
The live data layer for agents and apps
Joined April 2019
- Tweets 606
- Following 44
- Followers 3,065
- Likes 339
109 Photos and videos






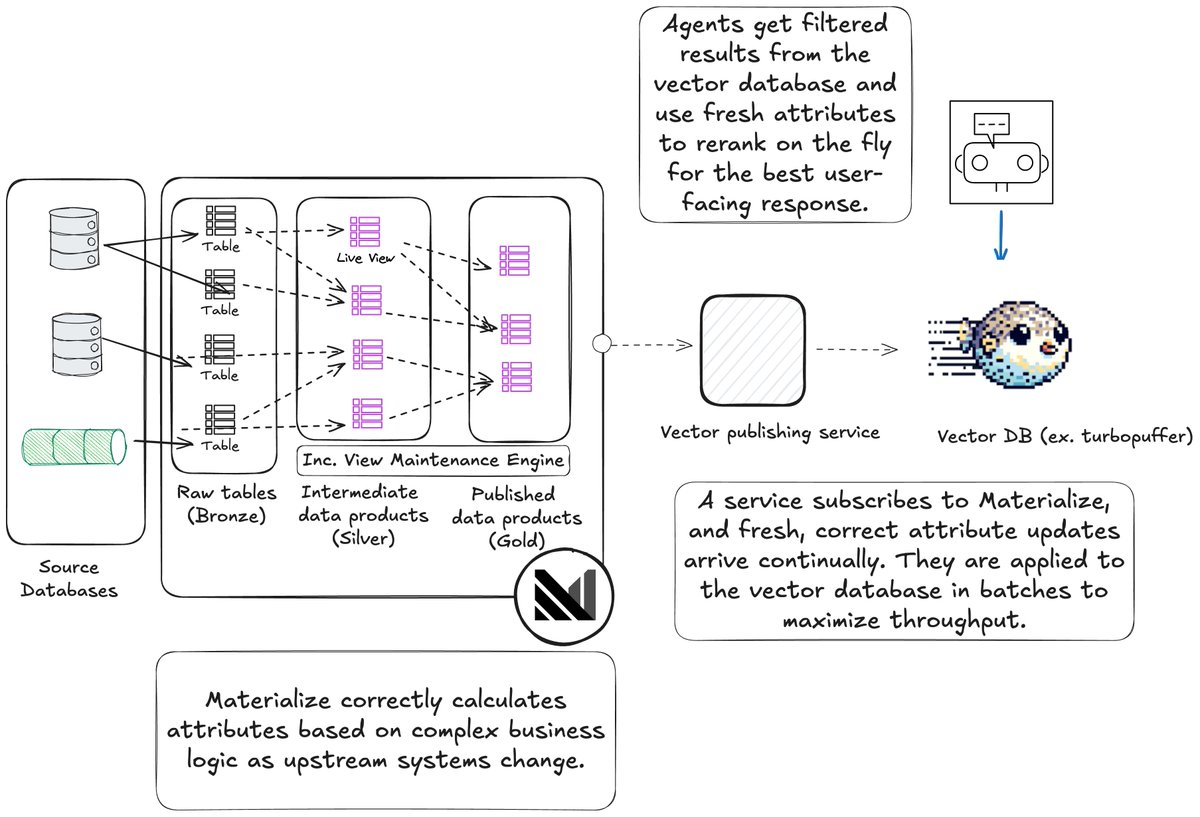








Operational data changes continuously.
Iceberg was designed for batch commits.
Materialize’s new Iceberg sink bridges that gap by delivering transactionally consistent operational data into Iceberg without the memory and latency costs of batching.
Under the hood: logical timestamps, delete semantics, recovery without external state, and the open challenge of multi-table consistency.
If Kappa means compute once and serve everywhere, this is how.
Read more → bit.ly/40pNwqh
1
6
1,193
Agents don’t fail in production because models are bad.
They fail because context is stale, fragmented, or too slow.
See how @Day_ai_app built an agentic CRM, with live context powered by Materialize 🔗bit.ly/4sJLsGu
1
230

20 Nov 2025
Flare's microservices architecture impacted client experience and held back product development.
With Materialize dbt, they built a live data layer across MongoDB, Salesforce, and more—powering sub-second queries and enabling a unified case view, a reliable “My Clients” dashboard, and fast feature computation for AI matching.
Full story: bit.ly/4oaVdtE
1
213
22 Oct 2025
Introducing new Materialize Cloud M.1 Clusters — bigger workloads, better economics, same Materialize.
🚀 3x larger workloads
⚡️ <1s p99 latency
🏎️ Single-digit millisecond query response times
Bigger scale. Better value. Same freshness, responsiveness, and correctness. bit.ly/43zz7cL
1
477
14 Oct 2025
Materialize is heading to the Gartner IT Symposium/Xpo™ next week.
Visit us at Booth #224 to learn how Materialize brings real-time data streaming and analytics to life - transforming how teams build intelligent, responsive applications.
1
256
2 Oct 2025
Operational data products are reshaping how apps & AI consume data.
But should you bet on Materialize or Palantir Foundry
📄 Download the side-by-side comparison: bit.ly/4ol1CTN
238
Materialize retweeted

22 Sep 2025
@MaterializeInc offers a simpler solution. Instead of reactively scanning millions of rows when updates happen, Materialize proactively and correctly maintains live representations of your core business entities as views, shifting computation from query time to write time with ~10ms access to fresh derived data. Push changes as they occur to your vector store.

