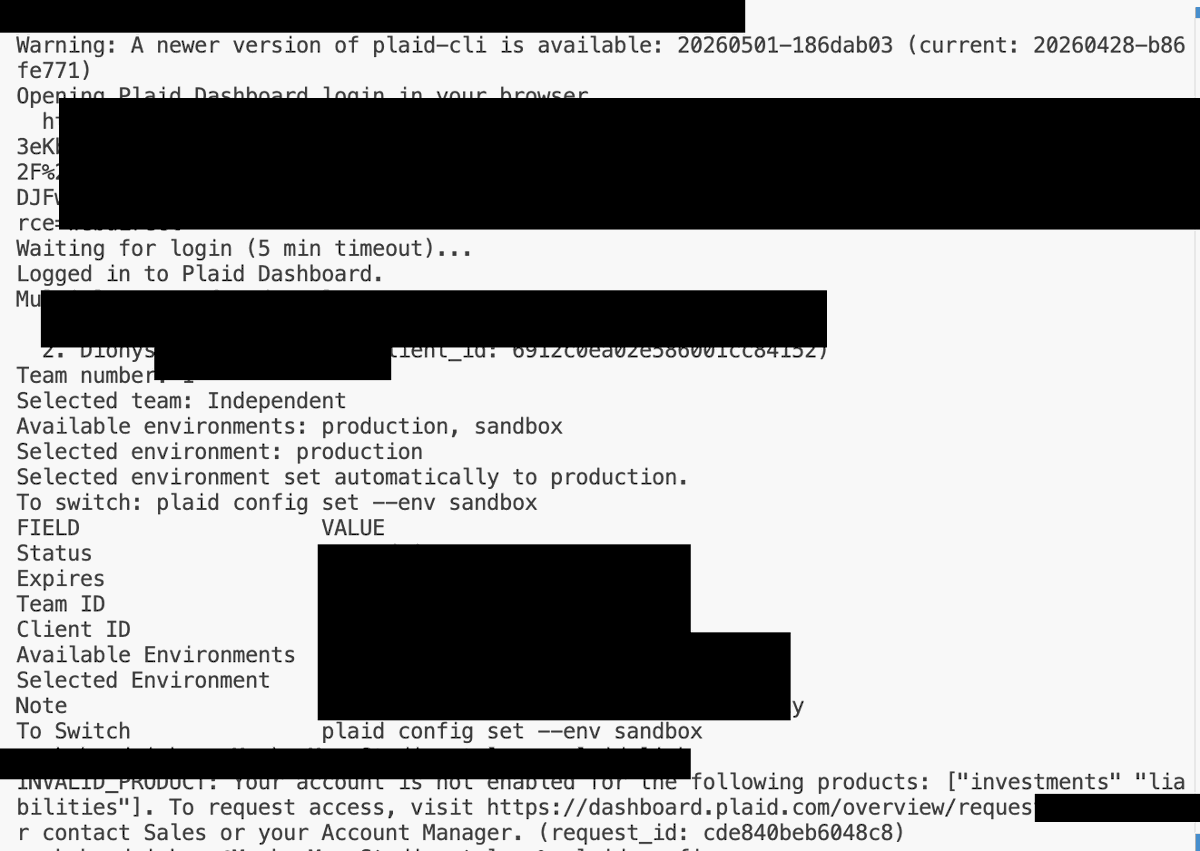
I gave @Plaid's CLI a spin.
But I still can't use it without going through a multi-week business application with manual forms, no transparency, and a human-only process.
Open finance that requires a business application isn't open. And it definitely isn't agent-ready.
Apr 29

This will be a critical tool for open finance if end users can access fully without going through the Plaid application process as "developers".
Going to give it a spin myself soon.
2
2
193
May 5
"Hire slow" versus "hire ahead of the curve." Startup hiring advice has run in two directions for over a decade.
@sama's YC Playbook opens with "my first piece of advice about hiring is don't do it." @eladgil's scaling playbook pushes the opposite: hire ahead, because under-staffing compounds.
Both assume hiring is a response to execution demand. The question was only about timing.
That assumption was correct when execution was expensive. One more engineer roughly doubled throughput. Coordination overhead was a tax on the gains, not an elimination of them.
The "slow-hiring" camp said the tax was bigger than you thought. The "ahead-of-the-curve" one said the tax was smaller than the cost of under-staffing.
When execution collapses to AI, the underlying question changes.
Adding a second engineer doesn't double output, because the engineer you have isn't bottlenecked on execution. They're bottlenecked on the human inputs to execution: foundational artifacts, architectural judgments, review of what AI produced, and strategic calls about what to build next.
A second engineer doesn't parallelize those inputs. They introduce coordination cost on judgment calls one person was making unilaterally and fine.
The hiring trigger is no longer "too much execution work." It is: the attention budget of the current team has been exhausted on AI's inputs and AI's outputs.
That is a specific moment. It is when the single human driving a product can no longer give adequate attention to three loads at once:
1. Authoring foundational artifacts with enough care that AI executes well.
2. Reviewing AI's output with enough density that quality holds.
3. Making the strategic calls that determine what gets built next.
When any one of those three starts getting neglected, you're at the ceiling. The neglect shows up before the throughput drops, which is why teams miss it.
It looks like the founder skimming AI output instead of reviewing carefully. The PM reusing old interview notes instead of doing fresh research. The engineer letting architectural drift accumulate because writing the constraint doc properly would take a week they don't have.
None of these produce immediate failures. Features still ship. Users still use them. But compound quality starts degrading, and the degradation is invisible for months.
Every hire before the attention ceiling is friction without leverage.
How is your team actually deciding when to add people – based on backlog or attention?
2
8
7,154
May 5
Part II of The Human Inversion series is about why the slow-vs-fast hiring debate is asking the wrong question, what the attention ceiling looks like in practice, and the four objections this reframe needs to survive:
markmhendrickson.com/posts/t…
115
Apr 29
Software teams org'ed around execution for decades. PMs wrote specs, designers into mockups, engineers into code. Pre-exec foundational work and post-exec review got whatever time was left over.
Then AI changed the economics. The "middle" is where models are genuinely good now. Execution cost collapsed.
So humans move to the ends. Richer positioning, deeper architecture, and real design systems on one side; comprehensive review on the other. The ends were always where the most leverage lived; we just couldn't afford to staff them.
But removing the human middle also removes the implicit translation that kept disciplines in contact with each other's reality. Coherence has to come from somewhere else now.
I've written a 5-part series on what that all means, exploring:
– Attention scarcity
– Hiring triggers
– Async coordination
– Who and what adjudicates cross-domain conflict
– Data integrity at AI-generated volume
– Where the clean diagram breaks against real teams
All starting with why the shift is economically forced, and what it feels like for the specialists at the center of it.
2
1
104
Apr 29
This will be a critical tool for open finance if end users can access fully without going through the Plaid application process as "developers".
Going to give it a spin myself soon.

We built a CLI so you can do this:
plaid transactions list --json \
| claude -p "how much have I spent on eating out?"
Your real data, 4 commands away. No sandbox data, no SDK, up and running in minutes.
brew install plaid/plaid-cli/plaid
Read more here: medium.com/plaid-engineering…
1
573