1
5
367
23 Sep 2025
We’re excited to share that Materialize is hosting the next NYC Institute for Data, Engineering, Architecture, and Standards (IDEAS) Meetup in partnership with @Snowflake.
Join us on September 25th at 5:30 PM ET
hubs.la/Q03KkwBF0
2
456
22 Sep 2025
Vector DBs are useless with stale context.
Materialize keeps attributes fresh with incremental updates—no more costly re-computes, no fragile pipelines.
⚡️ Fresh vectors, simpler stacks. bit.ly/3IamUUJ
1
256
Materialize retweeted

19 Sep 2025
Welcome Frank McSherry @frankmcsherry to Sync Conf 2025. Pioneer of sync technology, inventor of Differential Dataflow, and founder of @MaterializeInc, Frank will trace the evolution of sync and stream processing.

4
13
1,155
18 Sep 2025
🚀 Big release: Materialize now uses swap to scale SQL workloads beyond RAM.
The results:
🏎️ Faster hydration
🚀 Efficient memory utilization
🗂 Larger workloads support
Read @antiguru_de's deep dive → bit.ly/4grbGro
2
4
858
Materialize retweeted

4 Sep 2025
🗣 Shoutout to our #OpenSearchCon silver sponsor @materializeinc. Join us September 8-10 in San Jose, CA to connect with #OpenSearch users, admin, & developers exploring the future of search. Register: hubs.la/Q03Gx8VY0 Schedule: hubs.la/Q03Gx8d00

2
4
443
28 Aug 2025
Live today at 2 PM ET:
[Webinar] Transform SQL Views into Real-Time AI Agent Tools
See how Materialize turns SQL views into callable APIs with strong consistency sub-second freshness.
Register here: hubs.la/Q03FRByS0
182
14 Aug 2025
What happens when Materialize R&D gets a day and a half to build whatever they want?
🔹WASM UDFs
🔹 S3-backed upsert
🔹 Formal verification
🔹 EXPLAIN ANALYZE (now live!)
All from our hackathon 🔗 bit.ly/4oGdXTu
#streamingSQL #databases #rustlang
3
262
13 Aug 2025
Real-time or historical?
Our new guide breaks down how Materialize and ClickHouse solve different data problems — and why you might need both.
Read the full comparison → bit.ly/3Hxt6Wf
#DataEngineering #ClickHouse #Materialize #StreamingSQL #AIInfra
209
11 Aug 2025
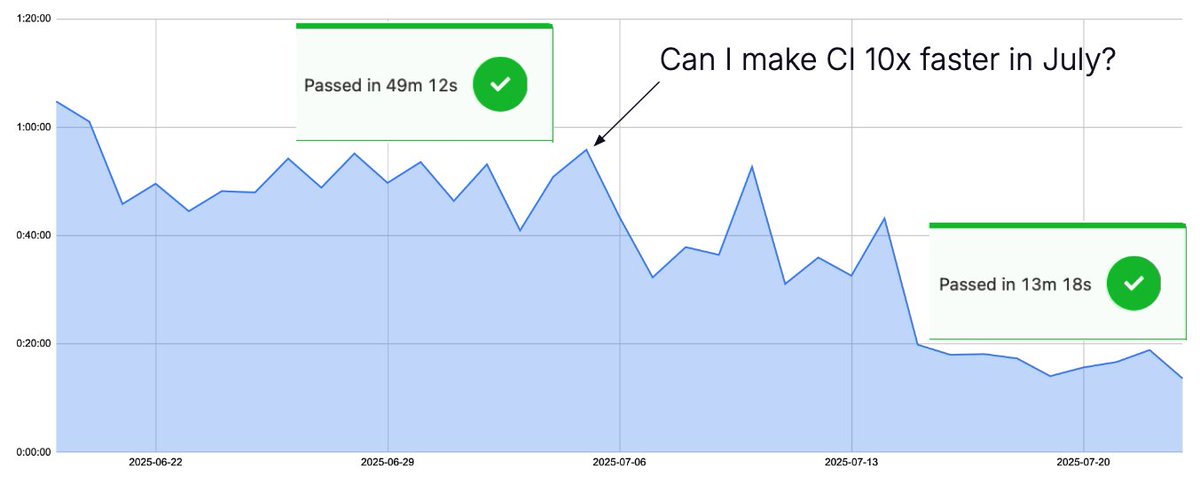
Waiting for CI hurts. In July, we cut our runtime by up to 86%. From 23 min builds to under 2 min, and full runs in as little as 7 min.
Caching, parallelization, smarter builds, and a bit of [libeatmydata] magic.
How we did it🔗 bit.ly/4me14OP
1
1
242
4 Aug 2025
AI agents fail without live context.
A digital twin gives them a real-time, queryable model of your business — built with Materialize & SQL.
Here’s how to make your AI context-aware 🔗 bit.ly/4opA4xm #AI #realtimedata #digitaltwin
1
219
31 Jul 2025
Materialize skips irrelevant data before reading it.
It’s called filter pushdown, and it cuts object store traffic by 50% using stats static analysis.
Faster queries, lower cost. 🔗 bit.ly/4miILr4
1
4
579
17 Jul 2025
Tap into Bluesky’s public firehose, land it in @MaterializeInc, and ask SQL questions on live social data—all in a few lines of code. Walkthrough by @frankmcsherry → bit.ly/3IwGWIJ
#StreamingSQL #Bluesky
1
278
14 Jul 2025
SELECT without limits: Materialize now streams big results out-of-band, freeing the control plane and slashing memory pressure—delivering faster dashboards. Details → bit.ly/4ePXzLp
1
231